运行torchAudio下的wav2vec2.0样例
torchAudio在0.10.0版本中已经兼容了hubert的代码(现在已经0.11.0了)。然而,我连wav2vec2.0的代码都没跑过,官方文档也给出了一个wav2vec2.0代码的运行样例。本人感觉,这不比用fairseq香?fairseq里的代码绕来绕去,无用参数多,缺少关键解释,没有运行示例。看得我是头晕目眩,难顶得一批。(对不起,我是连fairseq中hubert的样例都不知道怎么运行的菜狗)
本文就做个搬运工,讲这个torchAudio官方给的wav2vec2.0的代码样例。如果把相关源码理解完了,再讲里面的具体代码实现。
当然,本人会用自己的理解去跟大家看官方样例,大家也可直接看官方样例的解释可能更为准确。觉得不对可提出。
torchAudio官方样例地址:
https://pytorch.org/audio/stable/tutorials/speech_recognition_pipeline_tutorial.html
样例代码
单元块一
import os
import IPython
import matplotlib
import matplotlib.pyplot as plt
import requests
import torch
import torchaudio
matplotlib.rcParams["figure.figsize"] = [16.0, 4.8]
torch.random.manual_seed(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(torch.__version__)
print(torchaudio.__version__)
print(device)
SPEECH_URL = "https://pytorch-tutorial-assets.s3.amazonaws.com/VOiCES_devkit/source-16k/train/sp0307/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav" # noqa: E501
SPEECH_FILE = "_assets/speech.wav"
if not os.path.exists(SPEECH_FILE):
os.makedirs("_assets", exist_ok=True)
with open(SPEECH_FILE, "wb") as file:
file.write(requests.get(SPEECH_URL).content)
主要工作有:
-
布置画板,主要用来画语谱图
-
检查torch、torchAudio版本,确定跑模型的驱动
-
确定音频下载地址
SPEECH_URL -
确定音频存放位置
SPEECH_FILE如果有本地音频,直接用
SPEECH_FILE记录音频位置就行
输出:
1.11.0+cpu
0.11.0+cpu
cpu
单元块二
创建一个执行特征提取和分类的 Wav2Vec2.0 模型。
bundle = torchaudio.pipelines.WAV2VEC2_ASR_BASE_960H
print("Sample Rate:", bundle.sample_rate)
print("Labels:", bundle.get_labels())
WAV2VEC2_ASR_BASE_960H中主要传入了这些参数:

这些参数就是特征提取和分类模型的参数
bundle 对象提供了实例化模型和其他信息的接口。
主要工作:
创建bundle对象,获取wav2vec2.0的模型参数。如采样率bundle.sample_rate,标签bundle.get_labels
输出:
Sample Rate: 16000
Labels: ('-', '|', 'E', 'T', 'A', 'O', 'N', 'I', 'H', 'S', 'R', 'D', 'L', 'U', 'M', 'W', 'C', 'F', 'G', 'Y', 'P', 'B', 'V', 'K', "'", 'X', 'J', 'Q', 'Z')
单元块三
模型可以如下构建。此过程将自动获取预训练的权重并将其加载到模型中。对,一步就把特征提取和分类的 Wav2Vec2.0 模型搭建好。
model = bundle.get_model().to(device)
print(model.__class__)
输出:
Downloading: "https://download.pytorch.org/torchaudio/models/wav2vec2_fairseq_base_ls960_asr_ls960.pth" to /root/.cache/torch/hub/checkpoints/wav2vec2_fairseq_base_ls960_asr_ls960.pth
0%| | 0.00/360M [00:00
单元块四
IPython.display.Audio(SPEECH_FILE)
这个模块没什么用,就是给你听听音频

单元块五
waveform, sample_rate = torchaudio.load(SPEECH_FILE)
waveform = waveform.to(device)
if sample_rate != bundle.sample_rate:
waveform = torchaudio.functional.resample(waveform, sample_rate, bundle.sample_rate)
主要作用:
要加载数据,我们使用torchaudio.load()。
如果采样率与管道预期的不同,那么我们可以使用torchaudio.functional.resample()重新采样。
单元块六
with torch.inference_mode():
features, _ = model.extract_features(waveform)
主要作用:
从音频中提取声学特征。
单元块七
fig, ax = plt.subplots(len(features), 1, figsize=(16, 4.3 * len(features)))
for i, feats in enumerate(features):
ax[i].imshow(feats[0].cpu())
ax[i].set_title(f"Feature from transformer layer {i+1}")
ax[i].set_xlabel("Feature dimension")
ax[i].set_ylabel("Frame (time-axis)")
plt.tight_layout()
plt.show()
主要作用:
返回的特征是张量列表。每个张量都是变压器层的输出。
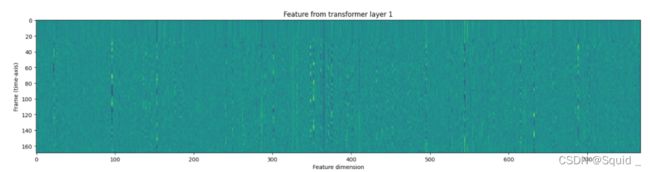
这里就看一张,后面还有12张。
单元块八
一旦提取了声学特征,下一步就是将它们分类为一组类别。
Wav2Vec2 模型提供了一步完成特征提取和分类的方法。
with torch.inference_mode():
emission, _ = model(waveform)
输出是 logits 的形式。它不是概率的形式。
让我们想象一下。
plt.imshow(emission[0].cpu().T)
plt.title("Classification result")
plt.xlabel("Frame (time-axis)")
plt.ylabel("Class")
plt.show()
print("Class labels:", bundle.get_labels())
输出:
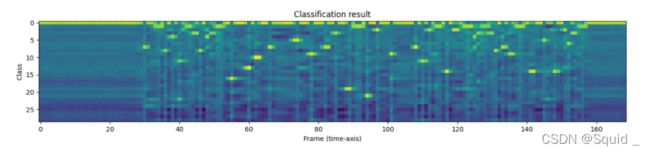
Class labels: ('-', '|', 'E', 'T', 'A', 'O', 'N', 'I', 'H', 'S', 'R', 'D', 'L', 'U', 'M', 'W', 'C', 'F', 'G', 'Y', 'P', 'B', 'V', 'K', "'", 'X', 'J', 'Q', 'Z')
单元块九
从标签概率序列中,现在我们要生成转录本。生成假设的过程通常称为“解码”。
在本教程中,为简单起见,我们将执行不依赖于此类外部组件的贪婪解码,并在每个时间步简单地选择最佳假设。因此,不使用上下文信息,只能生成一份转录本。
我们首先定义贪心解码算法。
class GreedyCTCDecoder(torch.nn.Module):
def __init__(self, labels, blank=0):
super().__init__()
self.labels = labels
self.blank = blank
def forward(self, emission: torch.Tensor) -> str:
"""Given a sequence emission over labels, get the best path string
Args:
emission (Tensor): Logit tensors. Shape `[num_seq, num_label]`.
Returns:
str: The resulting transcript
"""
indices = torch.argmax(emission, dim=-1) # [num_seq,]
indices = torch.unique_consecutive(indices, dim=-1)
indices = [i for i in indices if i != self.blank]
return "".join([self.labels[i] for i in indices])
现在创建解码器对象和解码脚本。
decoder = GreedyCTCDecoder(labels=bundle.get_labels())
transcript = decoder(emission[0])
让我们检查结果并再次收听音频。
print(transcript)
IPython.display.Audio(SPEECH_FILE)
输出:
I|HAD|THAT|CURIOSITY|BESIDE|ME|AT|THIS|MOMENT|
