基于深度学习的篮球比赛战术数据自动采集及统计系统——7流程总线的复现
前言
在完成6个模块的学习后,我们对各个模块对应的工程文件使用已经有所理解,并且能够成功运行各个模块,获取权重文件。现在我将从0开始,以图文的形式复现一遍本人实现篮球比赛战术数据自动采集及统计系统的全部流程。
流程总线
1. 数据集的获取及校验
2. 获取目标检测训练权重文件,训练指标,检测结果
3. 获取多目标跟踪训练权重文件,检测结果
4. 获取行为识别训练权重文件,训练指标,检测结果
5. 综合yolov5+deepsort+slowfast对输入视频分析,实现行为识别及统计结果可视化
流程总线的复现
1.数据集的获取及校验
(1)数据存放策略
作为项目的负责人,汇总组员提供的图片和tempdata.csv文件并且有条理的存放是很重要的。下面是我存放数据集的策略(统一存放在DS文件夹下):
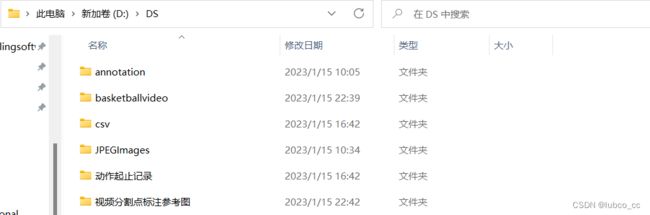
各个文件夹解释:
annotation: 存放了由input.csv原始数据集通过convert_to_xml_ava.py文件转出的所有xml文件。以后训练目标检测和多目标跟踪模型时,将annotation下的xml文件复制到对应的文件夹下即可。
basketballvideo:存放了剪辑后,连续每个24s进攻回合的视频片段,命名格式为‘视频名_编号'
csv:存放了input.csv文件。汇总组员提供的dataframe.csv文件,复制到input.csv文件下,之后按frame_id排序,这样input.csv文件汇总完毕。
JPEGimages:存放了所有截取的要标注的视频帧。建立这个文件夹的好处是,不用在三个模块的图片文件夹下重复导入图片了,可以减少内存占用量,图片路径统一采用这个文件夹的路径。
动作起止记录:存放了每个视频球员动作的起止信息。
视频分割点标注参考图:存放了分割帧的标注图片,用于其他标注人员标注时对比参考
注意:由于图片都统一放在了JPEGimages下,所以要修改调用三个训练模型中的图片位置的路径。
(2) 数据集的校验
为什么要进行数据集的校验呢?在讨论这个问题之前,我们要先明确我们要校验数据集的什么?
校验数据集的什么?:校验图片的摆放顺序是否和xml文件的摆放顺序是否一致。因为一张图片对应一份xml文件,比如1_5.jpg必须有对应的1_5.xml文件,缺失就会引起训练失败。
导致缺失的原因:缺失主要是xml文件的缺失,存在图片却不存在对应的xml文件。导致这个问题的原因在于input.csv文件缺少相应的图片帧的标注信息,在导出xml文件时没能导出。可能是标注人员粗心大意导致图片导出出现遗漏,漏标图片信息等问题导致的。
如何校验?:在模块一数据集构建的步骤中,要首先进行多目标跟踪数据集的crop.py图像切割步骤,如果提示找不到指定xml文件,说明存在xml缺失,需要补全缺失信息(补全策略见crop.py)。如果不报错(或提示最后一个图片帧数+1找不到)那么可以进行目标检测数据集的划分,并且生成的ava文件是可用的。
2. 获取目标检测训练权重文件,训练指标,检测结果
(1)训练yolov5模型,获得best.pt权重文件
经过数据集的摆放,现在我们可以训练yolov5模型,执行D:\yolo_slowfast\yolov5\train.py文件。(注意修改参数信息,如xxx.yaml文件下修改要区分的种类,yolov5s.pt预训练模型)
训练过程展示:
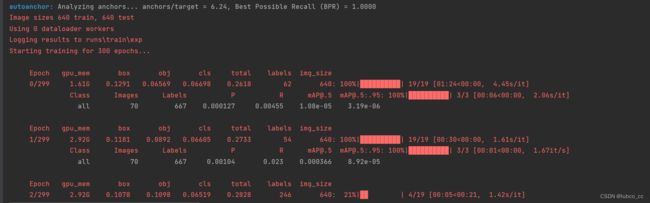
训练权重文件(best.pt):

(2)训练指标
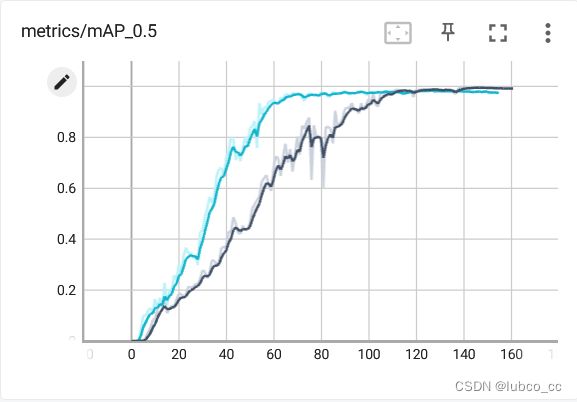
最终map值在0.98左右收敛,所以训练到155代便提前结束(蓝线为本次训练的map变化,黑线是上一次训练的结果)
断点续练的问题可以参考下面两个文章,亲测有效
【深度学习】Yolov5训练意外中断后如何接续训练详解;yolov5中断后继续训练_别出BUG求求了的博客-CSDN博客_yolo暂停训练
YOLOV5-断点训练/继续训练_科研工作者MY008的博客-CSDN博客_yolov5如何继续训练
(3)检测结果
调整detect.py参数,运行D:\yolo_slowfast\yolov5\detect.py文件,查看结果。

3. 获取多目标跟踪训练权重文件,检测结果
(1)训练deepsort模型,得到ckpt.t7权重并查看训练指标
经过数据集的摆放,现在我们可以训练deepsort模型,运行D:\deep_sort\deep_sort_pytorch\deep_sort\deep\train.py文件。(model.py等相关信息需要修改,详情见多目标跟踪模块)
训练过程展示:

训练指标:训练了300个世代,这里只截取到30世代,精确度能达到99.5%左右。
训练权重结果(ckpt.t7):
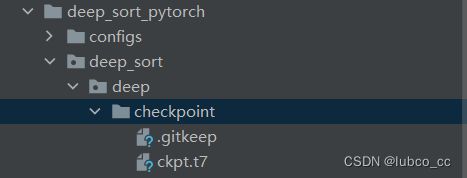
(2)跟踪检测结果
篮球视频分析————多目标检测结果
4. 获取行为识别训练权重文件,训练指标,检测结果
(1)训练slowfast模型,获得xxxx.pyth权重文件
经过数据集的摆放,我们现在可以训练slowfast模型,运行D:\slow_fast\tools\run_net.py文件。
训练过程展示:
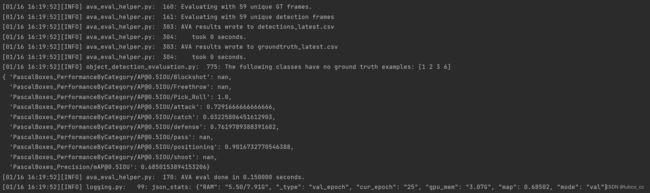
训练指标:map值在0.68左右收敛(这是标注了362张图片的结果)
训练权重文件(训练了75个世代,前74个删除了):

(2) 检测结果
运行demo文件,进行视频的行为识别,结果如下
篮球战术采集——行为识别检测结果
5. 综合yolov5+deepsort+slowfast对输入视频分析,实现行为识别及统计结果可视化
前言提要:
本方法的创新思路如下:
FAIR的pytorchvideo框架结合目标检测和行为分类(Faster R-CNN+SlowFast)实现了行为检测,不过pytorchvideo框架下的目标检测框架是其自带的detectron2工具下的Faster R-CNN,速度较慢,且行为检测是不连续的(其将视频分为一小段clip,分别进行行为检测,没有追踪),基于此,我们进行了以下两点改进:
- 利用yolov5替代原生的Faster R-CNN,达到基本实时的处理速度
- 利用追踪,将物体前后类别联系起来,行为类别信息更加饱满(行为类别从离散到连续)
参考文章:Yolov5+SlowFast: 基于PytorchVideo的实时行为检测算法 - 知乎
(1)综合yolov5+deepsort+slowfast实现视频行为识别(运行具体流程参考前文对应模块)
运行过程如下:
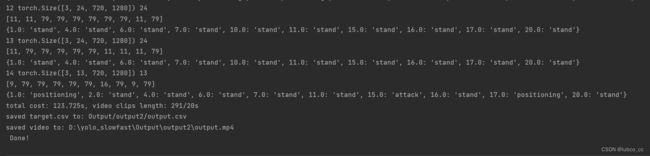
运行解释:
13 torch.Size([3, 24, 720, 1280]) 24
[11, 79, 79, 79, 79, 79, 11, 11, 11, 79]
{1.0: 'stand', 4.0: 'stand', 6.0: 'stand', 7.0: 'stand', 10.0: 'stand', 11.0: 'stand', 15.0: 'stand', 16.0: 'stand', 17.0: 'stand', 20.0: 'stand'}第一行:视频的秒数,torch的尺寸,每秒多少帧
第二行:球员的动作id号
第三号:球员的track_id和动作
yolov5+deepsort+slowfast实现视频行为识别结果如下:
篮球视频分析yolov5+deepsort+slowfast
(2)分析行为识别视频,统计篮球战术数据指标,实现结果可视化
演示视频如下:
篮球战术数据自动采集界面
总结
以上,本个项目的全部流程均已复现完毕。现在的目标就是优化算法与网络,并且能够扩充好自己的数据集,综合yolov5+deepsort+slowfast能够准确的识别自己定义的篮球动作从而进行指标统计。