博弈对抗游戏AI的技术方法的一些总结和思考
目录
一、总体概况
1、博弈类型和算法
1)团队博弈
2)有限零和博弈
3) CFR系列算法
4)NFSP系列算法
2、不同的决策方式
二、不同游戏AI的简单介绍
1、棋盘游戏AI
2、纸牌游戏AI
3、FPS游戏AI
4、RTS 游戏 AI
三、对于游戏AI开发的思考
1、完全信息博弈对抗
2、不完全信息博弈对抗
一、总体概况
1、博弈类型和算法
博弈类型有很多种,根据不同的博弈类型我们可以最快的找到与其相关性最大的算法。博弈中分为标准型博弈和拓展型博弈,其中主要算法又有不同。AlphaGo系列算法适用于棋盘类游戏,而其他游戏为不完全信息博弈,可以考虑使用CFR算法和NFSP算法。具体分类如下:
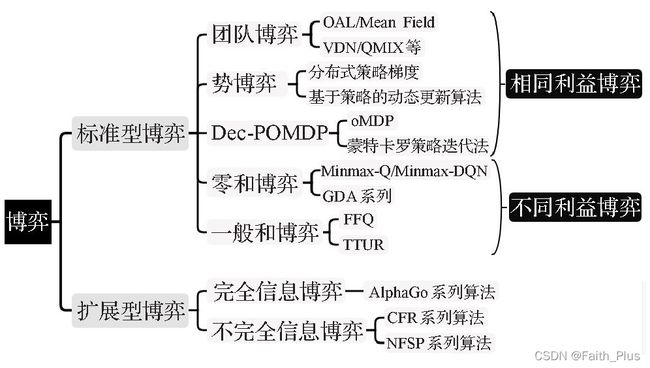
1)团队博弈
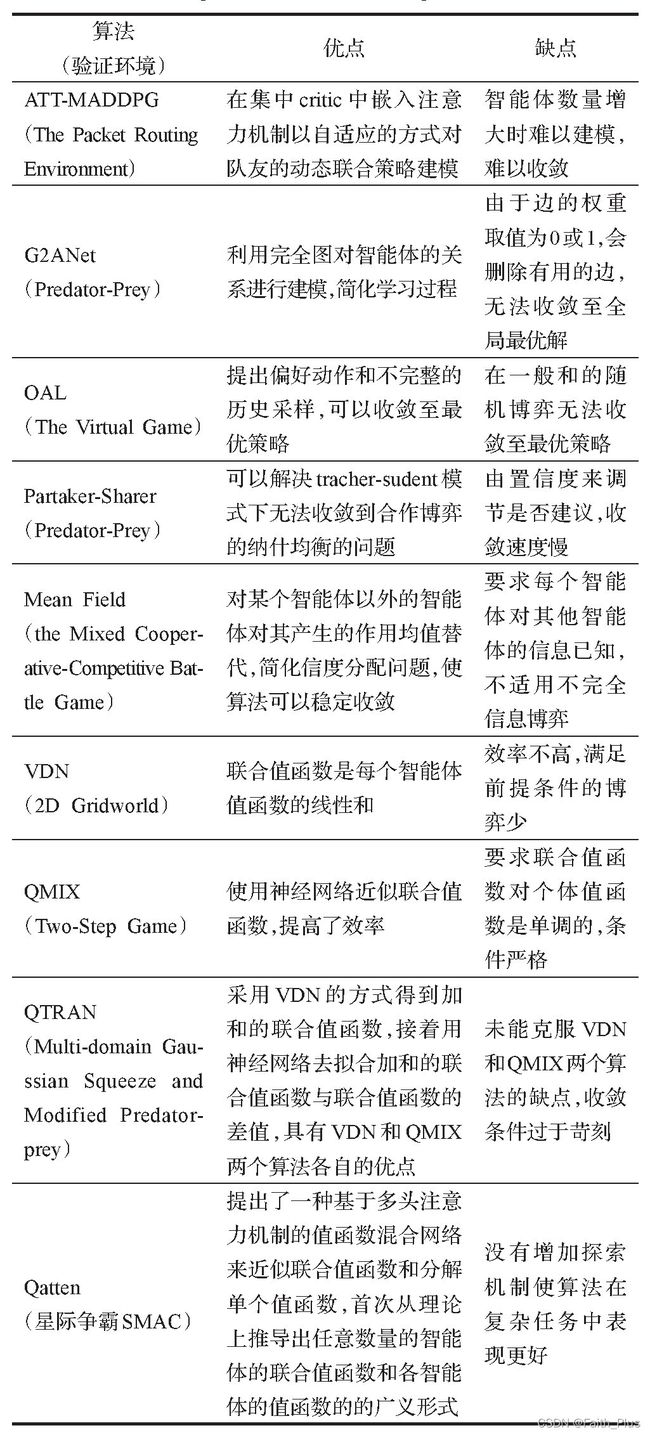
团队博弈中,每个智能体只需要维护自己的值函数,而且值函数只取决于当前的状态和动作,从而避免了考虑联合动作时的环境非平稳和维度爆炸问题。其中团队博弈有主要算法:
2)有限零和博弈
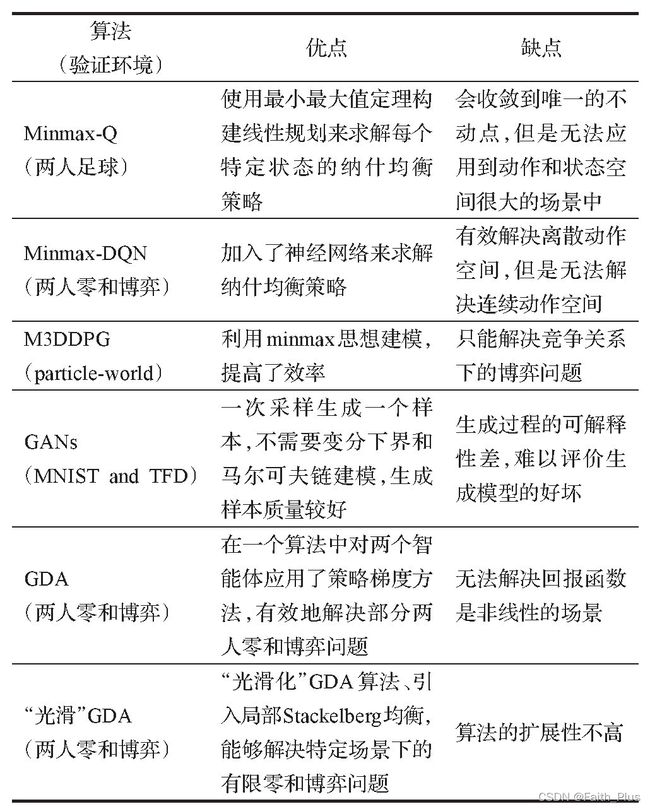
有限零和博弈是指参与博弈的玩家个数有限,并且是严格的竞争关系,所有玩家的总体收益和支出的总和为零。有限零和博弈有主要算法:
3) CFR系列算法
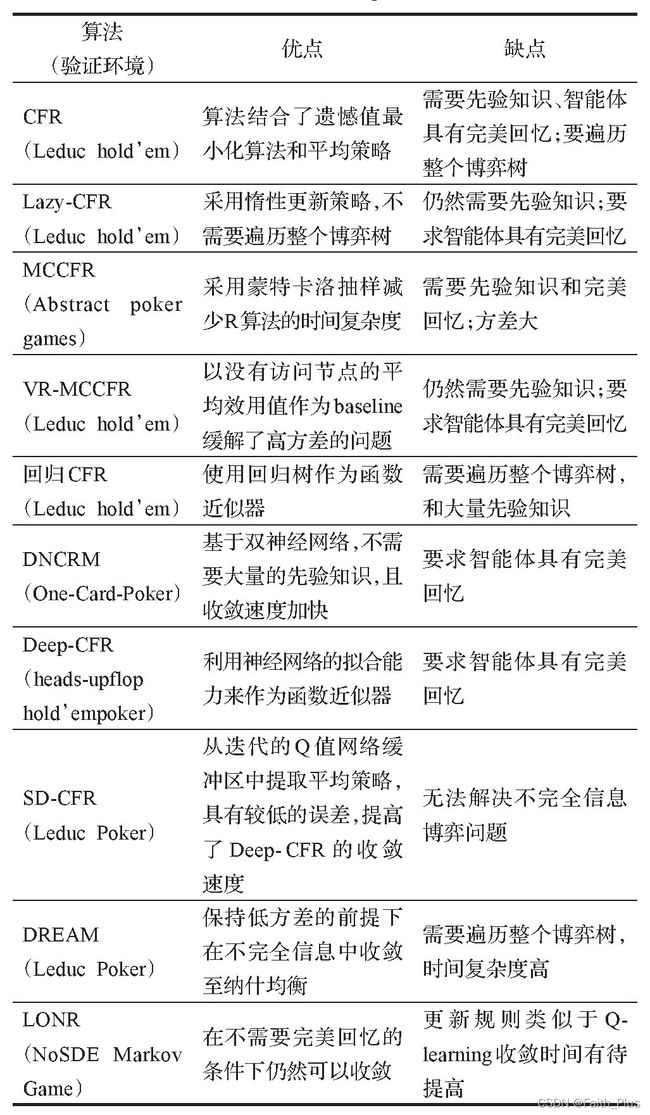
CFR系列有主要算法:
对于CFR有许多AI智能体,其中越向右发展越丰富,如下表:
| 智能AI | ||||
| 名称 | Cepheus | DeepStack | Libratus | Pluribus |
| 概况 | Cepheus首次破解了HUL问题,具有所需计算量少、适合大规模并行化等特点。 | Deep Stack通用算法使用了深度学习自我玩牌,学习策略战胜人类玩家。 | 第一模块,预先对博弈进行动作抽象和手牌抽象,计算蓝图策略。 第二模块,是嵌套子博弈求解算法,基于构建的更细粒度的抽象进行实时求解,求解子博弈的目的是在子博弈中改变策略来提升蓝图策略。 第三模块,是一个自我改进模块,随着时间的推移不断改进蓝图策略,利用所发现的对手策略中的潜在漏洞部分,计算出更接近纳什均衡的策略。 |
Pluribus的目标不是一个具体的博弈论概念,而是从实验层面解决多人扑克问题。 |
| 用到的技术流程 | Cepheus采用定点计算和压缩的方式解决存储问题,结合剪枝和省略对平均策略的计算突破CFR算法在计算规模上的限制; 跳过计算和存储平均策略的步骤,使用玩家的当前策略作为CFR+的解; CFR通常只对博弈树的一部分进行采样,以便在每次迭代时进行新。 CFR在每个信息集上使用遗憾匹配的变体,其遗憾值被限制为非负数。 |
Deep Stack使用神经网络拟合评估函数、近似反事实后悔值。 该深度反事实价值网络(以当前迭代的公开状态和范围、池底大小等手牌簇作为输入,特征经过7层全连接的隐藏层输出后归一化处理,从而保证该值满足零和约束,最后映射为两个玩家的反事实后悔值。 在比赛之前,通过生成随机扑克场景(底池大小、台面上的牌和范围)来训练深度反事实价值网络。 |
Libratus首先针对大规模博弈树进行抽象压缩,然后使用了CFR的变体MCCFR算法来计算蓝图策略。同时,Libratus通过一种基于遗憾值修剪法的采样方式改进了MCCFR,允许修剪掉在博弈树中“失败”的分支,以便加快MCCFR算法的收敛。 Libratus利用安全子博弈求解技术确保了策略的可利用性不高于蓝图策略,保证了无论对手使用何种策略,Libratus都能通过确保子博弈策略符合原始抽象的蓝图策略来实现这一点。 |
Pluribus采用全新的在线搜索方法,通过搜索前面的几个博弈路径,来评估自己下一步可选的策略。 Pluribus具有更快的自我博弈算法。在线搜索算法和自我博弈算法的更新与结合,使Pluribus能用比Libratus更少的处理能力和内存来进行训练。Pluribus策略的核心是通过自博弈来计算的。在自博弈中,AI对自己的副本进行博弈,而不需要任何人类或先前的人工智能博弈的数据作为输入。从零开始随机采取动作,并随着确定是哪些动作以及这些动作的概率分布而逐渐改进,从而相对于早期版本的策略产生更好的结果。 Pluribus改进MCCFR进行自博弈,通过自博弈为整个离线博弈生成蓝图策略。人工智能从完全随机对抗开始,通过学习击败自己的早期版本而逐渐改进。 当决策点的数量足够少时,Pluribus会进行实时搜索,以确定针对当前情况更好、更细粒度的策略。 |
| 效果 | CFR+算法在较弱意义上破解了HULTH,这是不完美信息博弈中的里程碑事件。 | 该方法在理论上有两人零和博弈的收敛性证明作为支撑,并且在实践中能得出比之前的方法更低的可利用性。 | ||
在CFR中有很多关键技术,其中较为重要的是对手建模和对于不同策略的求解方法,经过整理得到如下的表格:
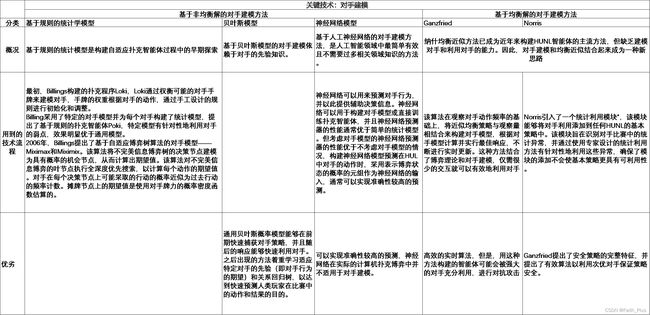

4)NFSP系列算法
虚拟对弈(Fictitious Play)是根据对手的平均策略做出最佳反应来求解纳什均衡的一种算法,重复迭代后该算法在两人零和博弈、势博弈中的平均策略将会收敛到纳什均衡。 NFSP系列有主要算法:
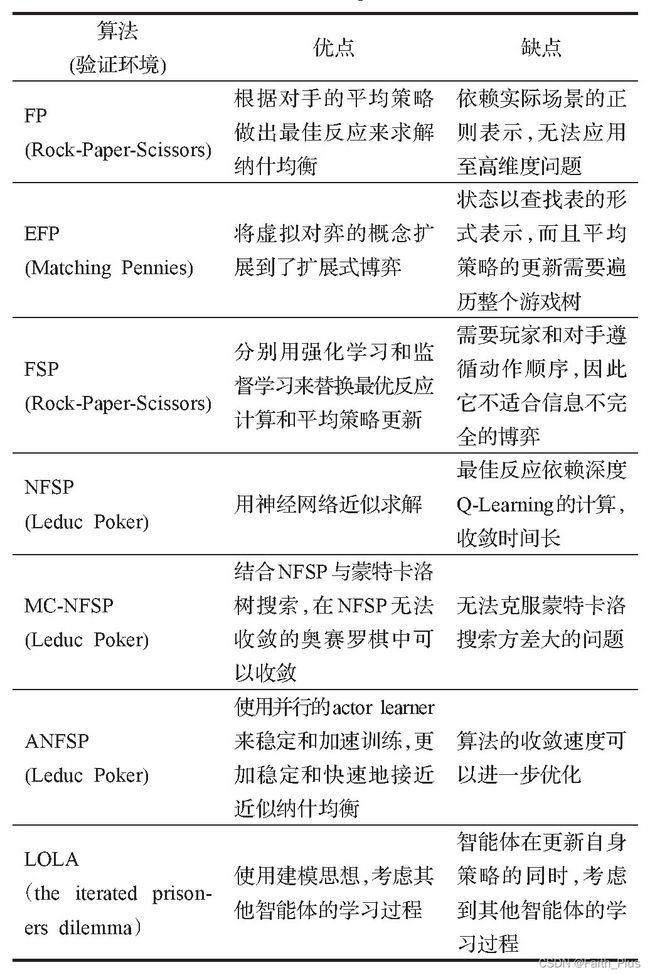
以德州扑克为代表的非完全信息扩展式博弈虽然在CFR和NFSP系列算法下取得了突破性的进展,但是远没有彻底解决非完全信息扩展式博弈,非完全信息扩展式博弈仍然是深度强化学习后续突破的重难点。要想解决这类问题可能首先需要解决两个问题:一是如何量化非完全信息下的信息的不确定性,环境的非平稳性;二是如何科学高效解决多智能体之间的沟通、协作问题。
2、不同的决策方式
对于智能体决策方面。决策方法有很多种,下图为不同类别的决策方法和其典型模型、优缺点。

此部分内容参考文献:
[1]杜康豪,宋睿卓,魏庆来.强化学习在机器博弈上的应用综述[J].控制工程,2021,28(10):1998-2004.DOI:10.14107/j.cnki.kzgc.20200033.
[2]王军,曹雷,陈希亮,赖俊,章乐贵.多智能体博弈强化学习研究综述[J].计算机工程与应用,2021,57(21):1-13.
[3]陈希亮,李清伟,孙彧.基于博弈对抗的空战智能决策关键技术[J].指挥信息系统与技术,2021,12(02):1-6.
[4]袁唯淋,廖志勇,高巍,魏婷婷,罗俊仁,张万鹏,陈璟.计算机扑克智能博弈研究综述[J].网络与信息安全学报,2021,7(05):57-76.
二、不同游戏AI的简单介绍
主要分类为四种游戏模式:棋盘游戏AI、纸牌游戏AI、FPS游戏AI、RTS游戏AI。
1、棋盘游戏AI
在MCTS树的基础上增加策略、价值神经网络,从而得到此类开放信息的离散最优解,只要能得到完全模拟器,就可以使用AGZ算法(树搜索模式)。
———————————————————————————————————————————
AlphaGo是最基础的一个游戏AI,因此主要了解AlphaGo的基本原理。简单概括为:
由于状态空间极其复杂,因此直接采用MCTS不再适用。
在MCTS的框架下引入两个卷积神经网络policy network和value network以改进纯随机的Monte Carlo模拟,并借助监督学习和强化学习训练这两个网络。
结合AlphaGo讲解MCTS
https://blog.csdn.net/weixin_39878297/article/details/85235694
深度解读 AlphaGo 算法原理
传统的MCTS算法的局限性在于,它的估值函数或是策略函数都是一些局面特征的浅层组合,往往很难对一个棋局有一个较为精准的判断。
为此,AlphaGo的作者训练了两个卷积神经网络来帮助MCTS算法制定策略:用于评估局面的value network,和用于决策的policy network。(这两个网络的主要区别是在输出层:前者是一个标量;后者则对应着棋盘上的一个概率分布。)
首先,Huang等人利用人类之间的博弈数据训练了两个有监督学习的policy network:pσ(SL policy network)和pπ(fast rollout policy network)。后者用于在MCTS的rollouts中快速地选择策略(快速走子)。
接下来,他们在pσ的基础上通过自我对弈训练了一个强化学习版本的policy network:pρ(RL policy network)。与用于预测人类行为的pσ不同,pρ的训练目标被设定为最大化博弈收益(即赢棋)所对应的策略。
最后,在自我对弈生成的数据集上,Huang等人又训练了一个value network:vθ,用于对当前棋局的赢家做一个快速的预估。
AlphaGo总的来说是通过监督学习——自训练得到强化学习版本——训练得到价值网络。
———————————————————————————————————————————
其后发展的AlphaGo Zero和AlphaGo最大的区别是,它不再需要人类数据。也就是说,它一开始就没有接触过人类棋谱。研发团队只是让它自由随意地在棋盘上下棋,然后进行自我博弈。
AlphaGoZero仅用了单一的神经网络。在此前的版本中,AlphaGo用到了“策略网络”来选择下一步棋的走法,以及使用“价值网络”来预测每一步棋后的赢家。而在新的版本中,这两个神经网络合二为一,从而让它能得到更高效的训练和评估。
AlphaGo Zero的核心思想是:MCTS算法生成的对弈可以作为神经网络的训练数据。
总的来说AlphaGoZero利用蒙特卡洛树搜索建立一个模型提升器且只是用一个由policy network和value network共享参数形成的神经网络
AGZ算法本质上是一个最优化搜索算法,对于所有开放信息的离散的最优化问题,只要我们可以写出完美的模拟器,就可以应用AGZ算法。
———————————————————————————————————————————
2、纸牌游戏AI
核心为CFR算法。
———————————————————————————————————————————
deepstack中采用的方案是CFR+“直觉”,也就是类似于Alphago的估值函数,并不搜索到最终局,在树发展到一定深度就进行截断评估。
Deep Stack 的re-solving需要保留自己的range和对手的遗憾值这两个值。不保留记忆,采用局部搜索,将游戏分成一个个的子博弈,这样是为了省空间且加速算法。
deepstack核心是subgame。subgame就是将不能拆解的非完美信息博弈安全的拆解为一个个小游戏,并且要保证小游戏求解的可利用度低于原来的策略(可利用度越低越好)。sungame就是将游戏分成一个T和一个F,并保存对手的原来策略的遗憾值为RT,F是子博弈,对手的遗憾值为RF。每次更新子博弈后F会更新RF,如果RF的大于RF,则不更新;如果RF的小于RF,则将F的策略保存为T,然后继续改进F。这样能保证可利用度是一直降低的。
德州扑克AI的DeepStack算法
DeepStack算法笔记
DeepStack就是将整个游戏根据re-solving思想分解为子博弈(必须有自己的range和对手的遗憾值两个参量),根据子博弈的规则向下扩展,通过网络返回的V值根据CFR+算法更新遗憾值。
———————————————————————————————————————————
Libratus使用的基于博弈论的方法是独立于应用场景的,包括三个策略模块:一个计算蓝图全局策略的算法,一个在游戏过程中充实子游戏策略的算法,和一个用来修正对手发现我们在蓝图策略里潜在的弱点的自我优化算法。
其解释为求解纳什均衡
蓝图全局策略:对下注尺度做简化、MCCFR算法全名是蒙特卡洛反事实后悔最小化算法。
子游戏策略:这个模块的作用是,根据前一天对手的行动,把没出现在蓝图策略的尺度添加进去,起到补漏的作用。
Libratus-简介
———————————————————————————————————————————
Suphx(Super Phoenix)是一个主攻4人日本麻将的AI,主要基于深度强化学习进行训练,除此之外还应用了全局奖励预测(global reward predictction)、先知教练(oracle guiding)以及运行时策略适应(run-time policy adaption)等新技术。
Suphx的学习过程分为三个阶段:
1、通过监督学习训练5个模型:舍牌模型(Discard model)、立直模型(Riichi model)、吃模型(Chow model)、碰模型(Pong model)和杠模型(Kong model)
2、用训练过的模型作为策略来进行self-play,并通过熵正则化分布式强化学习(Distributed Reinforcement Learning with Entropy Regularization)来更新策略。在训练过程中使用了全局奖励预测(global reward predictction)和先知教练(oracle guiding)来处理麻将中特有的困难之处。
3、在online playing过程中使用了运行时策略适应(run-time policy adaption)来针对本局游戏的初始状态进行调整以获得更好的表现。
Suphx:微软麻将AI算法以及Q&A摘要
———————————————————————————————————————————
DouZero 主要使用蒙特卡洛方法。(算法DMC、DQN、CFR)
普通蒙特卡罗方法只能适用于离散情况,因此加入深度神经网络产生深度蒙特卡罗。这个方法也可以看作是只包含Q价值网络的AlphaZero(去掉搜索树和策略网络;这个价值是 Q 价值,而AlphaZero里是状态的价值)。
DouZero斗地主AI深度解析
———————————————————————————————————————————
3、FPS游戏AI
强化学习、超参数自动优化方法PBT(Population Based Training)
———————————————————————————————————————————
4、RTS 游戏 AI
难点一个是不完全信息, 其次是需要远期计划,另外就是实时性与多主体博弈。
———————————————————————————————————————————
AlphaStar 使用通用学习算法,具体如下。
A 强化学习 + 深度监督学习框架
B 马尔可夫 vs 局部马尔可夫决策框架
C 技术细节创新:
- 多任务联合训练。
- 多体博弈问题。
- RNN联合注意力attention框架改进。
- 自回归模型。
- 和人类的成绩比较。
Alpha Star 背后的机器学习原理
AlphaStar的游戏——星际争霸2 AI综述
———————————————————————————————————————————
Commander 作为轻量级的计算版本,遵循 AlphaStar 相同的训练架构
———————————————————————————————————————————
OpenAI Five
1、奖励重塑,通过自己构建小目标奖励来解决Long horizon 和Credit assignments问题。
除了OpenAI采取的奖励重塑解决奖励稀疏问题外,还有好奇心理论,课程学习,ICM,自我博弈,层次强化,模仿学习,以及最近比较热的基于模型的预测规划模型等方法解决奖励稀疏问题。
2、有力武器---自我博弈
博弈研究的问题可以分为:合作博弈和非合作博弈,现代狭义的博弈一般是非合作博弈,OpenAI采用的也是非合作博弈。非合作博弈又可以分为完美信息博弈和非完美信息博弈,显然在Dota里面对手的信息并不是完全可见,因此属于非完美信息博弈,这种非完美信息,在马尔可夫决策过程当中又被称之为部分马尔可夫决策过程。
OpenAI通过自我博弈来最大化短期奖励,学会如何击败对方,而保证自己存活下来。通过自我博弈可以将计算机的算力转化为强化学习所需要的训练数据。
通俗认识理解OpenAI Five
———————————————————————————————————————————
三、对于游戏AI开发的思考
1、完全信息博弈对抗
完全信息的扩展式博弈最大的突破是AlphaGo系列,AlphaGo系列使用蒙特卡洛树搜索的框架进行模拟,并在学习策略时中使用监督学习,有效地利用人类棋手的棋谱,通过强化学习,从左右互搏中提高自己,超越人类棋手水平。
在此方面,完全信息对抗博弈已经非常成熟,因此接下来我们需要深入研究的重点不是这类游戏AI。
2、不完全信息博弈对抗
现实中博弈往往以不完全信息的扩展式博弈存在,如即纸牌游戏和RST游戏,不完全信息的扩展式博弈被认为是下一代人工智能的重难点之一。解决不完全信息的扩展式博弈主要有三个难点:
- 子博弈之间相互关联。
- 存在状态不可分的信息集,这使得强化学习中基于状态的值估计方法不再适用。
- 博弈的求解规模比较大。
博弈论主要是冲突环境下的决策理论,将完善的博弈理论加入到强化学习获得很多了令人惊喜的结果,特别是对于一些无法解决的不完全信息博弈问题,解决上述问题最主要的算法有CFR系列算法和NFSP系列算法。
CFR系列算法存在的主要难点:一是要求智能体具有完美回忆,这在很多实际博弈场景中很难满足;二是算法的收敛性很难保证;三是由于要遍历很多博弈节点,因此需要大量内存空间。
NFSP系列算法存在的主要难点有:一是NFSP系列算法依赖于off-policy的深度Q值网络,因此在搜索规模大、即时策略场景下很难收敛;二是在训练时智能体都是独立更新,没有利用对手的信息;三是NFSP的最佳响应计算依赖于Deep Q-learning,收敛时间长且计算量大。
因此,未来的博弈对抗游戏AI开发主要是这方面的游戏AI开发,并且向着决策快、效果好的方向前进。