长安链Batch交易池生产可用重构方案设计及其成效
引 言
长安链Batch交易池是业内首个生产可用的批量交易池。区块中只需放入批次ID,实现对区块的极致剪裁;通过以批次为单位的交易并发处理机制,进一步提升交易池性能。在一轮共识中(16核/64G,4节点),长安链Batch交易池相较Single交易池性能整体提升32倍,提升区块压缩率至0.23%,并且支持更具扩展性和理论性能更优的MaxBFT共识算法。
一、背景与不足
1、背景
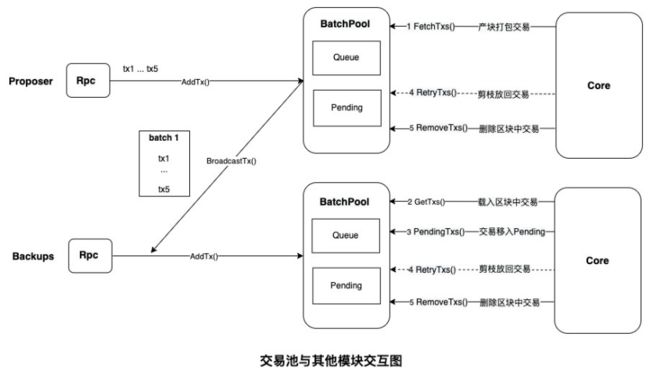
长安链中的批量交易池为了提升性能,在交易池Broadcast交易、主节点产块时从交易池Fetch交易、从节点验证区块从交易池Get交易和验证完将交易移入Pending、以及主从节点在提交区块从交易池Remove区块中交易时,均以批次为粒度进行操作。
点击图片放大
在原来批量交易池的实现中,各节点交易池内部各自维护一个自增的CurrentBatchId,收到其他节点广播过来的Batch后更换为自身的CurrentBatchId。为了以批次为单位对交易进行操作,各节点交易池内部还维护了BatchId->TxId的映射表,从节点Core模块从交易池Get交易时,根据入参TxId检索BatchId,然后将该批次所对应的交易直接返回给Core模块,Pending和Remove操作也是同理。
2、存在的不足之处
按照上述的实现思路,批量交易池存在两个明显不足。
(1)批量交易池无法兼容一笔交易同时发给多个节点,无法生产可用

点击图片放大
如上图所示,如果将5笔交易只发送给一个节点,那个该节点基于收到的交易构造交易批次并广播给其他节点,此时,各个节点交易池的Batch间不存在重复的交易(不考虑接收交易构造批次的节点作恶),在Get、Pending、Remove时,各个节点操作的Batch中的交易是一致的,不存在任何问题。
但是,若将5笔交易同时发给多个节点,各个节点自行构造Batch并广播给其他节点,最终这5笔交易在不同节点大概率会分布在不同的Batch中。在某一轮共识中,假设Node1是主节点,打包Batch1中的交易构造了区块,后续其他从节点在Get和Remove交易时会根据区块中首笔交易的TxId从各自的交易池中找到映射的BatchId,并基于整个Batch进行处理。那么对于Node2来说,最终交易池将会少删除交易tx3,在后续打包的时候,就会重复打包交易tx3;对于Node3来说,将会多删除交易tx4,在后续打包的时候,就会丢失交易tx4;Node4和Node5分别是两种更极端的情况。
(2)批量交易池无法应用于更具扩展性和性能更优的MaxBFT(HotStuff)共识算法

点击图片放大
在交易池中存在两个结构,分别是缓存待打包交易批次的Queue和缓存已打包交易批次的Pending。并且在Pending中也会维护交易批次Batch被打包进的区块高度,用于防止Batch被重复打包进不同的区块。
在MaxBFT共识中,若先收到区块b2并验证有效后,交易池认为Pending中Batch1被打包进了高度为2的区块,但是后续在另外一条分支收到了区块b2'和区块b3,为了使得区块b3验证成功,只能对区块b2剪枝。
由于MaxBFT共识的3-chain机制,该节点在验证完区块b3后,还可能收到原来分支上的区块b3',在验证区块b3'之前需要先对区块b2验证有效,但此时不会对更高的区块b3进行剪枝,这将导致该节点无法对b2<-b3'<-b4 这条分支上的区块进行有效的验证,如果其他大多数节点最终对该条分支形成了3-chain,提交了区块b2,那么该节点会卡在下面的b2'<-b3分支,无法继续参与共识。
二、批量交易池重构方案
针对上述不足,在此次批量交易池重构前,我们制定了如下总体原则:
(1)坚持交易池所有的操作(Broadcast、Fetch、Get、Pending、Retry、Remove)均以批次为粒度进行并行处理;
(2)既然所有操作均以批次为单位进行,那么可以将区块进行极致剪裁,区块中只需放入BatchId即可,无需放入实际交易;
(3)在交易不重复发给多个节点的理想情况下性能最佳,非理性情况下底链稳定运行且不重复打包交易、不丢失交易;
(4)可应用于更具扩展性和理论性能表现更优的MaxBFT共识算法。
1、兼容交易发给多节点的生产可用优化
为了能够兼容交易可重复发给多个节点,我们重新设计了BatchId,使其具有全局一致性和唯一性,并且节点在构造批次时还需要对Batch进行签名。新的BatchId计算规则如下:
BatchId(24字节) = Timestamp(8字节)+NodeId(后8字节)+BatchHash(后8字节)
-
通过BatchId和NodeId绑定,可实现一笔交易发送给多个节点;
-
通过BatchId和BatchHash绑定,可以防止节点作恶,防止向不同节点广播BatchId相同但包含不同交易的批次;
-
通过对Batch进行签名,可以防止节点冒充其他节点构造Batch;

点击图片放大
通过该方案,前文提到的5笔交易发给5个共识节点后,各个节点各自构造Batch导致各Batch中交易不一致的问题将会得到解决。因为所有的交易批次均以全局一致的BatchId进行唯一标识,那么每个节点将会拥有全量的10个批次(其实是8个,因为不会构造不包含交易的批次)。此外,不同的批次之间可能存在重复的交易,所以Core模块从交易池Fetch、Get时,交易池内部会对不同批次间重复的交易进行过滤,确保给到外部的交易不会重复。
2、区块极致剪裁及可靠性优化
因为交易已经按照Batch在交易池模块进行了广播,所以主节点在构造区块时,无需将交易再放入区块体中进行二次广播,并且重构后的批量交易池中的BatchId具有全局唯一性,可以基于BatchId检索出所需要的交易。
所以,主节点在构造区块时只需要将BatchId放入区块的扩展字段Block.AdditionalData中即可,此外由于调度后的交易顺序与交易池取出时的交易顺序可能不一致,还需要将两者之间的映射放入扩展字段中。对应的从节点需要从交易池取出所有BatchId所对应的交易,并按照映射对区块体中的交易进行恢复。

点击图片放大
在网络条件良好的情况下,各个节点交易池的状态基本是全局一致的,节点拥有同样的交易批次。但是,为了增加从节点恢复区块的可靠性,交易池也增加了对缺失交易批次的主动拉取机制,从节点发现缺失某些交易批次时,可以向主节点进行请求,主节点收到请求后会向请求节点响应其缺失的交易批次。
通过对区块进行可靠的极致剪裁,压缩了区块尺寸,这不仅可以减少区块序列化和反序列化的耗时,也在广播提案时减少了对主节点出口带宽的占用。
3、兼容3-chain特性的MaxBFT共识算法优化
为了兼容具有3-chain特性的MaxBFT共识,整链优化了正在共识中的区块间交易防重机制和区块剪枝方案。
通过对正在共识中的区块间交易防重机制进行优化,不再通过Batch是否被打包进某一具体高度区块进行判断,而是通过Batch是否被打包进同一分支的不同区块中进行判断。因为在MaxBFT共识模式下,最终只会在一个分支上形成3-chain进行区块提交,所以同一个Batch是可以被打包进不同分支的区块中。
通过对区块剪枝逻辑进行优化,不会在验证区块时就对旁枝区块进行剪枝,而是在形成3-chain对区块b2提交时,才对旁枝进行剪枝,剪枝逻辑也更加清晰。

点击图片放大
此外,因为在不同的Batch间有可能存在相同的交易,所以在MaxBFT共识模式下,主节点构造区块打包交易时还需要与前置未提交区块中的交易进行防重过滤。假设前置未提交的区块b2' 中包含 Batch_0[tx1, tx4, tx5],那么在获取Batch_1[tx1, tx2, tx3]后,发现存在一笔重复的交易tx1时,Core模块会让批量交易池基于tx2、tx3重新构造一个新的批次Batch_3[tx2, tx3],并基于新的批次重新打包交易。
三、测试与分析
1、性能测试
以16核64G的腾讯云服务器为测试环境,对Single、Normal、Batch三种交易池的主要操作方法进行了性能测试。其中Fetch是构造区块时从交易池获取交易或批次的时间,Cache是开启区块剪裁模式主节点缓存Fetch的交易或批次的时间,Get是从节点从交易池载入区块中交易的时间,AddToPending是从节点将交易或批次移入Pending的时间,Remove是共识完成后交易池删除交易或批次的时间。

点击图片放大
总体上看,Single交易池在一轮共识中占用49.4ms,Normal交易池占用13.95ms,Batch交易池只占用1.52ms。所以,Batch交易池较Single交易池,整体性能提升近32倍。
2、区块压缩率分析
我们按照标准测试条件下,1个区块中包含10000笔 Payload为1KB大小的交易,1个Batch包含100笔交易进行计算。
区块头约250B,未进行区块剪裁时,区块体约为1w * 1KB=10MB,在区块剪裁时,区块扩展字段为100 * 24B + 1w*2B=22.24KB,包括了BatchId和映射。
所以,在Batch交易池进行极致区块剪裁模式下,区块压缩率至(250B+22.24KB)/(250B+10MB)= 0.23%.