Self-Attention 及Multi-Head Attention
Transformer是2017年Google在Computation and Language上发表的,当时主要是针对自然语言处理领域提出的(之前的RNN模型记忆长度有限且无法并行化,只有计算完  时刻后的数据才能计算
时刻后的数据才能计算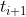 时刻的数据,但Transformer都可以做到)。在这篇文章中作者提出了Self-Attention的概念,然后在此基础上提出Multi-Head Attention。
时刻的数据,但Transformer都可以做到)。在这篇文章中作者提出了Self-Attention的概念,然后在此基础上提出Multi-Head Attention。
self-attention或者transformer的相关资料,基本上都是贴的原论文中的几张图以及公式

Self-Attention
假设输入的序列长度为2,输入就两个节点  ,
,  ,然后通过Input Embedding也就是图中的 f(x) 将输入映射到
,然后通过Input Embedding也就是图中的 f(x) 将输入映射到 ,
,  。紧接着分别将 , 分别通过三个变换矩阵
。紧接着分别将 , 分别通过三个变换矩阵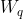 ,
, 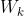 ,
, 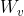 (这三个参数是可训练的,是共享的)得到对应的
(这三个参数是可训练的,是共享的)得到对应的 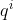 ,
, 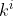 ,
, 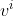 (这里在源码中是直接使用全连接层实现的,这里为了方便理解,忽略偏执)。
(这里在源码中是直接使用全连接层实现的,这里为了方便理解,忽略偏执)。

其中
- q 代表query,后续会去和每一个k 进行匹配
- k 代表key,后续会被每个q 匹配
- v 代表从a 中提取得到的信息
- 后续q 和k 匹配的过程可以理解成计算两者的相关性,相关性越大对应v 的权重也就越大
假设=![]() , =
, =![]() , =
, =![]() 那么:
那么:
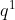 =
=![]()
![]() =
= ![]()
![]() =
= ![]()
![]() =
= ![]()
Transformer是可以并行化的,所以可以直接写成:
![]()
![]()
同理我们可以得到![]() 和
和![]() ,那么求得的
,那么求得的![]() 就是原论文中的Q ,
就是原论文中的Q ,![]() 就是K ,
就是K , ![]() 就是V 。接着先拿和每个k进行match, 点乘操作,接着除以
就是V 。接着先拿和每个k进行match, 点乘操作,接着除以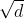 得到对应的α ,其中d代表向量的长度
得到对应的α ,其中d代表向量的长度
,在本示例中等于2,除以的原因在论文中的解释是“进行点乘后的数值很大,导致通过softmax后梯度变的很小”,所以通过除以来进行缩放。比如计算![]() :
:
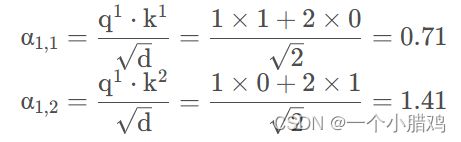
同理拿![]() 去匹配所有的k能得到
去匹配所有的k能得到![]() ,统一写成矩阵乘法形式:
,统一写成矩阵乘法形式:

接着对每一行即 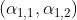 和
和![]() 分别进行softmax处理得到
分别进行softmax处理得到 ![]() 和
和 ![]() ,这里的
,这里的 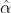 相当于计算得到针对每个 v 的权重。 到这我们就完成了
相当于计算得到针对每个 v 的权重。 到这我们就完成了 ![]() 公式中
公式中![]() 部分。
部分。
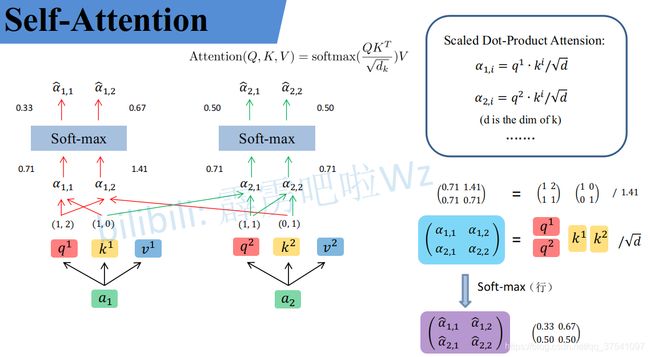
上面已经计算得到 ,即针对每个v的权重,接着进行加权得到最终结果:
,即针对每个v的权重,接着进行加权得到最终结果:

统一写成矩阵乘法形式:

到这,Self-Attention的内容就讲完了。总结下来就是论文中的一个公式:
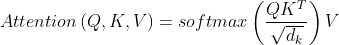
Multi-Head Attention
刚刚已经聊完了Self-Attention模块,接下来再来看看Multi-Head Attention模块,实际使用中基本使用的还是Multi-Head Attention模块。原论文中说使用多头注意力机制能够联合来自不同head部分学习到的信息。Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.其实只要懂了Self-Attention模块Multi-Head Attention模块就非常简单了。
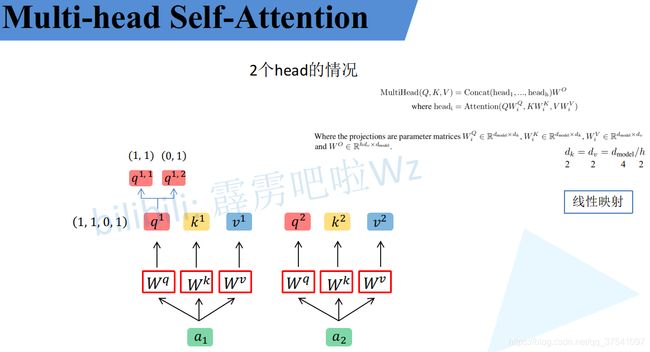
首先还是和Self-Attention模块一样将 分别通过
分别通过![]() 得到对应的
得到对应的![]() ,然后再根据使用的head的数目h进一步把得到的
,然后再根据使用的head的数目h进一步把得到的![]() 均分成h份。比如下图中假设h = 2 然后
均分成h份。比如下图中假设h = 2 然后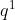
拆分成 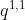 和
和![]() ,那么就属于head1,
,那么就属于head1, ![]() 属于head2。
属于head2。
论文中不是写的通过![]() 映射得到每个head的
映射得到每个head的![]() 吗
吗
![]()
在github上看的一些源码中就是简单的进行均分,其实也可以将![]() 设置成对应值来实现均分,比如下图中的Q通过
设置成对应值来实现均分,比如下图中的Q通过 ![]() 就能得到均分后的
就能得到均分后的![]() 。
。

通过上述方法就能得到每个![]() 对应的
对应的![]() 参数,接下来针对每个head使用和Self-Attention中相同的方法即可得到对应的结果。
参数,接下来针对每个head使用和Self-Attention中相同的方法即可得到对应的结果。
![]()

接着将每个head得到的结果进行concat拼接,比如下图中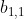 (
(![]() 得到的
得到的 )和
)和 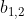 (
(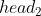
得到的)拼接在一起,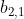 (
(![]() 得到的
得到的 ![]() )和
)和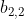 (
(![]() 得到的
得到的![]() )拼接在一起。
)拼接在一起。

接着将拼接后的结果通过 (可学习的参数)进行融合,如下图所示,融合后得到最终的结果
(可学习的参数)进行融合,如下图所示,融合后得到最终的结果![]() 。
。

到这,Multi-Head Attention的内容就讲完了。总结下来就是论文中的两个公式:
![]()
![]()
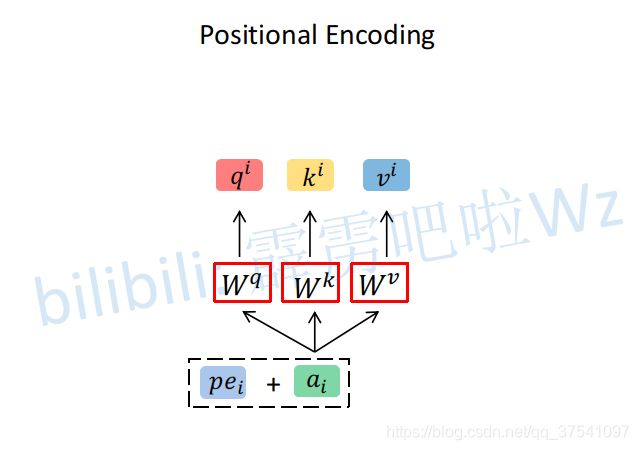
Positional Encoding
如果仔细观察刚刚讲的Self-Attention和Multi-Head Attention模块,在计算中是没有考虑到位置信息的。假设在Self-Attention模块中,输入 ![]() 得到
得到![]() 。对于
。对于 而言,
而言, 和
和 离它都是一样近的而且没有先后顺序。假设将输入的顺序改为
离它都是一样近的而且没有先后顺序。假设将输入的顺序改为![]() ,对结果是没有任何影响的。下面是使用Pytorch做的一个实验,首先使用
,对结果是没有任何影响的。下面是使用Pytorch做的一个实验,首先使用n.MultiheadAttention创建一个Self-Attention模块(num_heads=1),注意这里在正向传播过程中直接传入![]() ,接着创建两个顺序不同的
,接着创建两个顺序不同的 ![]() 变量t1和t2(主要是将
变量t1和t2(主要是将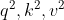 和
和![]() 的顺序换了下),分别将这两个变量输入Self-Attention模块进行正向传播。
的顺序换了下),分别将这两个变量输入Self-Attention模块进行正向传播。
import torch
import torch.nn as nn
m = nn.MultiheadAttention(embed_dim=2, num_heads=1)
t1 = [[[1., 2.], # q1, k1, v1
[2., 3.], # q2, k2, v2
[3., 4.]]] # q3, k3, v3
t2 = [[[1., 2.], # q1, k1, v1
[3., 4.], # q3, k3, v3
[2., 3.]]] # q2, k2, v2
q, k, v = torch.as_tensor(t1), torch.as_tensor(t1), torch.as_tensor(t1)
print("result1: \n", m(q, k, v))
q, k, v = torch.as_tensor(t2), torch.as_tensor(t2), torch.as_tensor(t2)
print("result2: \n", m(q, k, v))
对比结果可以发现,即使调换了 和![]() 的顺序,但对于 是没有影响的。
的顺序,但对于 是没有影响的。
为了引入位置信息,在原论文中引入了位置编码positional encodings。To this end, we add "positional encodings" to the input embeddings at the bottoms of the encoder and decoder stacks.如下图所示,位置编码是直接加在输入的![]() 中的,即
中的,即![]() 和
和![]() 拥有相同的维度大小。关于位置编码在原论文中有提出两种方案,一种是原论文中使用的固定编码,即论文中给出的sine and cosine functions方法,按照该方法可计算出位置编码;另一种是可训练的位置编码,作者说尝试了两种方法发现结果差不多(但在ViT论文中使用的是可训练的位置编码)。
拥有相同的维度大小。关于位置编码在原论文中有提出两种方案,一种是原论文中使用的固定编码,即论文中给出的sine and cosine functions方法,按照该方法可计算出位置编码;另一种是可训练的位置编码,作者说尝试了两种方法发现结果差不多(但在ViT论文中使用的是可训练的位置编码)。