Pandas+Pyecharts | 北京某平台二手房数据分析+可视化
用pandas进行数据处理,pyecharts对处理后的数据进行可视化分析市面上二手房各项基本特征及房源分布情况,探索二手房大数据背后的规律。
Pyecharts的使用参考文档
Pyecharts实例大全
1. 升级 pyecharts 包
地图显示部分需要用到 pyecharts==1.9.0
!pip install --upgrade pyecharts
2. 导入模块
import pandas as pd
from pyecharts.charts import Map
from pyecharts.charts import Bar
from pyecharts.charts import Line
from pyecharts.charts import Grid
from pyecharts.charts import Pie
from pyecharts.charts import Scatter
from pyecharts import options as opts
3. Pandas数据处理
3.1 读取数据
df = pd.read_csv("D:\浏览器下载文件\二手房数据.csv", encoding = 'gb18030')
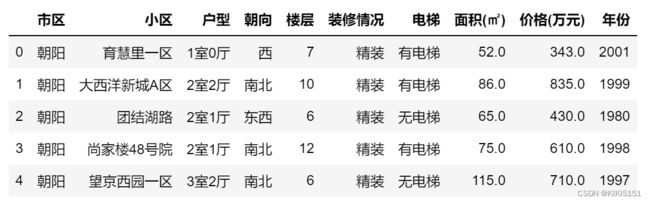
df.head()
输出如下:
df.describe()

3.2数据查看缺失以及填充
查看是否有缺失值:
df.isnull().sum()
用“未知”填充:
df['电梯'].unique()
#output:array(['有电梯', '无电梯', nan], dtype=object)
df['电梯'].fillna('未知', inplace=True)
重复值处理:
df['朝向'].unique()
#output:array(['西', '南北', '东西', '南西', '西南', '东南', '南', '东北', '东', '西北', '北'],dtype=object)
df['朝向'] = df['朝向'].str.replace('南西','西南')
3.3 统计各城区二手房数量
以市区分组统计:
g = df.groupby('市区')
df_region = g.count()['小区']
region = df_region.index.tolist()
#output:region:['东城','丰台','大兴','密云','平谷','延庆','怀柔','房山','昌平','朝阳','海淀','石景山','西城','通州','门头沟','顺义']
count = df_region.values.tolist()
输出df_region
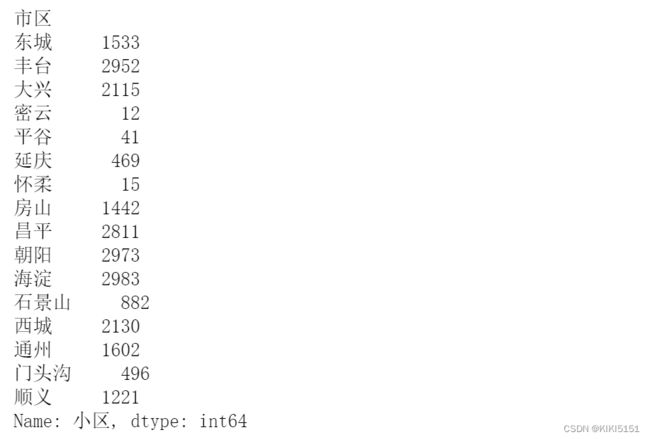
统计结论:丰台、朝阳、海淀、昌平在售的房源数量最多,高达12000多套,占了总量的1/2
4.Pyecharts可视化
4.1 北京市二手房各区分布(地图)
渲染代码如下:
new = [x + '区' for x in region]
m = (
Map()
.add('', [list(z) for z in zip(new, count)], '北京')
.set_global_opts(
title_opts=opts.TitleOpts(title='北京市二手房各区分布'),
visualmap_opts=opts.VisualMapOpts(max_=3000),
)
)
m.render_notebook()
输出如下图,其中根据opts.VisualMapOpts(max_=3000)中设置的最大值,滑动按钮,可以控制颜色显示,根据数值范围在地图上显示不同颜色。下图可以看出丰台、朝阳、海淀、昌平颜色为红,在售的房源数量最多。

4.2 各城区二手房数量-平均价格柱状图
获取每个市区房子平均价格:
df_price = g.mean()['价格(万元)']
如下,然后将其可视化

可视化代码如下,首先在bar中设置x轴(region),y主轴(count),y副轴(价格),全局设置触发效果。然后构建折线图line(price),设置z为10,使其浮在其他图上面,bar使用overlap方法叠加line,最后使用gird调整布局并渲染:
df_price.values.tolist()
price = [round(x,2) for x in df_price.values.tolist()]#四舍五入保留两位小数
bar = (
Bar()
.add_xaxis(region)
.add_yaxis('数量', count,
label_opts=opts.LabelOpts(is_show=True))
.extend_axis(
yaxis=opts.AxisOpts(
name="价格(万元)",
type_="value",
min_=200,
max_=900,
interval=100,
axislabel_opts=opts.LabelOpts(formatter="{value}"),
)
)
.set_global_opts(
title_opts=opts.TitleOpts(title='各城区二手房数量-平均价格柱状图'),
tooltip_opts=opts.TooltipOpts(
is_show=True, trigger="axis", axis_pointer_type="cross"
),#十字校准器触发
xaxis_opts=opts.AxisOpts(
type_="category",
axispointer_opts=opts.AxisPointerOpts(is_show=True, type_="shadow"),#x轴触发阴影
),
yaxis_opts=opts.AxisOpts(name='数量',
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=False),)
)
)
line2 = (
Line()
.add_xaxis(xaxis_data=region)
.add_yaxis(
series_name="价格",
yaxis_index=1,#存在多个y轴时
y_axis=price,
label_opts=opts.LabelOpts(is_show=True),
z=10
)
)
bar.overlap(line2)#叠加
grid = Grid()
grid.add(bar, opts.GridOpts(pos_left="5%", pos_right="20%"), is_control_axis_index=True)
grid.render_notebook()
如图所示:

可以看出,东城区、西城区和海淀区二手房平均售价最高,均在800万元以上。
4.3 二手最高价格top15
获得前15条房价最高数据:
top_price = df.sort_values(by="价格(万元)",ascending=False)[:15]
渲染代码如下:
area0 = top_price['小区'].values.tolist()
count = top_price['价格(万元)'].values.tolist()
bar = (
Bar()
.add_xaxis(area0)
.add_yaxis('数量', count,category_gap = '50%')
.set_global_opts(
yaxis_opts=opts.AxisOpts(name='价格(万元)'),
xaxis_opts=opts.AxisOpts(name='数量'),
)
)
bar.render_notebook()
如图:
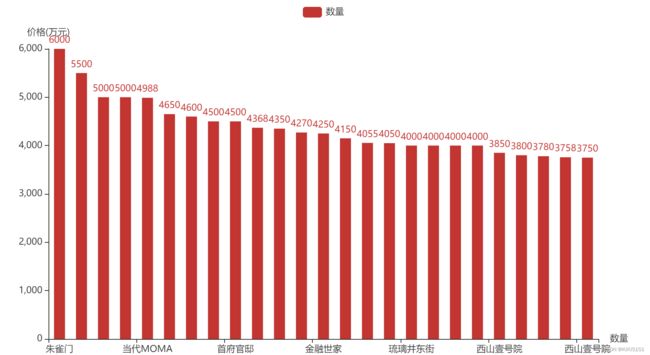
4.4 二手房总价与面积散点图
直接使用df数据渲染
s = (
Scatter()
.add_xaxis(df['面积(㎡)'].values.tolist())
.add_yaxis('',df['价格(万元)'].values.tolist())
.set_global_opts(xaxis_opts=opts.AxisOpts(type_='value'))
)
s.render_notebook()

4.5 房屋朝向饼图
根据房屋朝向分组:
g = df.groupby('朝向')
df_direction = g.count()['小区']
输出df_direction如下:

directions = df_direction.index.tolist()
count = df_direction.values.tolist()
c1 = (
Pie(init_opts=opts.InitOpts(
width='800px', height='600px',
)
)
.add(
'',
[list(z) for z in zip(directions, count)],
radius=['20%', '60%'],
center=['50%', '50%'],
# rosetype="radius",
label_opts=opts.LabelOpts(is_show=True),
)
.set_global_opts(title_opts=opts.TitleOpts(title='房屋朝向占比',pos_left='33%',pos_top="5%"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="90%",pos_top="25%",orient="vertical")
)
.set_series_opts(label_opts=opts.LabelOpts(formatter='{b}:{c} ({d}%)'),position="outside")
)
c1.render_notebook()
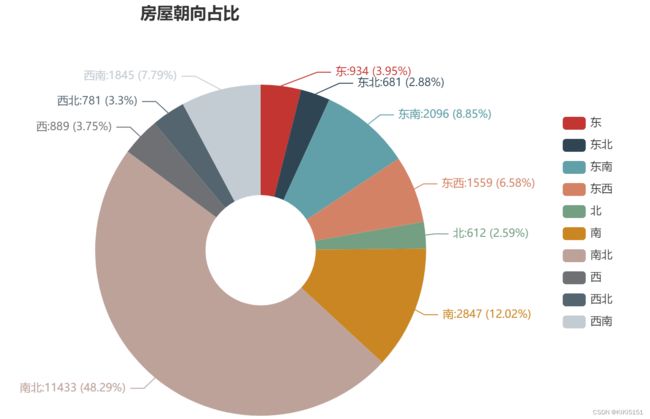
结论:房屋朝向约50%是坐北朝南的
4.6 二手房楼层分布柱状图
按楼层分组:
g = df.groupby('楼层')
df_floor = g.count()['小区']
条形图渲染代码,其中增加了可滑动条:
floor = df_floor.index.tolist()
count = df_floor.values.tolist()
bar = (
Bar()
.add_xaxis(floor)
.add_yaxis('数量', count)
.set_global_opts(
title_opts=opts.TitleOpts(title='二手房楼层分布柱状缩放图'),
yaxis_opts=opts.AxisOpts(name='数量'),
xaxis_opts=opts.AxisOpts(name='楼层'),
datazoom_opts=opts.DataZoomOpts(type_='slider')
)
)
bar.render_notebook()
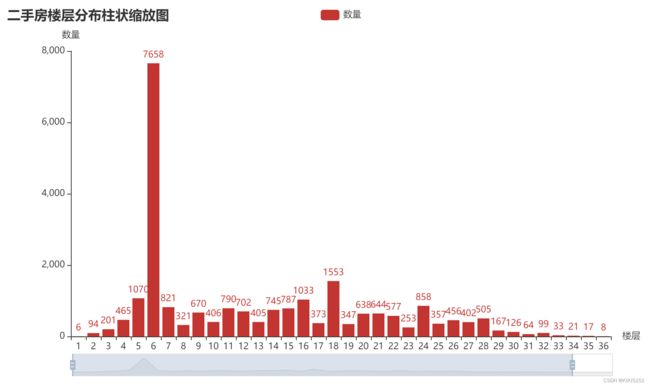
结论:二手楼房在六层分布最多
4.7 房屋面积分布柱状图
根据area_level切分,坐标轴转置:
area_level = [0, 50, 100, 150, 200, 250, 300, 350, 400, 1500]
label_level = ['小于50', '50-100', '100-150', '150-200', '200-250', '250-300', '300-350', '350-400', '大于400']
jzmj_cut = pd.cut(df['面积(㎡)'], area_level, labels=label_level)
df_area = jzmj_cut.value_counts()
area = df_area.index.tolist()
count = df_area.values.tolist()
bar = (
Bar()
.add_xaxis(area)
.add_yaxis('数量', count)
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(
title_opts=opts.TitleOpts(title='房屋面积分布纵向柱状图'),
yaxis_opts=opts.AxisOpts(name='面积(㎡)'),
xaxis_opts=opts.AxisOpts(name='数量'),
)
)
bar.render_notebook()
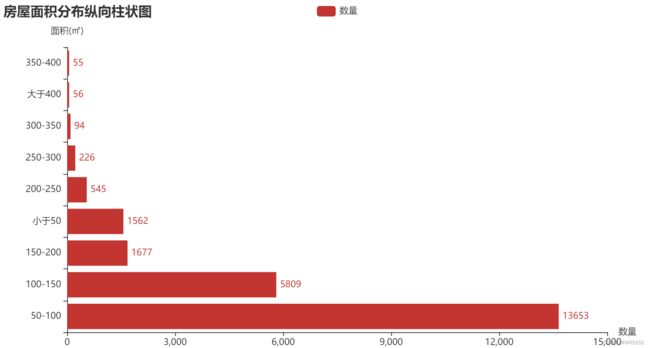
结论:二手房面积多集中于0-400平米,50-100平米的居多。