17李沐动手学深度学习v2/实战kaggle比赛,房价预测
# 下载数据工具函数
import hashlib
import os
import tarfile
import zipfile
import requests
DATA_HUB=dict()
DATA_URL='http://d2l_data.s3-accelerate.amazonaws.com/'
def download(name,cache_dir=os.path.join('.','data')):
'''
下载DATA_HUB中的文件到本地后返回本地文件名
:return 本地文件名
'''
assert name in DATA_HUB,f'{name}不存在于{DATA_HUB}。'
url,sha1_hash =DATA_HUB[name]
os.makedirs(cache_dir,exist_ok=True)
fname=os.path.join(cache_dir, url.split('/')[-1])
if os.path.exists(fname):
sha1=hashlib.sha1()
with open(fname,'rb') as f:
while True:
data = f.read(1048576)
if not data:
break
sha1.update(data)
if sha1.hexdigest() == sha1_hash:
# 命中缓存
return fname
print(f'正在从{url}下载{fname}...')
r = requests.get(url, stream=True, verify=True)
with open(fname, 'wb') as f:
f.write(r.content)
return fname
def download_extract(name, folder=None):
'''
下载并解压
'''
fname = download(name)
base_dir = os.path.dirname(fname)
data_dir, ext = os.path.splitext(fname)
# 只有zip/tar文件可以被解压缩
if ext == '.zip':
fp = zipfile.ZipFile(fname, 'r')
elif ext in ('.tar', '.gz'):
fp = tarfile.open(fname, 'r')
else:
assert False
fp.extractall(base_dir)
return os.path.join(base_dir, folder) if folder else data_dir
def download_all():
'''
下载DATA_HUB中的所有文件
'''
for name in DATA_HUB:
download(name)
# pandas读入并处理数据
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from torch import nn
from d2l import torch as d2l
DATA_HUB['kaggle_house_train'] = (DATA_URL + 'kaggle_house_pred_train.csv',
'585e9cc93e70b39160e7921475f9bcd7d31219ce')
DATA_HUB['kaggle_house_test'] = (DATA_URL + 'kaggle_house_pred_test.csv',
'fa19780a7b011d9b009e8bff8e99922a8ee2eb90')
# train_data = pd.read_csv(download('kaggle_house_train'))
# test_data = pd.read_csv(download('kaggle_house_test'))
# 输出(1,1)则需要科学上网或者下载文件再把内容拷贝进去
# print(train_data.shape)
# print(test_data.shape)
# 下载文件再把内容拷贝进去
train_data = pd.read_csv('./data/kaggle_house_pred_train.csv')
test_data = pd.read_csv('./data/kaggle_house_pred_test.csv')
print(train_data.shape)
print(test_data.shape)
# 前4行的前4列和后3列。Id不参与训练
print(train_data.iloc[0:4,[0,1,2,3,-3,-2,-1]])
(1460, 81)
(1459, 80)
Id MSSubClass MSZoning LotFrontage SaleType SaleCondition SalePrice
0 1 60 RL 65.0 WD Normal 208500
1 2 20 RL 80.0 WD Normal 181500
2 3 60 RL 68.0 WD Normal 223500
3 4 70 RL 60.0 WD Abnorml 140000
# 数据预处理
# 剔除不参与训练数据:取出第1列的Id,Id不参与训练
all_features=pd.concat((train_data.iloc[:,1:-1],test_data.iloc[:,1:]))
# number类型处理
# 获取数值类型特征的索引
numeric_features=all_features.dtypes[all_features.dtypes!='object'].index
# 数值特征缩放
all_features[numeric_features]=all_features[numeric_features].apply(lambda x:(x-x.mean())/x.std())
# 数值NA值处理
all_features[numeric_features]=all_features[numeric_features].fillna(0)
print(all_features.shape)
# 离散值处理,one-hot编码,将离散特征的值转为类别,列为离散类别,,行为1或0,行只有1个为1其余全0,行只有1个类别被激活(为1)其余都为0
# 参考网址 https://zhuanlan.zhihu.com/p/139144355
# 问题:会对number类型其作用吗?会对number其作用,为了统一处理
all_features=pd.get_dummies(all_features,dummy_na=True)
print(all_features.shape)
(2919, 79)
(2919, 331)
# 数据转化为张量
# 训练样本数量 train_data.shape=样本数量,特征量
n_train=train_data.shape[0]
# .values是numpy的类型
# shape=训练样本数量
train_features=torch.tensor(all_features[:n_train].values,dtype=torch.float32)
# shape=测试样本数量
test_features=torch.tensor(all_features[n_train:].values,dtype=torch.float32)
# 标签 shape=行,1列
train_labels=torch.tensor(train_data.SalePrice.values.reshape(-1,1),dtype=torch.float32)
# 损失函数
loss=nn.MSELoss()
# 训练数据特征数量 =331
in_features=train_features.shape[1]
# 模型
def get_net():
'''
获取网络模型
'''
# 1个特征1个神经元
net=nn.Sequential(nn.Linear(in_features,1))
return net
房价适合相对误差 y − y ^ y \frac{y-\hat{y}}{y} yy−y^,因为不同房子的价格相差很大,1000万的房子产生的预测误差可能远远大于10万的房子产生的预测误差,本质是误差缩放(类比特征缩放)
y − y ^ y , 取对数 , l o g ( y − y ^ ) − l o g y \frac{y-\hat{y}}{y},取对数,log(y-\hat{y})-logy yy−y^,取对数,log(y−y^)−logy,所以使用log_rmse(log均方根误差),RMSE均方根误差
l o g R M S E = 1 n ∑ ( l o g ( y p ) − l o g ( y ) ) 2 log RMSE=\sqrt{\frac{1}{n}\sum(log(y_{p})-log(y))^2} logRMSE=n1∑(log(yp)−log(y))2
# 获取log_rmse 相对误差
def log_rmse(net,features,labels):
'''
log均方根误差
:param net 模型
:param faeatures 数据
:param labels 真实结果标签
'''
# clipped_preds合理预测值
# clamp夹紧,元素值限制到[min,max]内
# net(features)的预测值为inf变成1,方便log RMSE,因为log(inf)=inf log(1)=0
clipped_preds=torch.clamp(net(features),1,float('inf'))
# loss是MSE函数,
rmse=torch.sqrt(loss(torch.log(clipped_preds),torch.log(labels)))
# item()获取张量元素值,不要张量中那些括号了
return rmse.item()
# 在训练集上进行k折交叉验证(没有使用测试集)
# 训练函数
def train(net,train_features,train_labels,test_features,test_labels,
num_epochs,learning_rate,weight_decay,batch_size):
'''
:param weight_decay, 权重衰退参数, =lambda 常用值1e-2,1e-3,1e-4
:param test_features,测试数据集,不是验证集,只能被使用1次,验证集在train中使用k折交叉验证产生
'''
# ls loss
train_ls,test_ls=[],[]
# 数据
train_iter=d2l.load_array((train_features,train_labels),batch_size)
# 优化算法,SGD,Adam
# adam对学习率没有SGD那么敏感
# adam优化算法,结合了AdaGrad和RMSProp两种优化算法的优点
# AdaGrad:学习率自适应,梯度自适应,Adaptive Gradient,自适应梯度
# RMSProp:学习率自适应,梯度自适应,AdaGrad的改进,克服AdaGrad梯度急剧减小的问题
optimizer=torch.optim.Adam(net.parameters(),lr=learning_rate,weight_decay=weight_decay)
for epoch in range(num_epochs):
for X,y in train_iter:
# 重新开始训练梯度置0,每训练1个batch_size的数据,梯度置0
optimizer.zero_grad()
# 损失函数
l=loss(net(X),y)
# 后向传播计算梯度
l.backward()
# 前进1步,更新参数
optimizer.step()
train_ls.append(log_rmse(net,train_features,train_labels))
# 测试数据损失
if test_labels is not None:
test_ls.append(log_rmse(net,test_features,test_labels))
return train_ls,test_ls
# 获取k折交叉验证所需数据
def get_k_fold_data(k,i,X,y):
'''
获取k折交叉验证所需数据
k折交叉验证获取训练数据集和验证数据集
:param k
:param i 第i折
'''
assert k>1
# //k地板除,向下取整
# 样本数量/k=1折含有的样本数量
fold_size=X.shape[0]//k
X_train,y_train=None,None
for j in range(k):
# 获取第i折的样本和标签的索引
idx=slice(j*fold_size,(j+1)*fold_size)
X_part,y_part=X[idx,:],y[idx]
# 第i折作为验证集,剩下的k-1折做训练集
if j==i:
X_valid,y_valid=X_part,y_part
# 初始X_train=None处理
elif X_train is None:
X_train,y_train=X_part,y_part
# 已经有值X_train处理
else:
X_train=torch.cat([X_train,X_part],0)
y_train=torch.cat([y_train,y_part],0)
return X_train,y_train,X_valid,y_valid
# k折交叉验证
def k_fold(k,X_train,y_train,num_epochs,learning_rate,weight_decay,batch_size):
'''
k折交叉验证过程:
- 做k次k折交叉验证
- 数据分成k组,每个子集做1次验证集,剩余k-1组做训练集,得到k个模型
- 模型性能指标=k个模型最终的验证集的分类准确率的平均数
:param k
:return k折平均损失
'''
# l=loss
train_l_sum,valid_l_sum=0,0
for i in range(k):
# 例如5折,第i折做验证集,每1折都做1次验证集
data=get_k_fold_data(k,i,X_train,y_train)
net=get_net()
# *展开tuple。
train_ls,valid_ls=train(net,*data,num_epochs,learning_rate,weight_decay,batch_size)
# -1取最后1个epoch的训练损失
train_l_sum+=train_ls[-1]
valid_l_sum+=valid_ls[-1]
# 绘制第1折的训练图像
if i==0:
d2l.plot(list(range(1,num_epochs+1)),[train_ls,valid_ls],
xlabel='epoch', ylabel='rmse',
xlim=[1, num_epochs],
legend=['train', 'valid'],
yscale='log')
# 第i折的最后1个epoch的训练和验证log rmse
print(f'fold {i + 1}, train log rmse {float(train_ls[-1])},'
f'valid log rmse {float(valid_ls[-1]):f}')
plt.show()
# 模型性能指标=k个模型最终的验证集的分类准确率的平均数
return train_l_sum/k,valid_l_sum/k
# !我们要做的事情,调参,调模型,让k折交叉验证平均(训练/验证)损失最小
# k=5 5折交叉验证, weight_decay=lambda=0 不进行权重衰退
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr, weight_decay, batch_size)
print(f'{k}-折验证:平均训练log rmse: {float(train_l):f},'f'平均验证log rmse: {float(valid_l):f}')
fold 1, train log rmse 0.17030069231987,valid log rmse 0.156635
fold 2, train log rmse 0.16240288317203522,valid log rmse 0.192009
fold 3, train log rmse 0.16362003982067108,valid log rmse 0.168152
fold 4, train log rmse 0.16828565299510956,valid log rmse 0.154788
fold 5, train log rmse 0.16267813742160797,valid log rmse 0.183101
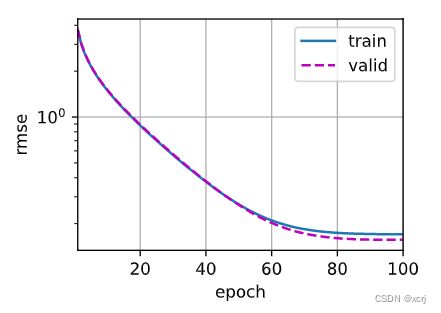
5-折验证:平均训练log rmse: 0.165457,平均验证log rmse: 0.170937
# 在完整训练集上进行训练(未使用k折交叉验证)在测试集上进行预测
def train_and_pred(train_features, test_features, train_labels, test_data, num_epochs, lr, weight_decay, batch_size):
'''
完整训练集上训练和测试集上预测
生成提交文件(样本Id,预测值)
'''
net=get_net()
# 完整训练集上训练
train_ls,_=train(net,train_features,train_labels,None,None,num_epochs,
lr,weight_decay,batch_size)
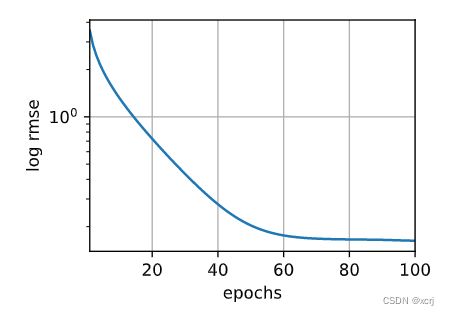
# 绘制随epoch变化的log rmse损失
d2l.plot(np.arange(1,num_epochs+1),[train_ls],
xlabel='epochs', ylabel='log rmse',
xlim=[1, num_epochs], yscale='log')
# 训练最后1个epoch的log rmse
print(f'train log rmse {float(train_ls[-1]):f}')
# 在测试集上预测
# detach()从计算图中移除,不进行梯度计算,返回一个新的从当前图中分离的Variable
preds=net(test_features).detach().numpy()
# preds转为(1,n) [0]取第一行
# SalePrice列名=这一行数据
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
# pd.concat(,axis=1)按列拼接
submission=pd.concat([test_data['Id'],test_data['SalePrice']],axis=1)
# 生成csv文件,index=False不要索引列
submission.to_csv('submission.csv', index=False)
plt.show()
train_and_pred(train_features, test_features, train_labels, test_data, num_epochs,
lr, weight_decay, batch_size)
train log rmse 0.162484