神经网络架构搜索(Neural Architecture Search, NAS)笔记
目录
- (一)背景
- (二)NAS流程
-
- 2.1 定义搜索空间
- 2.2 搜索策略
- (三)加速
- (四)变体及扩展
-
- 4.1 扩展到其他任务
- 4.2 扩展到其他超参数
(一)背景
机器学习从业者被戏称为“调参工”已经不是一天两天了。我们知道,机器学习算法的效果好坏不仅取决于参数,而且很大程度上取决于各种超参数。有些paper的结果很难重现原因之一就是获得最优超参值往往需要花很大的力气。超参数的自动搜索优化是一个古老的话题了。深度学习兴起前它主要针对传统机器学习算法中的模型超参数,比较经典的方法有随机搜索(Random search), 网格搜索(Grid search),贝叶斯优化(Bayesian optimization),强化学习(Reinforcement learning), 进化算法(Evolutionary Algorithm)等,统称为Hyperparameter optimization(HO)。像Auto-sklearn和Auto-WEKA都是比较有名的HO框架。对于深度学习说,超参数主要可为两类:一类是训练参数(如learning rate,batch size,weight decay等);另一类是定义网络结构的参数(比如有几层,每层是啥算子,卷积中的filter size等),它具有维度高,离散且相互依赖等特点。前者的自动调优仍是HO的范畴,而后者的自动调优一般称为网络架构搜索(Neural Architecture Search,NAS)。这些年来大热的深度神经网络,虽然将以前很令人头疼的特征提取自动化了,但网络结构的设计很大程度上还是需要人肉,且依赖经验。每年各AI顶会上一大批论文就是在提出各种新的更优的网络子结构。一个自然的诉求就是这个工作能否交给机器来做。
本质上网络架构搜索,和围棋类似,是个高维空间的最优参数搜索问题。既然围棋上AlphaGo可以战胜人类,那在网络架构搜索上机器最后也很有可能可以取代人类。我们知道,AlphaGo主要是基于强化学习。2016年,MIT和Google的学者们差不多在同一时间发表论文,将强化学习引入到深度神经网络结构的搜索中,取得了不俗的成果。在几个小型的经典数据集上击败同时代同级别的手工设计网络。但这个方法有个缺点是消耗计算资源巨大,基本就不是一般人玩得起的。这个坑也是后面一大波工作改进的重点。尔后,Google发布AutoML平台,将之带入公众视野。现在这块领域无论是在学界还是在工业界,都成为香饽饽的热点。本文主要杂聊NAS中的搜索策略,加速方法,以及变体与扩展。涉及点及举例如图所示。
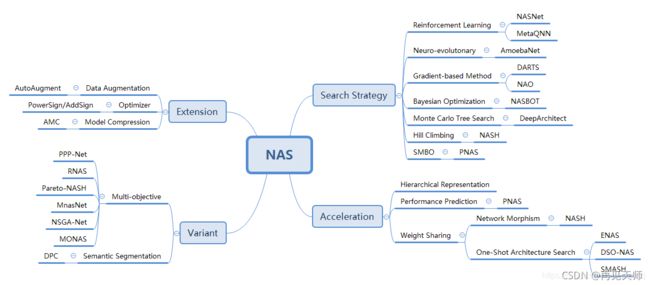
(二)NAS流程
NAS的流程基本是这样的:先定义搜索空间,然后通过搜索策略找出候选网络结构,对它们进行评估,根据反馈进行下一轮的搜索。
2.1 定义搜索空间
首先定义搜索空间。搜索空间定义基本是和DNN的发展相应。可以看到,早期的CNN大都是链式结构,因此初期的NAS工作中搜索空间也主要考虑该结构,只需考虑共几层,每层分别是什么类型,以及该类型对应的超参数。再后面,随着像ResNet,DenseNet,Skip connection这样的多叉结构的出现,NAS中也开始考虑多叉结构,这样就增大了组合的自由度可以组合出更多样的结构。另外,很多DNN结构开始包含重复的子结构(如Inception,DenseNet,ResNet等),称为cell或block。于是NAS也开始考虑这样的结构,提出基于cell的搜索。即只对cell结构进行结构搜索,总体网络对这些cell进行重叠拼接而成。当然如何拼接本身也可以通过NAS来学习。这样相当于减少自由度来达到减少搜索空间的目的,同样也可以使搜索到的结构具有更好的数据集间迁移能力。为了让搜索模型可以处理网络结构,需要对其编码。搜索空间中的网络架构可以表示为描述结构的字符串或向量。
2.2 搜索策略
网络结构的搜索策略有很多。像随机搜索就是比较简单,但相对低效的做法,通常用作baseline(基线)。其它研究得比较多的有几类:
- 基于强化学习(Reinforcement learning): 如上面提到的,开创性的工作主要是2016年由MIT发表的《Designing Neural Network Architectures using Reinforcement Learning》和Google发表的《Neural Architecture Search with Reinforcement Learning》两篇文章。前者提出MetaQNN,它将网络架构搜索建模成马尔可夫决策过程,使用RL方法(具体地,Q-learning算法)来产生CNN架构。对于CNN的每一层,学习体会选取层的类型和相应参数。生成网络结构后训练后得到的评估精度作为回报。这个回报用以参于Q-learning训练。作者在SVHN、CIFAR-10和MNIST三个数据集上进行了实验。用了10个GPU花费8-10天时间,基本可以击败同『重量级』的网络。后者采用RNN网络作为控制器来采样生成描述网络结构的字符串,该结构会用于训练并得到评估的准确率,然后使用了REINFORCE算法(早期的RL方法,在他们后面的工作中又使用了比较新的更加sample efficient的PPO算法)学习控制器的参数,使之能产生更高准确率的网络结构。它动用了800个GPU,最终在CIFAR-10数据集上击败了具有类似网络架构的人工设计模型,在PTB数据集上达到了新的SOTA水平,并且还找到了比广泛使用的LSTM更优的结构。
- 基于进化算法(Evolutionary algorithm): 在Google的论文《Large-Scale Evolution of Image Classifiers》中,进化算法被引入来解决NAS问题,并被证明在CIFAR-10和CIFAR-100两个数据集上能从一个简单的初始条件开始达到高的精度。首先,网络结构会进行编码,称为DNA。演进过程中会维扩护网络模型的集合,这些网络模型的fitness通过它们在验证集上的准确率给出。在进行过程中,会随机选取两个模型 ,差的那个直接被干掉(淘汰),好的那个会成为父节点(这种方式为tournament selection)。子节点经过变异(就是在一些预定的网络结构变更操作中随机选取)形成子结点。子结点经过训练和验证过放入集合。该作者在后续论文《Regularized Evolution for Image Classifier Architecture Search》中,提出了tournament selection的变体aging evolution,让进化中的选择倾向于比较『年轻』的模型,它可以帮助更好地进行探索。经搜索出的最优网络结构称为AmoebaNet(源码链接)。另外作者对强化学习,进化算法和随机搜索作了比较,发现强化学习和进化算法从准确率上来说表现很好。与强化学习相比进化算法搜索得更快(尤其是早期),且能得到更小的模型。随机搜索在学习到的网络准确率上会次于前面两者,但差距不是那么大(尤其是小数据集上)。
- 基于梯度的方法(Gradient-based method): 这是比较新的一类方法。前面提到的基于强化学习和进化算法的方法本质上都还是在离散空间中搜索,它们将目标函数看作黑盒。我们知道,如果搜索空间连续,目标函数可微,那基于梯度信息可以更有效地搜索。CMU和Google的学者在《DARTS: Differentiable Architecture Search》一文中提出DARTS方法。一个要搜索最优结构的cell,可以看作是包含N个有序结点的有向无环图。结点代表隐式表征(例如特征图),连接结点的的有向边代表算子操作。DARTS方法中最关键的trick是将候选操作使用softmax函数进行混合。这样就将搜索空间变成了连续空间,目标函数成为了可微函数。这样就可以用基于梯度的优化方法找寻最优结构了。搜索结束后,这些混合的操作会被权重最大的操作替代,形成最终的结果网络。另外,中科大和微软发表的论文《Neural Architecture Optimization》中提出另一种基于梯度的方法。它的做法是先将网络结构做嵌入(embedding)到一个连续的空间,这个空间中的每一个点对应一个网络结构。在这个空间上可以定义准确率的预测函数。以它为目标函数进行基于梯度的优化,找到更优网络结构的嵌入表征。优化完成后,再将这个嵌入表征映射回网络结构。这类方法的优点之一就是搜索效率高,对于CIFAR-10和PTB,结合一些像权重共享这样的加速手段,消耗可以少于1 GPU/天。
其它还有如基于Boosting、MCTS、BO,Hill Climbing Algorithm等的方法,如论文《Adaptive structural learning of artificial neural networks》,《Deeparchitect: Automatically designing and training deep architectures》,《Neural architecture search with bayesian optimisation and optimal transport》,《Simple And Efficient Architecture Search for Convolutional Neural Networks》。这些方法相关讨论相对少些,就不详细展开了。
(三)加速
上面提到,由于NAS中涉及的搜索空间巨大,而且其性能评估往往得涉及模型的训练,导致消耗的资源很大。像前面提到的基于强化学习和进化算法的方法,对于CIFAR这样不算大的数据集,基本都是用了上千GPU/天,家里没矿的或是小公司可能连研究的门槛都没到,可以说基本还没法平民化。因此,后面的一大批论文就是和这个问题作斗争。其中比较典型的加速方法有几类:
- 层次化表示(Hierarchical Representation): 如果要对一整个神经网络结构进行搜索,搜索空间是非常大的。Google的论文《Learning Transferable Architectures for Scalable Image Recognition》提出NASNet(源码链接),它假设整体网络是由cell重复构建的,那搜索空间就缩小到对两类cell(normal cell和reduction cell)结构的搜索上,从而大大减小了搜索空间。在CIFAR数据集上达到了比同期SOTA网络更高的精度,同时这样的分解也有助于知识的迁移,学习到的cell结构可以帮助在更大的图片分类数据集以及在物体检测数据集上得到SOTA的结果。注意在这个方法中,虽然cell结构是学习得到的,但如何重复和组合这些cell的元网络结构是预定义的。更拓展地,CMU和Google发表的论文《Hierarchical Representations for Efficient Architecture Search》中定义了一种层次化的网络结构:最底层为像卷积和池化等基本组件;中间层为这些组件所构成的图;最高层就是由这些图层叠而成的整体网络。
- 权重共享(Weight sharing): 在NAS过程中,最为耗时的其实就是对于候选模型的训练。而初版的NAS因为对每个候选模型都是从头训练的,因此会相当耗时。一个直观的想法是有没有办法让训练好的网络尽可能重用。上海交大和伦敦大学学院的论文《Reinforcement Learning for Architecture Search by Network Transformation》中将Network morphisms(网络态射)与神经网络搜索结合。所谓网络态射就是将网络进行变形,同时保持其功能不变。这样带来的好处是变形后可以重用之前训练好的权重,而不用重头开始训练。论文《Simple And Efficient Architecture Search for Convolutional Neural Networks》也使用了网络态射来达到共享权重的目的,只是它了爬山算法为搜索策略。经典的网络态射一般是从小网络开始,然后做『加法』(也有论文讨论让它支持做『减法的』);另一种思路就是从大网络开始做减法,如One-Shot Architecture Search方法,就是在一个大而全的网络上做减法。Google的论文《Efficient Neural Architecture Search via Parameter Sharing》提出了ENAS,其核心思想也是让搜索中所有的子模型重用权重。它将NAS的过程看作是在一张大图中找子图,图中的边代表算子操作。基本方法和《Neural Architecture Search with Reinforcement Learning》中的类似,使用基于LSTM的控制器产生候选网络结构,只是这里是决定大图中的哪些边激活,以及使用什么样的操作。这个LSTM控制器的参数和模型参数交替优化。由于权重共享,使用Nvidia GTX 1080Ti可以在一天内完成搜索,实现了1000x的提速。Auto-Keras就是基于ENAS的思想加以改造实现的。还有一个比较特别的思路,论文《SMASH: One-Shot Model Architecture Search through HyperNetworks》中对于候选模型,使用HyperNet来给出其权重,从而避免重头训练。最近,中科院的论文《You Only Search Once: Single Shot Neural Architecture Search via Direct Sparse Optimization》中提出了DSO-NAS方法,如其名称其特点是只搜一次。它始于一个完全连接的块,然后在操作间引入缩放因子,同时添加稀疏正则化来去除无用的连接,也就是去除不重要的操作,得到最优结构。文中提出可以在一个优化问题中同时学习网络结构和参数。
- 表现预测(Performance prediction): 我们知道,NAS中最费时的是候选模型的训练,而训练的目的是为了评估该结构的精度。为了得到某个网络模型的精度又不花费太多时间训练,通常会找一些代理测度作为估计量。比如在少量数据集上、或是低分辨率上训练的模型精度,或是训练少量epoch后的模型精度。尽管这会普遍低估精度,但我们要的其实不是其绝对精度估计,而是不同网络间的相对值。换言之,只要能体现不同网络间的优劣关系,是不是绝对精准没啥关系。从另一个角度思考,有没有可能基于模型结构直接预测其准确率呢。论文《Progressive Neural Architecture Search》中的关键点之一是使用了一个代理模型来指导网络结构的搜索。具体来说,这个代理模型是个LSTM模型,输入为网络结构的变长字符串描述,输出预测的验证精度。也正是有个这个利器,使得它里边提出方法即使用看起来并不复杂的启发式搜索,也能达到很好的效果。还有一个思路就是基于学习曲线来预测,这基于一个直观认识,就是我们在训练时基本训练一段时间看各种指标曲线就能大体判断这个模型是否靠谱。学习曲线预测,一种直观的想法就是外插值,如论文《Speeding up Automatic Hyperparameter Optimization of Deep Neural Networks by Extrapolation of Learning Curves》中所讨论的。之后论文《Learning Curve Prediction with Bayesian Neural Networks》中使用Bayesian neural network对学习曲线进行建模与预测。当然实际的预测中,可以不局限于单一的特征,如在论文《Accelerating Neural Architecture Search using Performance Prediction》中,结合了网络结构信息,超参数信息和时序上的验证精度信息来进行预测,从而提高预测准确性。总得来说,表现预测由于其高效性,在NAS中起到越来越关键的作用。很多的前沿方法也采用这类方法,如前面提到的《Neural Architecture Optimization》中就有预测器来基于网络表示预测其准确率。
(四)变体及扩展
4.1 扩展到其他任务
以上主要针对NAS本身的改进,且主要实验限于图像分类任务和自然语言处理,且大多只关注模型准确率。很自然的,大家就将NAS往其它的任务上应用,或者将更多因素纳入目标考虑。比如下面两项工作:
- 语义分割: Google论文《Searching for Efficient Multi-Scale Architectures for Dense Image Prediction》将NAS拓展到主义分割领域(源码链接)。语义分割任务与图片分类相比,输入的尺寸更大。经典的语义分割网络需要特殊的结构,如空洞卷积、ASPP等来提取多尺度上下文信息。这给NAS带来了更大的挑战。这篇文章主要focus在两点:搜索空间的设计与代理任务的设计。对于搜索空间,文中提出了适合语义分割任务的DPC(Dense Prediction Cell)。对于评估精度的代理任务,由于语义分割任务与图片分类不同,往往依赖大分辨率,因此,代理任务的设计上,一方面采用小的网络backbone;另一方面将在训练集上得到的feature map cache起来重用。实验表明,机器搜到的网络在如Cityscapes、PASCAL-Person-Part和PASCAL VOC2012上能得到SOTA结果。
- 多目标: 随着各种AI场景在手机等端设备上应用需求的涌现,一些适用于资源受限环境的轻量级网络,如MobileNet,ShuffleNet开始出现并被广泛研究。自然地,NAS也开始从只考虑精度的单目标演进到多目标,如同时考虑精度、计算量、功耗等。多任务优化问题的一个挑战是往往没法找到单一解让所有子目标同时最优,所以我们找的一般是帕累托最优解。而具体到实际应用中,就涉及到多目标间tradeoff的问题。Google的论文《MnasNet: Platform-Aware Neural Architecture Search for Mobile》提出的MnasNet就是比较典型的例子。搜索方法上还是延续之前经典的RNN控制器+强化学习方法,在一个层次化搜索空间中搜索。它一方面提出带参数的优化目标,通过调节参数可以在精度和延时之间做权衡(如将延时作为硬要求或者软要求);另一方面在实现中将实际设备运行得到的推理延迟作为评估。尽管我们有模型大小、计算量和compute intensity等作为侧面的延时估计,但现实中由于延时会被很多因素影响,很难精确估计,还不如直接拿个设备来跑。。。从实验来看,能比前沿的轻量级模型找到更优的网络结构(如在ImageNet分类任务中,差不多精度下比MobileNet v2快50%)。其它比如论文《Resource-Efficient Neural Architect》中提出的RENA(Resource-Efficient Neural Architect),《PPP-Net: Platform-aware Progressive Search for Pareto-optimal Neural Architectures》中提出的PPP-Net(Platform-aware Progressive search for Pareto-optimal Net),《Efficient Multi-objective Neural Architecture Search via Lamarckian Evolution》中提出的LEMONADE(Lamarckian Evolutionary algorithm for Multi-Objective Neural Architecture DEsign),《NSGA-NET: A Multi-Objective Genetic Algorithm for Neural Architecture Search》中的NSGA-NET,都是对多目标NAS的探讨。
4.2 扩展到其他超参数
NAS已在一些基本任务及数据集上证明能超越人类手工设计,那在其它深度学习相关的超参数上是否也能使用类似的思想让机器自动学习,从而得到比人工设计更好的参数,并免除人肉调参的痛苦呢。下面列举了几个这方面比较有趣的尝试:
- 优化器: 相对网络结构来说,优化器的迭代可以说是比较慢的,但每次重要的演进又很容易引人关注,因为这个太通用了。从最基本的SGD到Adagrad, Adadelta, RMSProp,Adam等更加精巧的更新方式,很多其实是加入了一些启发(如物理中的momentum概念),还是属于手工打造,实验证明。论文《Neural Optimizer Search with Reinforcement Learning》将使用在NAS上的方法拓展到了优化器(更准确地,更新公式)的优化上。与其它类似工作相比其优点之一是它输出的是更新公式,因此在不同模型和任务间具有更好的迁移能力。首先将更新规则用字符串描述,其描述了该更新公式中所使用的操作数(像梯度及其幂,和它们的指数滑动平均、噪声、Adam/RMSProp或一些常数等),应用在其上的unary函数(取负、自然底数、绝对值取对数、clip等),以及操作数之间的binary函数(加减乘除等)。然后采用NAS中类似的基于RNN的控制器,之后用验证集精度为回报来采用强化学习训练控制器。作者实验中找到了两个新的优化器 - PowerSign和AddSign,并被证明在实验数据集上强于现在常见的优化器。
- 模型压缩: 这几年,模型压缩可谓是深度学习中最为火热的分支之一。该方向对于落地到移动端上尤其重要。在AutoML的浪潮下,这项工作也有了新的拓展。MIT,西安交大和Google的论文《AMC: AutoML for Model Compression and Acceleration on Mobile Devices》主要针对模型压缩中的重要方法之一 - 剪枝(Pruning)。业界普遍认为虽然模型训练时需要复杂的结构,但训练好的模型一般有比较高的冗余度,因此可以进行裁剪,且只降低很少精度,甚至可能提高精度(由于剪枝能起到正则化效果,从而提高模型的泛化能力)。但是,剪枝策略中的参数选择是件很tricky的事。拿稀疏率来说,由于每层可能都有不同的冗余程度,因此有各自不同的最优稀疏率。虽然有不少启发式的策略,但还是需要人肉试验看效果。这篇文章提出AMC(AutoML for Model Compression)方法,引入强化学习(具体地,DDPG算法)来学习最优的参数,并且通过设计不同的回报函数可以让最后得到的模型满足不同需要(如高压缩率,或是保证精度)。实验表明,在ImageNet数据集VGG-16模型上,在计算量减少到1/4的情况下准确率比人工调参下高2.7%;另外MobileNet模型可以在准确率只掉0.1%的前提下在Android手机和Titan XP GPU上分别达到1.81和1.43倍的加速。
- 数据增强: AutoML的意义在于把之前启发式人工设计的东西用机器搜索来替代。而深度学习尤其是视觉任务中,有一项容易被忽视但又对结果至关重要的就是数据增强,它被认为可以很大程度上在已有数据集条件下增强模型的泛化能力。另外,数据增强方法的挑战之一是它不是完全通用的,如某一特定数据集上最优的数据增强方法可能并不适用于另一数据集。这就意味着对于特定任务,我们需要找到最适合的数据增强手段。论文《AutoAugment: Learning Augmentation Policies from Data》正是做了这方面的探索,首先定义搜索空间:一个数据增强策略包含五个子策略,每个子策略包含两个图像操作,每个图像操作包含两个超参数:一个是应用该操作的概念,另一个是操作相关应用程度。考虑的操作包含shear, translate, rotate等16种。这样就把该问题很好地转化为最优参数搜索问题了。然后基本可以沿用NAS中的方法,使用一个基于RNN的控制器来给出数据增强策略,然后将应用该数据增强策略下的模型精度作为回报,使用强化学习(具体地,PPO算法)训练该控制器。作者实验表明,该方法可以在CIFAR-10, CIFAR-100, SVHN和ImageNet数据集上达到了SOTA水平。
可以看出,要将NAS中的超参数自动调优的方法应用到其它领域,最关键的其实是搜索空间的定义和编码,而这个往往是领域相关的。其它的基本都可以沿用。可以预见,将来可能会被拓展到更多目前需要人工设计的部分。以后可能只要提供数据,从数据增强、到优化器、到网络结构、再到训练参数,都能全自动完成了。
参考博客:https://blog.csdn.net/jinzhuojun/article/details/84698471