2023年网络爬虫实训(第一天)
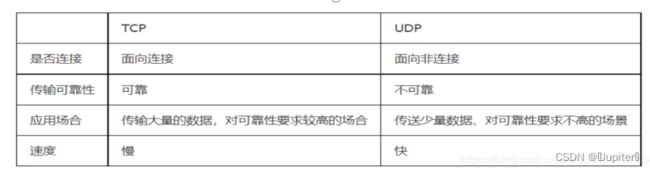
任务1:理解http协议。https协议,tcp协议。udp协议。掌握http的通讯过程。掌握客户端是如何获取respnse并展示数据的。

HTTP协议是建立在请求/响应模型上的。首先由客户建立一条与服务器的TCP链接,并发送一个请求到服务器,请求中包含请求方法、URI、协议版本以及相关的MIME样式的消息。服务器响应一个状态行,包含消息的协议版本、一个成功和失败码以及相关的MIME式样的消息。
HTTP/1.0为每一次HTTP的请求/响应建立一条新的TCP链接,因此一个包含HTML内容和图片的页面将需要建立多次的短期的TCP链接。一次TCP链接的建立将需要3次握手。
另外,为了获得适当的传输速度,则需要TCP花费额外的回路链接时间(RTT)。每一次链接的建立需要这种经常性的开销,而其并不带有实际有用的数据,只是保证链接的可靠性,因此HTTP/1.1提出了可持续链接的实现方法。HTTP/1.1将只建立一次TCP的链接而重复地使用它传输一系列的请求/响应 消息,因此减少了链接建立的次数和经常性的链接开销。
结论:虽然HTTP本身是一个协议,但其最终还是基于TCP的。
HTTP 一般是明文传输,很容易被攻击者窃取重要信息,鉴于此,HTTPS 应运而生。HTTPS 的全称为 (Hyper Text Transfer Protocol over SecureSocket Layer),全称有点长,HTTPS 和 HTTP 有很大的不同在于 HTTPS 是以安全为目标的 HTTP 通道,在 HTTP 的基础上通过传输加密和身份认证保证了传输过程的安全性。HTTPS 在 HTTP 的基础上增加了 SSL 层,也就是说 HTTPS = HTTP + SSL。
HTTP通信机制是在一次完整的HTTP通信过程中,Web浏览器与Web服务器之间将完成下列7个步骤:
1. 建立TCP连接
在HTTP工作开始之前,Web浏览器首先要通过网络与Web服务器建立连接,该连接是通过TCP来完成的,该协议与IP协议共同构建Internet,即著名的TCP/IP协议族,因此Internet又被称作是TCP/IP网络。HTTP是比TCP更高层次的应用层协议,根据规则,只有低层协议建立之后才能进行更高层协议的连接,因此,首先要建立TCP连接,一般TCP连接的端口号是80。
2. Web浏览器向Web服务器发送请求命令
一旦建立了TCP连接,Web浏览器就会向Web服务器发送请求命令。例如:GET/sample/hello.jsp HTTP/1.1。
3. Web浏览器发送请求头信息
浏览器发送其请求命令之后,还要以头信息的形式向Web服务器发送一些别的信息,之后浏览器发送了一空白行来通知服务器,它已经结束了该头信息的发送。
4. Web服务器应答
客户机向服务器发出请求后,服务器会客户机回送应答, HTTP/1.1 200 OK ,应答的第一部分是协议的版本号和应答状态码。
5. Web服务器发送应答头信息
正如客户端会随同请求发送关于自身的信息一样,服务器也会随同应答向用户发送关于它自己的数据及被请求的文档。
6. Web服务器向浏览器发送数据
Web服务器向浏览器发送头信息后,它会发送一个空白行来表示头信息的发送到此为结束,接着,它就以Content-Type应答头信息所描述的格式发送用户所请求的实际数据。
7. Web服务器关闭TCP连接
一般情况下,一旦Web服务器向浏览器发送了请求数据,它就要关闭TCP连接,然后如果浏览器或者服务器在其头信息加入了这行代码:Connection:keep-alive
TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。
任务2:完成http通讯协议部分的代码
import socket
import re
def for_client(client):
"""
服务客户端
实际上就是给连接进来的客户端页面的
"""
# 1.接受客户端的请求(数据) request : 涵盖客户端的一些信息
# 完整的请求包括状态行,请求头,请求体
request = client.recv(1024).decode('utf-8')
#print(request)
# 2. 对request进行基本的处理(splitlines(切割))
# 127.0.0.1:1243
# 127.0.0.1:1243/index.html
request_split_result = request.splitlines()
# print(request_split_result)
# 使用正则表达式进行字符串提取
patten = r'[^/]+([^ ]*)' # 正则表达式
patten_result = None
if len(request_split_result) > 0:
patten_result = re.match(patten, request_split_result[0])
#print(patten_result.group(1))
# 替换/
file_name = ''
if patten_result:
file_name = patten_result.group(1)
if file_name == "/":
file_name = "/index.html" # 替换
print(file_name)
# 根据获取的文件名(页面)到指定的路径中打开
# 打开文件
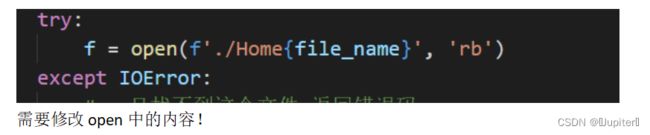
try:
f = open(f'index.html', 'rb')
except IOError:
# 一旦找不到这个文件,返回错误码
ERROR_CODE = '404'
#返回响应给客户端
# 完整的响应包括状态行,响应头,响应体
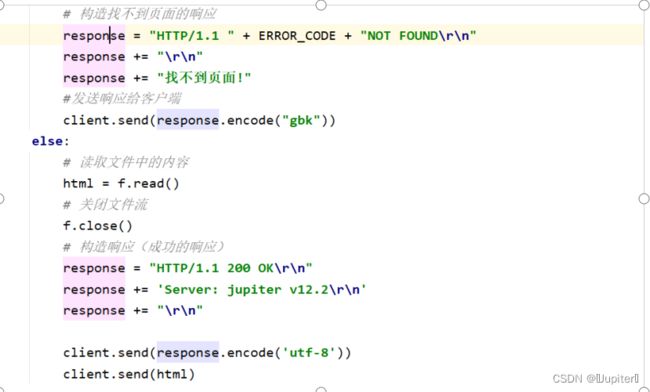
# 构造找不到页面的响应
response = "HTTP/1.1 " + ERROR_CODE + "NOT FOUND\r\n"
response += "\r\n"
response += "找不到页面!"
#发送响应给客户端
client.send(response.encode("gbk"))
else:
# 读取文件中的内容
html = f.read()
# 关闭文件流
f.close()
# 构造响应(成功的响应)
response = "HTTP/1.1 200 OK\r\n"
response += 'Server: jupiter v12.2\r\n'
response += "\r\n"
client.send(response.encode('utf-8'))
client.send(html) # 将HTML中的内容(常州工学院欢迎你 和 这就是首页的内容!)输出
if __name__ == '__main__':
print('===========================')
# 1.创建套接字
# 192.179.1.1 ipv4 => AF_INET
# ipv6 => AF_INET6
# socket 类型
# 1.socket.SOCK_STREAM => TCP(安全可靠)
# 2.socket.SOCK_DGRAM => UDP(传输快,可能丢失数据)
soc = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 总台
# 2. 绑定地址URL(ip + 端口号)
soc.bind(("", 1244))
# 3. 进入监听(被动)状态
soc.listen(128)
# 4. 模拟服务器开启状态
while True:
# 4.1 等待客户端的连接(等request) 阻塞(节省系统资源) -> 解决阻塞的方法是利用多线程
new_soc, client_info = soc.accept() # 阻塞 new_soc专门为客户服务的人
# 4.2 客户专员为连接进来的客户服务
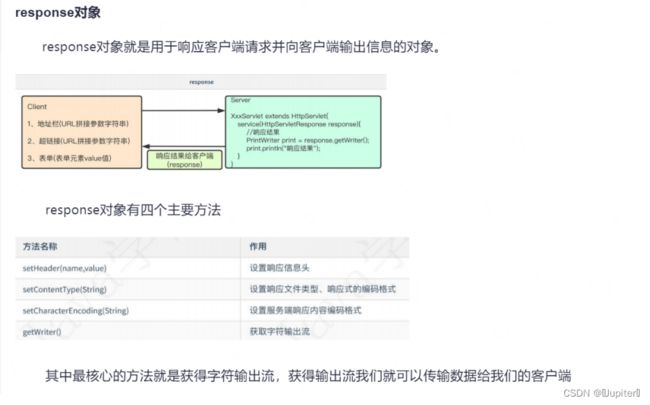
for_client(new_soc)任务3:完成任务2的基础上,掌握request对象的构成,以及response对象的构成,包括格式上的书写。重点掌握response对象。掌握服务器是如何返回html页面的原理。
request对象的构成:
完整的请求request包括状态行,请求头,请求体
request = client.recv(1024).decode('utf-8')
response对象:

服务器是如何返回html页面的原理:
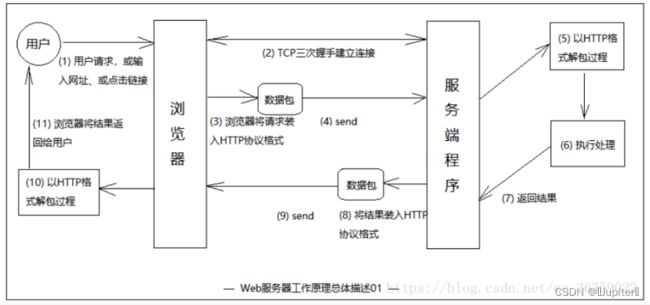
(1) 用户做出了一个操作,可以是填写网址敲回车,可以是点击链接,可以是点击按键等,接着浏览器获取了该事件。
(2) 浏览器与对端服务程序建立TCP连接。
(3) 浏览器将用户的事件按照HTTP协议格式打包成一个数据包,其实质就是在待发送缓冲区中的一段有着HTTP协议格式的字节流。
(4) 浏览器确认对端可写,并将该数据包推入Internet,该包经过网络最终递交到对端服务程序。
(5) 服务端程序拿到该数据包后,同样以HTTP协议格式解包,然后解析客户端的意图。
(6) 得知客户端意图后,进行分类处理,或是提供某种文件、或是处理数据。
(7) 将结果装入缓冲区,或是HTML文件、或是一张图片等。
(8) 按照HTTP协议格式将(7)中的数据打包
(9) 服务器确认对端可写,并将该数据包推入Internet,该包经过网络最终递交到客户端。
(10) 浏览器拿到包后,以HTTP协议格式解包,然后解析数据,假设是HTML文件。
(11) 浏览器将HTML文件展示在页面
Web服务器的本质就是 :接收数据 ⇒ HTTP解析 ⇒ 逻辑处理 ⇒ HTTP封包 ⇒ 发送数据
任务4:掌握谷歌浏览器的debug功能,掌握如何找到响应以及响应所在的地址(响应实际上就是数据所在的地方)