论文阅读:Convolutional Neural Networks for Sentence Classification 卷积神经网络的句子分类
Convolutional Neural Networks for Sentence Classification
卷积神经网络的句子分类
目录
- Convolutional Neural Networks for Sentence Classification
- 卷积神经网络的句子分类
-
- 摘要
- 1 引言
- 2 模型
-
- 2.1 正则化
- 3 数据集和实验设置
-
- 3.1 超参数和训练
- 3.2 预训练词向量
- 3.3 模型变体
- 4 结果与讨论
-
- 4.1 多通道与单通道模型
- 4.2 静态与非静态表示
- 4.3 进一步的观察
- 5 结论
摘要
我们报告了一系列在预训练词向量之上训练的卷积神经网络(CNN)实验,用于句子级分类任务。我们表明,几乎没有超参数调整和静态向量的简单CNN在多个基准上均能获得出色的结果。通过微调学习特定任务的向量可进一步提高性能。我们另外建议对体系结构进行简单的修改,以允许使用特定任务的向量和静态向量。本文讨论的CNN模型在7个任务中的4个改进了现有技术,其中包括情感分析和问题分类。
1 引言
近年来,深度学习模型在计算机视觉(Krizhevsky et al., 2012)和语音识别(Graves et al., 2013)中取得了显著成果。在自然语言处理中,深度学习方法的许多工作都涉及通过神经语言模型(Bengio et al., 2003; Yih et al., 2011; Mikolov et al., 2013)来学习词向量表示,并在学习的词向量进行分类(Collobert et al., 2011)。词向量本质上是特征提取,其将词从稀疏的V编码1(这里V是词汇量)通过隐藏层投影到较低维度的向量空间上,该特征提取对词在其维度上的语义特征进行编码。在这种密集表示中,语义上相近的词在较低维向量空间中也很相近(如欧几里得或余弦距离)。
卷积神经网络(CNN)利用带有卷积滤波器的图层应用于局部特征(LeCun et al., 1998)。 CNN模型最初是为计算机视觉而发明的,后来被证明对NLP有效,并且在语义解析(Yih et al., 2014)、搜索查询检索(Shen et al., 2014)、句子建模(Kalchbrenneret et al., 2014)和其他传统的NLP任务(Collobert et al., 2011)方面取得了优异的结果。
在目前的工作中,我们训练一个简单的CNN,从无监督神经语言模型得到的词向量的基础上进行一层卷积。这些向量由Mikolov et al.,(2013)训练关于Google新闻的1000亿个单词,并且已经公开可用。我们最初使词向量保持静态,仅学习模型的其他参数。尽管对超参数的调整很少,但这个简单的模型在多个基准上均能获得出色的结果,这表明预训练的向量是 “通用”特征提取,可用于各种分类任务。通过微调学习特定任务的向量可以进一步改进。最后,我们描述了对体系结构的简单修改,以允许通过具有多个通道使用预训练向量和特定任务的向量。
我们的工作在哲学上与Razavian et al. (2014)相似,这表明,对于图像分类,从预训练的深度学习模型中获得的特征提取在各种任务上表现良好,包括与训练特征提取的原始任务截然不同的任务。
2 模型
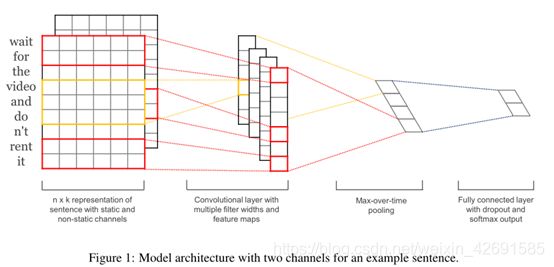
如图1所示,模型架构是Collobert et al. (2011)的CNN架构的细微变化。令xi∈Rk对应句子中第i个词的k维词向量。长度为n的句子表示为
![]()
其中⊕是串联运算符。通常,让xi:i + j代表单词xi,xi + 1,… ,xi + j的串联。卷积运算涉及一个滤波器w∈Rhk,该滤波器应用于h个单词的窗口以产生新特征。例如,例如,特征词ci是通过单词xi:i + h-1窗口生成的
![]()
其中b∈R是一个偏差项,f是一个非线性函数,例如双曲正切。该滤波器应用于句子{x1:h,x2:h + 1,… ,xn-h + 1:n}生成特征图
![]()
其中c∈Rn-h + 1。然后,我们在特征图上应用最大超时池化操作(Collobert et al., 2011),并将最大值ˆc = max {c}作为与该特定滤波器相对应的特征。这个想法是为每个特征图捕获最重要的特征——具有最高价值的特征。这种合并方案自然可以处理可变的句子长度。
我们已经描述了从一个滤波器中提取一个特征的过程。该模型使用多个滤波器(窗口大小各异)来获取多个特征。这些特征形成倒数第二层,并传递到完全连接的softmax层,其输出是标签上的概率分布。
在一种模型变体中,我们尝试使用两个词向量的“通道”,一个在整个训练过程中保持静态,另一个通过反向传播进行微调(第3.2节)。在多通道架构中,如图1所示,每个滤波器都应用于两个通道,并且将结果相加以通过公式(2)计算ci。该模型在其他方面等效于单通道体系结构。
2.1 正则化
为了进行正则化,我们在倒数第二层采用了权重向量的l2范数约束(Hinton et al., 2012)。在前向传播过程中,p比例的隐藏单元被随机dropout(如设置为0)避免了隐藏层的过拟合问题。也就是说,给定倒数第二层z = [ˆc1,… ,ˆcm](请注意,这里有m个滤波器),而不是使用
![]()
对于正向传播中的输出单元y,使用dropout
![]()
其中,◦是逐元素乘法运算符,r∈Rm是伯努利随机变量的“masking”向量,概率p为1。梯度只能通过unmasked单元反向传播。在测试时,将学习的权重向量按p进行缩放,使得ˆw = pw,并且使用ˆw(无dropout)对看不见的句子评分。通过在梯度下降步骤之后每当||w||2>s时,通过将w重新定标为||w||2 = s,我们进一步限制了权向量的l2-范数。
3 数据集和实验设置
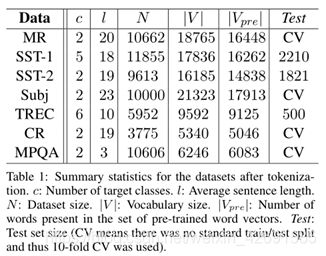
我们在各种基准上测试我们的模型。数据集的总结统计数据在表1中。
- MR:电影评论,每个评论一句话。分类涉及检测正面/负面评论(Pang and Lee, 2005)。
- SST-1:斯坦福情感树库(Stanford Sentiment Treebank)——MR的扩展,但提供了训练/验证/测试拆分和细粒度标签(非常正面、正面、中性、负面、非常负面),由Socher et al. (2013)重新标注。
- SST-2:与SST-1相同,但删除了中性评论,并添加了二进制标签。
- Subj:主观性数据集,任务是将句子分类为主观或客观(Pang and Lee, 2004)。
- TREC:TREC问题数据集——任务涉及将问题分为6个问题类型(问题是关于人、位置、数字信息等)(Li and Roth, 2002)。
- CR:各种产品的客户评论(相机、MP3s等)。任务是预测正面/负面评论(Hu and Liu, 2004)。
- MPQA:MPQA数据集的意见极性检测子任务(Wiebe et al., 2005)。
3.1 超参数和训练
对于所有数据集,我们使用:校正线性单位,3、4、5的滤波器窗口(h),每个具有100个特征图,滤除率(p)为0.5,l2约束(s)为3,最小批量大小为50。这些值是通过SST-2验证集上的网格搜索选择的。
除了尽早停止验证集外,我们不执行其他任何特定于数据集的调整。对于没有标准验证集的数据集,我们随机选择训练数据的10%作为验证集。训练是通过随机梯度后的mini-batches按照Adadelta更新规则进行的(Zeiler,2012)。
3.2 预训练词向量
在没有大型监督训练集的情况下,使用从无监督神经语言模型获得的词向量进行初始化是提高性能的一种流行方法(Collobert et al., 2011; Socher et al., 2011; Iyyer et al., 2014)。我们使用公开提供的word2vec向量,这些向量经过Google新闻1000亿个单词的训练。载体的维数为300,并使用连续词袋架构进行了训练(Mikolov et al., 2013)。在预训练的词集中不存在的词将随机初始化。
3.3 模型变体
我们尝试了模型的几种变体。
- CNN-rand:我们的基准模型,在训练过程中,所有单词均被随机初始化,然后进行修改。
- CNN-static:具有来自word2vec的预训练向量的模型。所有单词(包括随机初始化的未知单词)均保持静态,并且仅学习模型的其他参数。
- CNN-non-static:与上面相同,但是针对每个任务微调了预训练向量。
- CNN-multichannel:具有两组词向量的模型。每组向量均被视为“channel”,并且应用了每个滤波器到两个通道,但梯度仅通过其中一个通道反向传播。因此,该模型能够微调一组向量,同时保持另一组静态。两个通道都使用word2vec初始化。
为了消除上述变化与其他随机因素的影响,我们通过使它们在每个数据集中保持一致,消除了其他随机性来源——CV-fold分配、未知词向量的初始化、CNN参数的初始化。
4 结果与讨论

表2列出了针对其他方法的模型结果。我们的带有所有随机初始化的单词(CNN-rand)的基准模型不能很好地发挥自己的作用。尽管通过使用预训练的向量可以预期获得性能提升,但是我们对这种提升的幅度感到惊讶。即使是带有静态向量的简单模型(CNN-static)也会表现出色,与使用复杂池化方案的更复杂的深度学习模型(Kalchbrenner et al。,2014)或需要事先计算解析树的应用(Socher et al., 2013)。这些结果表明,经过预训练的向量是良好的“通用”特征提取,可以在数据集中使用。对每个任务的预训练向量进行微调会带来进一步的改进(CNN-non-static)。
4.1 多通道与单通道模型
我们最初希望多通道体系结构能够防止过拟合(通过确保学习的向量与原始值的偏差不会太远),从而比单通道模型更好地工作,尤其是在较小的数据集上。但是,结果参差不齐,因此有必要进一步进行正则化微调过程。例如,代替使用非静态部分的附加通道,可以保持单个通道但采用允许在训练期间进行修改的额外尺寸。
4.2 静态与非静态表示

与单通道非静态模型一样,多通道模型能够微调非静态通道,使其更适合手头的任务。例如,在word2vec中,好与坏最相似,大概是因为它们在语法上几乎是等效的。但是对于在SST-2数据集上微调的非静态通道中的向量,情况就不再如此(表3)。同样,在表达情感方面,good可以说更接近nice,而不是great,这确实反映在学习的向量中。对于不在预训练的向量集中的(随机初始化的)tokens,微调使它们能够学习更有意义的表示形式:这个网络知道感叹号与感情表达有关,逗号是连接词(表3)。
4.3 进一步的观察
我们报告了一些进一步的实验和观察结果:
- Kalchbrenner et al. (2014) 报道的CNN的架构与我们的单渠道模型基本相同,但效果却差得多。例如,他们的带有随机初始化单词的Max-TDNN(时延神经网络)在SST-1数据集上获得了37.4%,而在我们的模型中为45.0%。我们将这种差异归因于CNN具有更大的容量(多个滤波器宽度和特征图)。
- Dropout被证明是一个很好的正则化器,它可以使用一个比需要的更大的网络,并简单地让Dropout正则化它。Dropout始终增加2%-4%的相对性能。
- 当随机初始化不在word2vec中的单词时,我们通过从U [-a,a]采样每个维度(其中选择a)使随机初始化的向量具有与预训练向量相同的方差,从而获得了一些改进。在初始化过程中使用更复杂的方法来反映预训练向量的分布是否会带来进一步的改进,这将是很有趣的。
- 我们简短地尝试了由Collobert et al. (2011) 在Wikipedia训练的另一组公开可用的词向量上发现比word2vec的性能要好得多。尚不清楚这是否归因于Mikolov et al. (2013) 的架构或1000亿字的Google新闻数据集。
- Adadelta(Zeiler, 2012)得出的结果与Adagrad(Duchi et al., 2011)相似,但所需时间更少。
5 结论
在当前的工作中,我们描述了一系列基于word2vec之上的卷积神经网络的实验。尽管对超参数的调整很少,但具有一层卷积的简单CNN仍然表现出色。我们的结果增加了公认的证据,即词向量的无监督预训练是NLP深度学习的重要组成部分。