嵌套交叉验证 输出超参数
Cross-Validation also referred to as out of sampling technique is an essential element of a data science project. It is a resampling procedure used to evaluate machine learning models and access how the model will perform for an independent test dataset.
交叉验证(也称为“过采样”技术)是数据科学项目的基本要素。 它是一个重采样过程,用于评估机器学习模型并访问该模型对独立测试数据集的性能。
Hyperparameter optimization or tuning is a process of choosing a set of hyperparameters for a machine learning algorithm that performs best for a particular dataset.
超参数优化或调整是为机器学习算法选择一组超参数的过程,该算法对特定数据集的性能最佳。
Both Cross-Validation and Hyperparameter Optimization is an important aspect of a data science project. Cross-validation is used to evaluate the performance of a machine learning algorithm and Hyperparameter tuning is used to find the best set of hyperparameters for that machine learning algorithm.
交叉验证和超参数优化都是数据科学项目的重要方面。 交叉验证用于评估机器学习算法的性能,而超参数调整则用于为该机器学习算法找到最佳的超参数集。
Model selection without nested cross-validation uses the same data to tune model parameters and evaluate model performance that may lead to an optimistically biased evaluation of the model. We get a poor estimation of errors in training or test data due to information leakage. To overcome this problem, Nested Cross-Validation comes into the picture.
没有嵌套交叉验证的模型选择使用相同的数据来调整模型参数并评估模型性能,这可能导致对模型的乐观评估。 由于信息泄漏,我们对训练或测试数据中的错误的估计很差。 为了克服这个问题,嵌套交叉验证成为了图片。
Comparing the performance of non-nested and nested CV strategies for the Iris dataset using a Support Vector Classifier. You can observe the performance plot below, from this article.
使用支持向量分类器比较虹膜数据集的非嵌套和嵌套CV策略的性能。 您可以从本文观察下面的性能图。
什么是嵌套交叉验证及其实现?(What is Nested Cross-Validation and its Implementation?)
Nested Cross-Validation (Nested-CV) nests cross-validation and hyperparameter tuning. It is used to evaluate the performance of a machine learning algorithm and also estimates the generalization error of the underlying model and its hyperparameter search.
嵌套交叉验证( Nested-CV )嵌套交叉验证和超参数调整。 它用于评估机器学习算法的性能,还估计基础模型及其超参数搜索的泛化误差。
Apart from Nested-CV, there are several CV strategies, read the below-mentioned article to know more about different CV procedures.
除了Nested-CV,还有几种CV策略,请阅读下面提到的文章,以了解有关不同CV程序的更多信息。
步骤1:训练测试分组: (Step 1: Train Test Split:)
Split the given preprocessed dataset into train and test data, the training data can be used to train the model and testing data is kept as isolated to evaluate the performance of the final model.
将给定的预处理数据集分为训练和测试数据,训练数据可用于训练模型,测试数据保持隔离状态以评估最终模型的性能。

This is not a compulsory step, entire data can be used as training data. The split of data into train and test is essential to observe the performance of the model for unseen test data. Evaluating the final model with the test data says the performance of that model for future unseen points.
这不是强制性的步骤,可以将整个数据用作训练数据。 将数据分为训练和测试对于观察模型的性能(对于看不见的测试数据)至关重要。 用测试数据评估最终模型可以说明该模型在未来看不见的点上的性能。
第2步:外部简历: (Step 2: Outer CV:)
A machine learning algorithm is selected based on its performance on the outer loop of nested cross-validation. k-fold cross-validation or StaratifiedKfold procedure can be implemented for the outer loop depending on the imbalance of the data, to equally split the data into k-folds or groups.
根据其在嵌套交叉验证外循环上的性能来选择机器学习算法。 可以根据数据的不平衡性为外部循环执行k倍交叉验证或StaratifiedKfold过程,以将数据平均分为k倍或组。
k-fold CV: This procedure splits the data into k folds or groups. (k-1) groups will be assigned to train and the remaining group to validate data. This step is repeated for k-steps until all the groups participated in the validation data.
k折CV:此过程将数据分为k折或组。 (k-1)个小组将被分配训练,其余的小组将被验证数据。 重复此步骤k个步骤,直到所有组都参与验证数据。
StatifiedKfold CV: This procedure is similar to the k-fold CV. Here the dataset is partitioned into k groups or folds such that the validation and train data has an equal number of instances of target class label. This ensures that one particular class is not over present in the validation or train data especially when the dataset is imbalanced.
StatifiedKfold CV:此过程类似于k折CV。 在这里,数据集被分为k组或折叠,以使验证和训练数据具有相等数量的目标类标签实例。 这样可确保在验证或训练数据中不会出现一个特定的类,尤其是在数据集不平衡时。
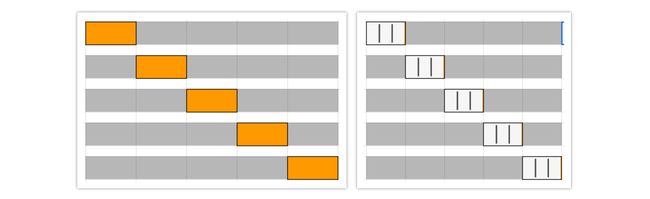
k-fold or Stratifiedkfold CV can be selected for outer-CV depending on the imbalance of the dataset.
可以根据数据集的不平衡性为外部CV选择k倍或Stratifiedkfold CV。
第3步:内部简历: (Step 3: Inner CV:)
Then the inner-CV is applied to the (k-1) folds or groups dataset from the outer CV. The set of parameters are optimized using GridSearch and is then used to configure the model. The best model returned from GridSearchCV or RandomSearchCV is then evaluated using the last fold or group. This method is repeated k times, and the final CV score is computed by taking the mean of all k scores.
然后将内部CV应用于外部CV的(k-1)折或组数据集。 使用GridSearch优化参数集,然后将其用于配置模型。 然后,使用最后的折叠或组评估从GridSearchCV或RandomSearchCV返回的最佳模型。 重复此方法k次,并通过取所有k个分数的平均值来计算最终CV分数。
步骤4:调整超参数: (Step 4: Tuning hyperparameter:)
The Scikit-learn package provides comes with GridSearchCV and RandomSearchCV implementation. These searching techniques return the best machine learning model by tuning the given parameters.
Scikit-learn软件包提供了GridSearchCV和RandomSearchCV实现。 这些搜索技术通过调整给定参数返回最佳的机器学习模型。
步骤5:拟合最终模型: (Step 5: Fit the Final Model:)
Now you have the best model and set of hyperparameters that perform best for that dataset. You can evaluate the performance of the model for unseen test data.
现在,您拥有了对该数据集表现最佳的最佳模型和超参数集。 您可以为看不见的测试数据评估模型的性能。
Python实现: (Python Implementation:)
Credit Card Fraud Dataset is used in the below implementation downloaded from Kaggle.
从Kaggle下载的以下实现中使用了信用卡欺诈数据集。
import pandas as pd
from sklearn.model_selection import KFold, StratifiedKFold, GridSearchCV, train_test_split
from sklearn.linear_model import LogisticRegression
data = pd.read_csv("creditcard.csv")
y = data["Class"]
X = data.drop("Class", axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=7)
cv_outer = StratifiedKFold(n_splits=5, random_state=7)
for train_idx, val_idx in tqdm(cv_outer.split(X_train, y_train)):
train_data, val_data = X_train.iloc[train_idx], X_train.iloc[val_idx]
train_target, val_target = y_train[train_idx], y_train[val_idx]
model = LogisticRegression(random_state=7)
cv_inner = StratifiedKFold(n_splits=3, random_state=7)
params = {'penalty': ['l1', 'l2'], 'class_weight': [None, 'balanced'], 'C': [10**x for x in range(-3,5)]}
gd_search = GridSearchCV(model, params, scoring='roc_auc', n_jobs=-1, cv=cv_inner).fit(train_data, train_target)
best_model = gd_search.best_estimator_
classifier = best_model.fit(train_data, train_target)
y_pred_prob = classifier.predict_proba(val_data)[:,1]
auc = metrics.roc_auc_score(val_target, y_pred_prob)
print("Val Acc:",auc, "Best GS Acc:",gd_search.best_score_, "Best Params:",gd_search.best_params_)
# Training final model
model = LogisticRegression(random_state=7, C=0.001, class_weight='balanced', penalty='l2').fit(X_train, y_train)
y_pred_prob = model.predict_proba(X_test)[:,1]
print("AUC", metrics.roc_auc_score(y_test, y_pred_prob))
print(metrics.confusion_matrix(y_test, y_pred))巢式简历的费用:(Cost of Nested-CV:)
Using Nested-CV dramatically increases the training and evaluation of models. If n*k models are trained for non-nested CV, then the number of models to be trained increases to k*n*k.
使用Nested-CV可以极大地增加模型的训练和评估。 如果为非嵌套CV训练了n * k个模型,则要训练的模型数将增加到k * n * k。
结论: (Conclusion:)
When the same dataset is used to both tune and select a model using CV, it is likely to lead to an optimistically biased evaluation of the model performance. So, Nested-CV is used over non-nested CV because it helps to overcome the bias.
当使用同一数据集通过CV调整和选择模型时,很可能导致对模型性能的乐观评估。 因此,嵌套CV优于非嵌套CV,因为它有助于克服偏差。
Using nested-CV dramatically increases the number of model evaluations, and hence increasing the time complexity. It is not recommended when the dataset is too large or your system is not powerful.
使用嵌套CV会大大增加模型评估的数量,从而增加时间复杂度。 当数据集太大或系统功能不强大时,不建议使用。
Thank You for Reading
谢谢您的阅读
翻译自: https://towardsdatascience.com/nested-cross-validation-hyperparameter-optimization-and-model-selection-5885d84acda
嵌套交叉验证 输出超参数