ResNet模型简介,Tensorflow2与Pytorch的实现
ResNet模型简介
1.网络结构
网络越深,获取的信息就越多,特征也越丰富,但是随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了。ResNet 开创性地引入了残差连接,解决了深层网络训练过程中的梯度弥散问题,是深层模型更容易训练,并且验证了随着网络层次的加深模型可以获得更好的性能。
特点
- 引入直连通路,使深层模型可以保持原始数据信息且训练过程不容易梯度弥散
- 直连通路与卷积层进行合并时采用元素点相加的方式,而不是直接拼接(Concatenate),使模型在训练过程中只需要拟合不同层网络中输出值与输入值的残差值,而无需直接拟合网络输出值,降低了模型训练难度。
- 残差块中模型 Inception,将 3x3 卷积拆分成两个 1x1 和 一个 3x3 组合,减少了模型参数量。
(1).残差块
假设 F(x) 代表某个只包含有两层的映射函数, x 是输入, F(x)是输出。假设他们具有相同的维度。在训练的过程中我们希望能够通过修改网络中的 w和b去拟合一个理想的 H(x)(从输入到输出的一个理想的映射函数)。也就是我们的目标是修改F(x) 中的 w和b逼近 H(x) 。如果我们改变思路,用F(x) 来逼近 H(x)-x ,那么我们最终得到的输出就变为 F(x)+x(这里的加指的是对应位置上的元素相加,也就是element-wise addition),这里将直接从输入连接到输出的结构也称为shortcut,那整个结构就是残差块,ResNet的基础模块。

ResNet沿用了VGG全3×3卷积层的设计。残差块里首先有2个有相同输出通道数的3×3卷积层。每个卷积层后接BN层和ReLU激活函数,然后将输入直接加在最后的ReLU激活函数前,这种结构用于层数较少的神经网络中,比如ResNet34。若输入通道数比较多,就需要引入1×1卷积层来调整输入的通道数,这种结构也叫作瓶颈模块,通常用于网络层数较多的结构中。如下图所示:
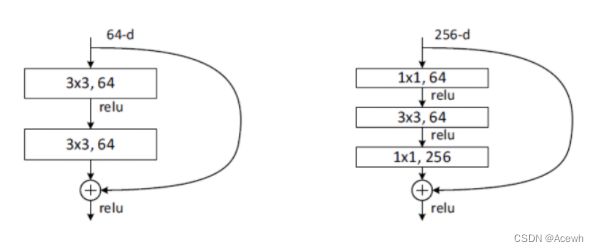
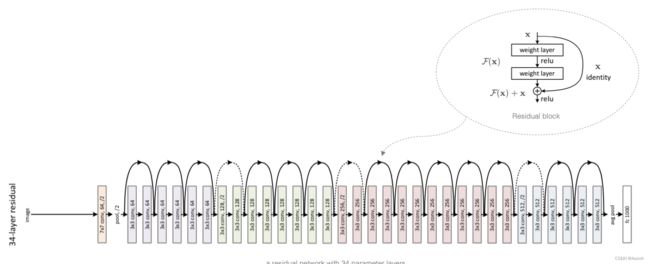
(2).ResNet34整体结构
每个ResentBlock模块里有多个个卷积层(不计算 1×1卷积层),这些卷积层加上最开始的卷积层和最后的全连接层,共计34层,所以这个模型被称为ResNet34。
2.TF2实现
import tensorflow as tf
from tensorflow.keras.layers import *
# 1.残差块
class Residual(tf.keras.Model):
def __init__(self, num_fliters, use_1x1conv=False, strides=1):
super(Residual, self).__init__()
self.conv1 = Conv2D(num_fliters, padding='same', kernel_size=3, strides=strides)
self.conv2 = Conv2D(num_fliters, kernel_size=3, padding='same')
if use_1x1conv:
self.conv3 = Conv2D(num_fliters, kernel_size=1, strides=strides)
else:
self.conv3 = None
self.bn = BatchNormalization()
self.ac = ReLU()
def call(self, x):
y = self.ac(self.bn(self.conv1(x)))
y = self.bn(self.conv2(y))
if self.conv3 is not None:
x = self.conv3(x)
outputs = self.ac(y + x)
return outputs
# 2.Resent模块
class ResentBlock(tf.keras.layers.Layer):
def __init__(self, num_filters, num_res, first_block=False):
super(ResentBlock, self).__init__()
self.listLayers = []
# 遍历残差数目生成模块
for i in range(num_res):
# 如果是第一个残差块而不是模块时
if i == 0 and not first_block:
self.listLayers.append(Residual(num_filters, use_1x1conv=True, strides=2))
else:
self.listLayers.append(Residual(num_filters))
def call(self, X):
for layer in self.listLayers:
X = layer(X)
return X
# 3.Resent模型
class ResNet(tf.keras.Model):
def __init__(self, num_blocks):
super(ResNet, self).__init__()
# 输入层
self.conv = Conv2D(64, kernel_size=7, strides=2, padding='same')
self.bn = BatchNormalization()
self.relu = tf.keras.layers.Activation('relu')
self.mp = MaxPool2D(pool_size=3, strides=2, padding='same')
# 残差层
self.res_block1 = ResentBlock(64, num_blocks[0], first_block=True)
self.res_block2 = ResentBlock(128, num_blocks[1])
self.res_block3 = ResentBlock(256, num_blocks[2])
self.res_block4 = ResentBlock(512, num_blocks[3])
# GAP
self.gap = tf.keras.layers.GlobalAvgPool2D()
self.fc = Dense(10, activation='softmax')
def call(self, inputs):
x = self.conv(inputs)
x = self.bn(x)
x = self.relu(x)
x = self.mp(x)
x = self.res_block1(x)
x = self.res_block2(x)
x = self.res_block3(x)
x = self.res_block4(x)
x = self.gap(x)
x = self.fc(x)
return x
resnet18 = ResNet([2, 2, 2, 2])
X = tf.random.uniform((1, 224, 224, 3))
y = resnet18(X)
resnet18.summary()
Model: "res_net"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) multiple 9472
_________________________________________________________________
batch_normalization (BatchNo multiple 256
_________________________________________________________________
activation (Activation) multiple 0
_________________________________________________________________
max_pooling2d (MaxPooling2D) multiple 0
_________________________________________________________________
resent_block (ResentBlock) multiple 148224
_________________________________________________________________
resent_block_1 (ResentBlock) multiple 525952
_________________________________________________________________
resent_block_2 (ResentBlock) multiple 2100480
_________________________________________________________________
resent_block_3 (ResentBlock) multiple 8395264
_________________________________________________________________
global_average_pooling2d (Gl multiple 0
_________________________________________________________________
dense (Dense) multiple 5130
=================================================================
Total params: 11,184,778
Trainable params: 11,180,810
Non-trainable params: 3,968
_________________________________________________________________
3.PyTorch实现
import torchvision.models as models
from torchsummary import summary
resnet18 = models.resnet18()
print(resnet18)
summary(resnet18.cuda(),(3,224,224))
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2d-5 [-1, 64, 56, 56] 36,864
BatchNorm2d-6 [-1, 64, 56, 56] 128
ReLU-7 [-1, 64, 56, 56] 0
Conv2d-8 [-1, 64, 56, 56] 36,864
BatchNorm2d-9 [-1, 64, 56, 56] 128
ReLU-10 [-1, 64, 56, 56] 0
BasicBlock-11 [-1, 64, 56, 56] 0
Conv2d-12 [-1, 64, 56, 56] 36,864
BatchNorm2d-13 [-1, 64, 56, 56] 128
ReLU-14 [-1, 64, 56, 56] 0
Conv2d-15 [-1, 64, 56, 56] 36,864
BatchNorm2d-16 [-1, 64, 56, 56] 128
ReLU-17 [-1, 64, 56, 56] 0
BasicBlock-18 [-1, 64, 56, 56] 0
Conv2d-19 [-1, 128, 28, 28] 73,728
BatchNorm2d-20 [-1, 128, 28, 28] 256
ReLU-21 [-1, 128, 28, 28] 0
Conv2d-22 [-1, 128, 28, 28] 147,456
BatchNorm2d-23 [-1, 128, 28, 28] 256
Conv2d-24 [-1, 128, 28, 28] 8,192
BatchNorm2d-25 [-1, 128, 28, 28] 256
ReLU-26 [-1, 128, 28, 28] 0
BasicBlock-27 [-1, 128, 28, 28] 0
Conv2d-28 [-1, 128, 28, 28] 147,456
BatchNorm2d-29 [-1, 128, 28, 28] 256
ReLU-30 [-1, 128, 28, 28] 0
Conv2d-31 [-1, 128, 28, 28] 147,456
BatchNorm2d-32 [-1, 128, 28, 28] 256
ReLU-33 [-1, 128, 28, 28] 0
BasicBlock-34 [-1, 128, 28, 28] 0
Conv2d-35 [-1, 256, 14, 14] 294,912
BatchNorm2d-36 [-1, 256, 14, 14] 512
ReLU-37 [-1, 256, 14, 14] 0
Conv2d-38 [-1, 256, 14, 14] 589,824
BatchNorm2d-39 [-1, 256, 14, 14] 512
Conv2d-40 [-1, 256, 14, 14] 32,768
BatchNorm2d-41 [-1, 256, 14, 14] 512
ReLU-42 [-1, 256, 14, 14] 0
BasicBlock-43 [-1, 256, 14, 14] 0
Conv2d-44 [-1, 256, 14, 14] 589,824
BatchNorm2d-45 [-1, 256, 14, 14] 512
ReLU-46 [-1, 256, 14, 14] 0
Conv2d-47 [-1, 256, 14, 14] 589,824
BatchNorm2d-48 [-1, 256, 14, 14] 512
ReLU-49 [-1, 256, 14, 14] 0
BasicBlock-50 [-1, 256, 14, 14] 0
Conv2d-51 [-1, 512, 7, 7] 1,179,648
BatchNorm2d-52 [-1, 512, 7, 7] 1,024
ReLU-53 [-1, 512, 7, 7] 0
Conv2d-54 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-55 [-1, 512, 7, 7] 1,024
Conv2d-56 [-1, 512, 7, 7] 131,072
BatchNorm2d-57 [-1, 512, 7, 7] 1,024
ReLU-58 [-1, 512, 7, 7] 0
BasicBlock-59 [-1, 512, 7, 7] 0
Conv2d-60 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-61 [-1, 512, 7, 7] 1,024
ReLU-62 [-1, 512, 7, 7] 0
Conv2d-63 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-64 [-1, 512, 7, 7] 1,024
ReLU-65 [-1, 512, 7, 7] 0
BasicBlock-66 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-67 [-1, 512, 1, 1] 0
Linear-68 [-1, 1000] 513,000
================================================================
Total params: 11,689,512
Trainable params: 11,689,512
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 62.79
Params size (MB): 44.59
Estimated Total Size (MB): 107.96
----------------------------------------------------------------
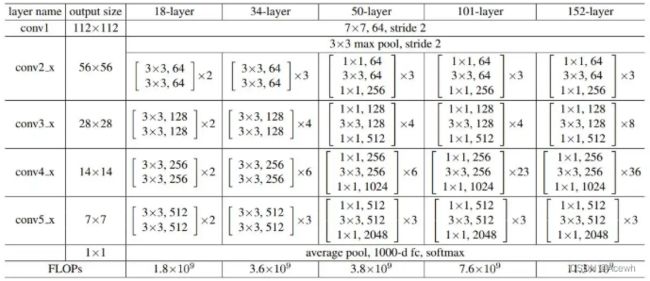
4.实现其他版本
其它版本ResNet就是每个ResentBlock模块里的卷积数量不同,具体差别如下:
import torchvision.models as models
from torchsummary import summary
import tensorflow as tf
resnet18 = models.resnet18()
resnet34 = models.resnet34()
resnet50 = models.resnet50()
resnet101 = models.resnet101()
resnet152 = models.resnet152()
resnet50 = tf.keras.applications.resnet50.ResNet50(
include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
**kwargs
)
resnet101 = tf.keras.applications.resnet.ResNet101(
include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
**kwargs
)
resnet152 = tf.keras.applications.resnet.ResNet152(
include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
**kwargs
)