swin-transformer 细节理解之整体架构
swin-transformer整体架构
文章目录
- swin-transformer整体架构
- 前言
- 一、整体介绍
- 二、整体流程解读
- 与卷积网络的对比(仅个人理解)
- 总结
- 参考链接
前言
这篇博客会大致介绍swin-transformer的整体架构,在不考虑transformer里的细节的前提下,如何从一个宏观的角度理解swin-transformer的整体架构,以及transformer网络架构为什么能代替传统的卷积网络。swin-transformer的官方代码链接: 官方链接
一、整体介绍
Swin-transformer在目标检测中主要作为网络骨架的backbone部分,官方给出的mask_rcnn_swin_tiny网络中Swin-transformer作为模型backbone只代替了传统mask_rcnn中的Resnet101模块,网络中neck与head模块均与传统mask_rcnn一致。
Swin-transformer的核心思想就是将特征图分割为无数固定大小(默认7×7)的窗口(patch), 在每一个窗口内部做自注意(self-attention),接着移动所有窗口的位置,再做一次自注意,实现全局参数(global parameter)的共享,以此代替传统的卷积操作。
下图为网络的整体结构:
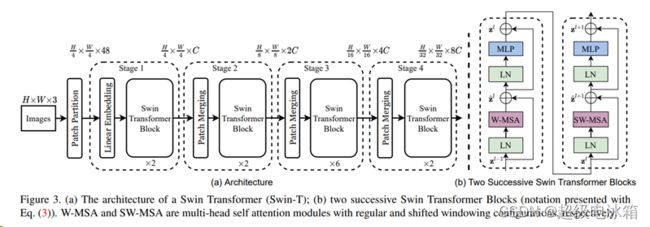
图片链接: https://arxiv.org/pdf/2103.14030.pdf
二、整体流程解读
首先输入图片经过patch partition层与Linear embedding层。patch partition层主要是将图片的w与h缩小4倍,Linear embedding则是将channel数变为固定的96。这两部分操作在代码中整合为patch projection操作,具体就是一次卷积:
nn.Conv2d(in_chans, 96, kernel_size=4, stride=4)
接着进入Swin-transformer block。我们不妨先把这个block看做一个黑匣子,不关注内部复杂的细节,关注通过block的输入与输出。通过debug发现,经过block的输入与输出维度一致。
接着进入patch merging。在这层中,假设输入的数据x的维度(B, H, W, C), 先将数据x通过H与W维度方向分半切割为x0, x1, x2, x3, 维度都为(B, H/2, W/2, C),具体代码:
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
再按C维度方向链接x0, x1, x2, x3,代码:
x = torch.cat([x0, x1, x2, x3], -1)
这样数据维度变为(B, H/2, W/2, 4*C),之后view数据后通过normalization与 一个linear层后输出。其中linear层代码为:
nn.Linear(4 * dim, 2 * dim, bias=False)
就是说channel数减半,从4C降为2C。综上,输入(B, H, W, C)的数据通过patch merging层后,输出维度为(B, H/2, W/2, 2*C)。
之后网络重复上述操作,再通过3个Swin-transformer block层与2个patch merging层,直到backbone部分结束。
与卷积网络的对比(仅个人理解)
从宏观角度看这个网络结构,不妨可以把patch partition层与Linear embedding层看做图片的预处理操作(post-processing),Swin-transformer block看做convolutional block,patch merging看pooling+norm,这不就是一个标准的卷积网络吗。之说以这样说,是因为卷积操作的目的是提取图像的特征,这与self-attention的目的一致,通过自注意权重提取图片特征。自注意窗口的移动很像卷积中卷积核的移动,实现全局参数共享。Pooling层的目的在于抽取图片更高层的特征,加大感受野(Receptive Field),patch merging目的与其一致,并且实现步骤也十分相似,下降数据W与H维度,增大通道数C。
总结
这篇博客只是大致介绍swin-transformer的整体架构,把Swin-transformer block当做黑匣子,没有研究其内部结构。下篇博客我们将进入Swin-transformer block,了解其流程。
参考链接
https://arxiv.org/pdf/2103.14030.pdf
沐神论文精读之swin-transformer