《CalliGAN: Style and Structure-aware Chinese Calligraphy Character Generator》论文笔记
关于《CalliGAN: Style and Structure-aware Chinese Calligraphy Character Generator》的论文笔记。
原文:Calligan: Style and structure-aware chinese calligraphy character generator
摘要:
中国书法是用毛笔书写汉字的一种艺术形式,因此汉字具有丰富的形状和细节。最近的研究表明,汉字可以通过图像到图像的翻译,用一个单一的模型来生成多种风格的汉字。我们提出了一种新颖的方法,将汉字的笔画信息纳入其模型。我们还提出了一个改进的网络来将汉字转换到它们的嵌入空间。实验结果表明,该方法能够生成高质量的书法汉字。
1、引言:
汉字是为书写中文而发展来的逻辑符号。与字母表不同,每个汉字都有自己的含义和完整的发音。汉字发明于几千年前,最初是刻在动物骨头或龟甲上的文字。大约公元前300年,人们发明了毛笔。秦朝时期(公元前221年至公元前206年),汉字首次标准化,称为秦书。此后,在漫长的历史长河中,它们又发展成隶书、楷书、半草书、草书等不同的形式。
中国书法有着悠久的历史,是中国文化的国粹。书法家在用毛笔书写汉字的同时,也将自己的艺术表现力体现在创作中。因此,每一个毛笔字的形象都像一幅画一样独特而不规则。在合同中,字体是由公司创建的,字体渲染的图像通常包含一些常见的区域,比如偏重字体。此外,不同的字体包含不同数量的字符。例如,广泛使用的中文字型Sim Sun版本5.16涵盖了28762个Unicode字符,而其0.90版本的扩展包涵盖了42809个罕见的字符。
但有些字体只覆盖有限数量的字符。毛笔字,特别是名作,还有一个问题,如果纸张和石碑腐烂,一些毛笔字就会变得模糊不清或损坏。许多字的缺失,限制了书法初学者模仿名作,也限制了设计者使用大师的作品。因此,我们有必要产生像图1那样的字符图像,目前许多方法已经用来解决这个问题了。

由于汉字是高度结构化的,早期发展的一些方法使用采用拆分合并的方法,将一个汉字分解成笔画,然后将每个笔画的合成再生成对应的一个书法汉字[31,29]。但该方法存在结构复杂的汉字难以自动分解的缺陷,并且需要手动分解某些样式,比如草书[30]。
随着神经网络和计算机视觉技术的发展,一项名为“风格转换”的研究取得了显著的成功,该研究旨在将画家的艺术风格添加到相机捕捉的照片中。风格转换逐渐演变为图像到图像的转换[10,34,32,14,17,24,3],其目的不仅是为目标图像添加风格细节,还包括对象从一个域到另一个域的转换,如马到斑马,反之亦然。由于中国书法家在笔画形式上各有自己的风格,产生书法汉字可以看作是汉字风格的域间转化。
一种中文字体可以很容易地渲染许多字符图像。给定两种字体,我们可以很容易地获得无数排列整齐的字符对。因此,通过训练图像到图像的翻译模型来生成字符是一种实用的方法,该方法生成的字符质量为最先进的[2]。与字体呈现的字符图像相比,毛笔书写的字符图像更加不规则。此外,它们需要花费时间和精力来创建。据我们所知,目前还没有明确定义的毛笔书法图像数据集,只有一篇现有的论文使用毛笔书法字符图像来进行实验[18]。本文是第二篇来处理这种图像类型。
利用毛笔书写的图像,提出了一种多风格图像-图像转换的方法。我们把风格定义为书法家的身份。如果一个书法家在不同的创作时期有不同的风格,我们就为这个书法家定义多个风格标签。为了验证所开发的方法,我们将与现有方法进行比较。综上所述,本文有两个贡献:
- 现有的多字体汉字生成方法是针对不同字体的汉字生成而设计的,本文是第一个在细粒度上处理样式的方法。此外,本文是第二篇毛笔书法图像转换的论文。我们的代码和数据集是公开的,可以帮助研究人员复现我们的结果。
- 该方法采用了一种新颖的组件编码器。据我们所知,该方法是第一个将汉字分解成构件并通过循环神经网络进行编码的方法。提出的方法生成了很好的图像,从而获得了良好的数字评价和主观意见。
2、相关工作:
在文献中,有许多方法可以生成 汉字图像。本文提出的方法将汉字生成视为一个图像到图像的翻译问题,我们将对其相关工作进行如下讨论。
Image-to-image翻译。图像到图像的转换是一种视觉和图形问题。它的目的是学习输入图像和输出图像之间的映射函数。使用这种技术的应用范围很广,如风格转移,物体更换,季节转移,或照片增强。
已经发表了许多图像到图像的翻译方法,其中大多数基于GAN,cGAN [10, 34, 3, 4]。Pix2pix[10]是第一个能够进行图像到图像转换的方法。之前基于神经网络的风格转换方法不同,它从一组目标图像中提取风格表示,这有助于pix2pix生成比风格传递方法更好的图像。此外,其基于gan的对抗损失防止了输出图像的模糊,其图像质量优于大多数基于编码器-解码器的方法[8]。
Pix2pix使用U-Net[21]作为它的生成器,它由一个图像编码器和一个解码器组成。它们之间存在跳跃连接,使视觉信息贯穿各个层。Pix2pix使用L 1范数的像素级损失来减少输出图像和训练图像之间的差异。
pix2pix的局限性之一是它需要成对的图像来训练其模型。这些配对图像在某些应用中很容易获得,如照片到草图的转换,但在其他应用中却很难获得成对的数据,如物体替换。CycleGAN[34]提出了在一个模型内用两个GAN来克服这个问题。一个GAN的输出是另一个GAN的输入,反之亦然。两个GAN同时学习图像分布,因此它们可以使用两组训练图像,而不是配对的图像。
然而,CycleGAN只能处理一个目标域。为了生成多个域的图像,需要单独训练多个模型。StarGAN[3]被提出来解决这个问题。它引入了一个辅助域分类器和一个分类损失来实现单一模型的多域转换。提出的CalliGAN的图像生成器类似于pix2pix,CalliGAN可以像Star-GAN一样处理多类图像间的转换。
汉字的生成。Zi2zi[25]是第一个使用GANs生成汉字的方法。它将一种源字体的字符图像翻译成多个目标字体。zi2zi基于pix2pix,自适应AC-GAN的[20]辅助分类器的基础上,实现多种样式的生成。DTN的[24]一致性损失(constancy loss),提高输出质量。Zi2zi的输出字体由一个形成为单一热向量的类参数控制,并通过嵌入转换为一个潜向量。
Zi2zi是一个开源项目,但从未以论文或技术报告的形式发表。第一篇使用GANs生成中国书法汉字的论文是AEGG[18],同样基于pix2pix,但增加了一个额外的编解码器网络,在训练过程中提供监督信息。与可以生成多类图像的zi2zi不同,AEGG只支持单类的字符生成。
DCFont[11]和PEGAN[23]都是从zi2zi修改而来,从数百个训练样本中生成GB2312字体库中使用的全部6763个汉字。PEGAN通过引入多尺度图像金字塔来通过细化连接传递信息来改进zi2zi,而DCFont则整合了预先训练过100种字体的样式分类器来获得更好的样式表示。SCFont[12]通过调整笔画提取算法[16]进一步改进了DCFont,以保持从输入图像到输出图像的笔画结构。
与学习给定字体之间的翻译模型相比,EMD[33]和SA-V AE[22]都将内容和风格分离为两个不相关的领域,并使用两个独立的编码器来为它们建模。然而,它们的技术细节是不同的。EMD在一个双线性混合器网络中混合风格和内容的潜在特征,通过图像解码器生成输出图像通过一个图像解码器。因此,它的训练样本是非常特殊的。一个样本由两组训练图像组成,一组用于内容,另一组用于风格。与此相反。SA-VAE采用了一种连续的方法。首先从给定的图像中识别字符,然后将识别的字符编码为特殊的代码,这些代码代表12个高频汉字的结构配置和101个高频字根。SA-VAE表明,汉字的结构知识有助于提高输出图像质量。
所提出的CalliGAN方法与现有方法有两个共同点。首先,CalliGAN是一种基于gan的方法,就像zi2zi、AEGG、DCFont和PEGAN。其次,他利用了中国汉字结构的先验知识,比如SA-VAE。CalliGAN和SA-VAE的一个明显区别是利用汉字结构的方式。SA-V AE只使用汉字的构型和部首,这是高层次的结构信息,而CalliGAN将汉字完全分解成部件,提供低层次的结构信息,包括笔画的顺序。简而言之,CalliGAN整合了生成真实图像的GANs和保留字符结构的SA-VAE的优点。
3、文章方法:
一个汉字可以表现为多种风格,这取决于书写的字体和书法家。因此,许多图像可以代表同一个字符。我们提出的方法旨在学习一种从给定字符生成具有期望样式的汉字图像的方法。设h是由Unicode等系统编码的字符代码,s是样式标签,y是在样式s下表示h的图像。我们通过一个给定的中文字体渲染一个图像x。因此,x的样式被指定。我们使用成对的图像集{x}和{y}来训练我们的网络将字体渲染的图像转换为书法家写的图像。
整体框架,图二显示了所提出的方法的体系结构。给定h, 我们通过给定的中文字体渲染一个图像x,然后通过图像编码器Ei对x进行编码,生成一个图像特征向量vi。同时, 同时,我们查阅字典T,获得h的结构序列c,通过编码器Ec生成结构特征向量vc。我们将参考图像y的样式标签s转换为一个有效编码向量vs.我们将vc、vi和vs串联起来作为输入特征向量,以生成书法字符图像ˆy。
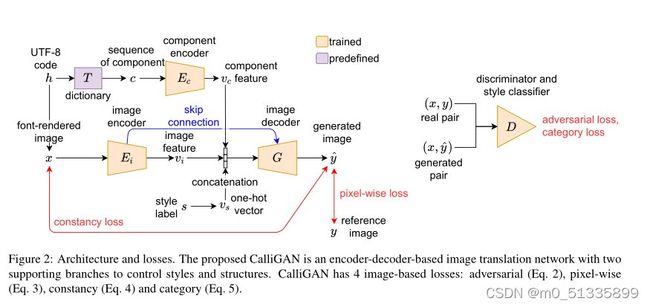
图像编码器和解码器。我们使用U-Net[21]作为我们的编码器-解码器架构,其方式类似于两种现有的图像转换方法——pix2pix和zi2zi[10,25]。因为中国书法大多是用黑色墨水表现的,所以我们假设我们的图像是没有颜色的灰度图。因此,我们稍微修改了U-Net的架构,将输入和输出图像的通道数从3个减少到1个。由于我们的图像解码器G需要vs和vc作为额外的输入数据,我们延长了G的输入向量的长度。表1显示了提议的架构。

组件编码器。汉字是由基本笔画和点的单位。它们的相对位置和交叉点形成了许多部件,每个部件都由一些特定形状的笔画和点组成。这就是汉字高度结构化的原因,也是我们开发方法所利用的特性。图3显示了一些部件的例子。我们使用一个公开的汉字分解系统,即中国标准交换码,它定义了517个汉字部件。给定一个字符h,我们使用该系统来获得其部件序列
![]()

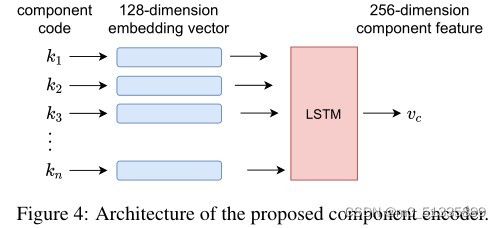
其中n为c的长度,由h决定。为了将可变长度序列c转换为定长特征向量vc,我们提出了一个序列编码器,如图4所示,该编码器包含嵌入层和LSTM模型。嵌入层将构件码转换为128维的嵌入向量,将其输入到LSTM模型中,生成结构特征向量vk。这些嵌入向量在我们的训练过程中自动优化。我们随机初始化LSTM模型。
鉴别器和辅助风格分类器。我们的鉴别器和辅助风格分类器除了输入层的channel number of input外,几乎与使用zi2zi的鉴别器和辅助风格分类器相同。它的架构如表2所示。鉴别器和辅助风格分类器共享前三层,并拥有独立的第四层。

Losses.我们定义了4种损失来训练我们的模型。条件GAN的对抗性损失
![]()
是用来帮助我们生成的图像看起来真实。为了使生成的图像与训练的图像相似,我们使用像素级损失:
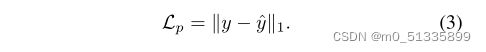
因为输入图像x和输出图像ˆy代表相同的字符,所以我们采用与[24,25]相同的方法使用一致性损失。
![]()
这促使两幅图像具有相似的特征向量。生成的图像应该保留生成图像风格,因此我们定义了类别损失:

我们总的损失函数:
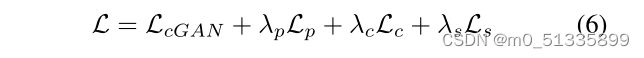
其中,λp, λc, λs为参数,用于控制各损失的相对重要性。
4. 实验
为了编制一个图像集来进行实验,我们从一个中国书法图像库中下载图像。所有的图像都是由专家模仿古代的杰作用笔写成的,或者是由艺术字体呈现的。该资源库涵盖了29种书法风格。其中一些属于定义明确的楷书、半草书和隶书,但其余的没有被归类。我们选择了属于楷书的7种风格来进行实验,它们的名称是
1. 褚遂良。
2. 柳公权。
3. 欧阳询《皇甫诞碑》
4. 欧阳询《九成宫醴泉铭》。
5. 颜真卿《多宝塔碑》。
6. 颜真卿《颜真卿勤礼碑》。
7. 汝南

第3、4种风格是同一古代书法家欧阳询在其早年和晚年创作的。因为书法家风格的变化,我们把它们当作两种不同的风格,这也是中国书法界的经验法则。第五和第六种也属于同一作家书写但不同的风格。图5显示了7种风格的例子。7种风格的例子。每种风格都有几千张图片,但同一风格下的一些图片可能代表同一个字。我们总共收集了47552张图片,涵盖了6548个不同的字符,但只有5560个 但只有5560个字符在所有7种风格中都可用。表3显示了 他们的统计数据。我们从5560个常用字符中随机抽取1000个字符作为测试字符集。并有7737张测试图像。我们使用剩余的39815张 图像来训练我们的模型。

资源库的图像大小取决于字符的形状,但长边是固定的140像素。我们保持它的长宽比,并通过Lanczos重采样将长边放大到256像素。我们将放大后的图像放在中心,并填充两个短边,生成一个256×256像素的正方形图像,作为我们的真实图像y。储存库的图像颜色深度为1位单色。在重新采样时,我们不改变深度。我们的网络将这些单色图像线性地转换为取值范围在-1到1之间的张量。我们使用Sim Sun字体来渲染输入的图像x,因为它涵盖了所有类型的图像。渲染输入图像x,因为它涵盖了大量的 因为它涵盖了大量的字符,而且它被zi2zi所使用。它所渲染的图像是 灰度,并在图像中心显示字符。
训练
我们随机初始化网络的权值。我们使用Adam[15]优化器训练我们的模型,参数β1为0.5,β2为0.999,batch size为16。因为我们的鉴别器D学习速度比生成器快,所以我们在更新鉴别器一次之后更新生成器两次。我们用40个epochs来训练我们的模型。我们将前20个epoch的初始学习率设为0.001,将后20个epoch的衰减率设为0.5。在一台配备了8核2.1GHz CPU和Nvidia GPU RTX 2080 Ti的机器上训练我们的模型需要25小时。我们设置λp=100, λc=15和λs=1。我们使用TensorFlow实现了提出的方法。
评估方式
我们对生成的图像进行定量和定性评估。我们使用均方误差(MSE)和结构相似指数(SSIM)[27]来度量地面真实和生成图像之间的相似性。我们还对我们生成的图像对书法专家和大学生进行了人为评估。
表4显示了提出的方法的数值评价,两个弱化构型,和最新的方法。两种弱化的结构是本文方法与zi2zi的两个主要区别,对比表明,本文提出的风格和组件编码器都改善了生成的图像。图6显示了它们定性差异的几个例子。
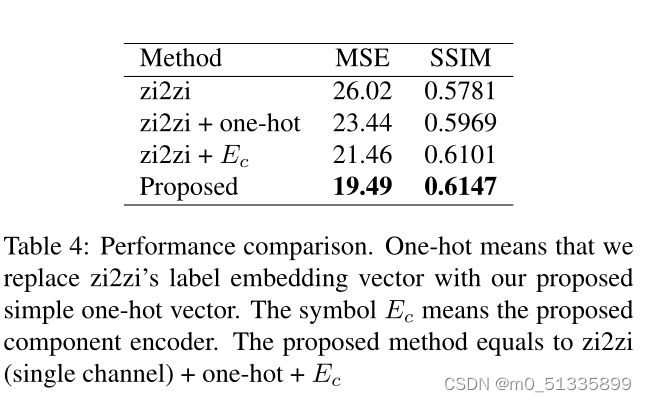

为了进一步验证所提出的组件编码器的有效性,我们进行了另一个单风格转换实验。我们从提出的方法中去除风格特征vs和风格损失,训练7个独立的模型,并在表5中报告它们的总体MSE和SSIM指数。
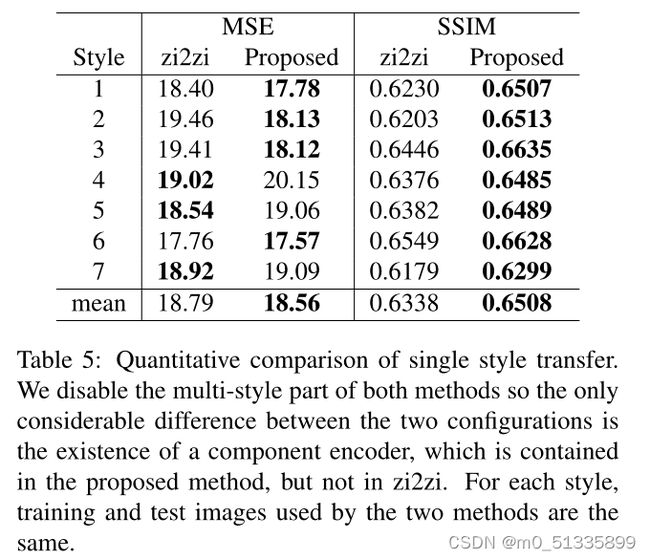
对于一些复杂的字符,我们观察到zi2zi可能生成得不好,如图7所示。这就是其MSE和SSIM指数较差的原因。相比之下,我们所提出的的方法并不存在这样的问题,我们将此改进归因于所提出的组件编码器。

人为评估
我们的实验对象是18名本科生和研究生,包括7名男性和11名女性。他们都是台湾人,每天读繁体字。18名学员中,有3人是中国书法俱乐部的成员,4人不是俱乐部成员,但在艺术课上学过书法,还有11人从未用毛笔写过汉字。其中一名参与者的年龄为40岁,其他所有人的年龄都在20到30岁之间。对于每个参与者,我们从1000个测试字符中随机选择2个字符,使用zi2zi和提出的方法生成图像。因为zi2zi可能生成故障映射,所以我们有意跳过这种情况。我们在所有7种风格下生成图像,因此一个参与者可以看到30幅图像,包括14幅由zi2zi生成的图像,14幅用我们提出的方法生成的图像。两幅是真实图片。我们询问参与者的意见,哪一个图像更接近于真实的图像。表6显示了研究结果。

与AEGG进行比较
AEGG使用与我们相同的图像库,而且据我们所知,它是唯一一个使用书法家书写的图像而不是字体渲染的图像做实验的现有方法,但它的代码和数据集是不可公开的。因为我们无法获得AEGG的数据集,所以我们无法进行直接的比较。然而,AEGG使用的风格在其论文中有明确的说明,所以我们仍然可以进行粗略的比较来观察一般的差异。因为AEGG是一个单一样式的传输算法,我们禁用多样式部分以进行公平比较。他们的结果如图8所示。与AEGG方法相比,该方法生成的图像具有更好的结构(相交更清晰,破碎笔画更少)和更丰富的细节。

5. Conclusion and Future Study 结与展望
文提出了一种新的多风格汉字图像生成方法。它由基于u-net的生成器和组件编码器组成。实验结果表明,该方法能够生成高质量的书法图像。数值计算和人为评估结果表明,该方法生成的图像比现有方法更有效地生成类似于真实地的图像。
我们的研究仍在进行中,多问题尚未得到解答。例如,所提出的方法使用其他类型的字符图像(如字体渲染图像或草书或半草书的图像)的性能如何?有比Sim Sun(新宋体)更好的字体来渲染我们的输入图像吗?选择取决于所用的书法风格吗?我们应该使用多少维来嵌入组件代码?这些嵌入的特征向量有什么模式吗?一些GAN训练方法如WGAN-GP[7]或SN-GAN[19]能提高我们的结果吗?如果我们使用另一个数据分割,我们的方法的性能如何?如果我们用一个强大的预先训练的深度图像分类器代替我们的浅层鉴别器,我们能得到更好的结果吗?我们希望我们能够尽快回答这些问题。