语义分割——FCN模型pytorch实现
FCN网络简介
全卷积网络(Fully Convolutional Networks,FCN)是Jonathan Long等人于2015年在Fully Convolutional Networks for Semantic Segmentation一文中提出的用于图像语义分割的一种框架,是首个端对端的针对像素级预测的全卷积网络。FCN将传统CNN后面的全连接层换成了卷积层,这样网络的输出将是热力图而非类别;同时,为解决卷积和池化导致图像尺寸的变小,使用上采样方式对图像尺寸进行恢复。
网络结构
FCN网络结构主要分为两个部分:全卷积部分和反卷积部分。其中全卷积部分为一些经典的CNN网络(如VGG,ResNet等),用于提取特征;反卷积部分则是通过上采样得到原尺寸的语义分割图像。FCN的输入可以为任意尺寸的彩色图像,输出与输入尺寸相同,通道数为n(目标类别数)+1(背景),(原始FCN是在PASCAL数据集上训练的所以一共有20+1类)。FCN-8s网络结构如下:
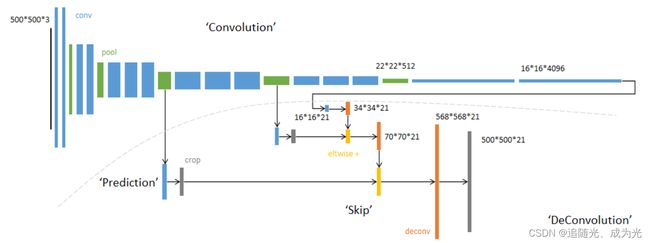
21张概率图中每个像素处是一个概率,表明当前像素属于哪一种类别
这里为什么会产生568*568大小的图片呢,是因为原论文的源码中在第一个卷积层处将padding设置为100,这样做的目的是防止图片下采样32倍后尺寸小于7x7(因为下采样32倍后会经过7x7大小的卷积层),之后上采样32倍后会产生与原图不一样大小的图片,需要进行裁剪才能得到原图大小的输出。
PS:卷积向下取整,池化向上取整
官方模型是采用了VGG16作为backbone
VGG16网络结果如下图所示:
其中最大池化层为2x2 步长为2

论文中提出了三个模型分别是FCN-32s、FCN-16s、FCN-8s。
FCN-32s
pool5的输出直接上采样32倍恢复到原图大小,将损失了原图很多细节信息的特征图直接上采样,效果较差

-
现在的FCN的源码中FC6的卷积层的padding为3,这样可以使输出的图片高宽不变,防止输入图片过小导致该卷积层报错,例如若没有该padding,那么输入192x192的图片FC6的输入会是6x6大小的图片,FC6就报错了。
-
论文源码中的转置卷积的参数是冻结的,因为作者发现冻结和不冻结的结果相差不大,为了提高效率,所以就冻结了。此时转置卷积层相当于是双线性插值。这里效果不明显的原因是上采样倍数太大了
FCN-16s
pool5的输出上采样2倍(采样后大小与pool4的输出相同)然后与pool4输出相加然后再直接上采样16倍恢复到原图大小

FCN-8s
pool5的输出上采样2倍(采样后大小与pool4的输出相同)然后与pool4输出相加然后再上采样2倍(采样后大小与pool3的输出相同),然后与pool3输出相加然后再直接上采样8倍恢复到原图大小。

转置卷积计算公式:
o'为卷积输出大小,i‘为卷积输入大小,s为卷积核stride,k为卷积核大小,p为填充
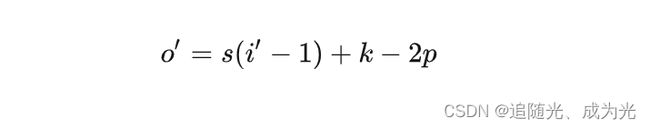
实现FCN-8s时的参数如下
| 参数名称 | 参数值 |
|---|---|
| f6.stride | 1 |
| f6.padding | 3 |
| f7.stride | 1 |
| f7.padding | 1 |
| 转置卷积1.padding | 1 |
| 转置卷积1.stride | 2 |
| 转置卷积2.padding | 1 |
| 转置卷积2.stride | 2 |
| 转置卷积3.padding | 4 |
| 转置卷积3.stride | 8 |
规律:设倍率为x,当转置卷积的2*padding -x = k.size、 s为上采样倍率x时恰好可以上采样
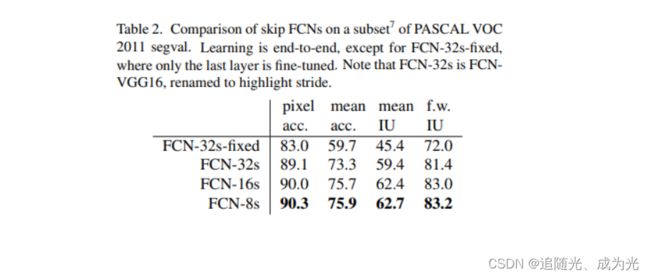
原论文中FCN-32s、16s、8s中效果比较

 Pytorch实现FCN-8s
Pytorch实现FCN-8s
网络结构
数据处理
数据集
数据集采用的是PASCAL VOC2012数据集
root样例 root = 'F:\VOCtrainval_11-May-2012\VOCdevkit\VOC2012' 到VOC2012
class VOC_Segmentation(Dataset):
def __init__(self,root,text_name='train.txt',trans=None):
super(VOC_Segmentation, self).__init__()
#数据划分信息路径
txt_path = os.path.join(root,'ImageSets','Segmentation',text_name)
#图片路径
image_path = os.path.join(root,'JPEGImages')
#mask(label)路径
mask_path = os.path.join(root,'SegmentationClass')
#读入数据集文件名称
with open(txt_path,'r') as f:
file_names = [name.strip() for name in f.readlines() if len(name.strip()) > 0]
#文件名拼接拼接路径
self.images = [os.path.join(image_path,name+'.jpg') for name in file_names]
self.mask = [os.path.join(mask_path,name+'.png') for name in file_names]
self.trans = trans
def __len__(self):
return len(self.images)
def __getitem__(self, index):
'''
albumentations图像增强库是基于cv2库的,
cv2.imread()读入后图片的类型是numpy类型
所以需要保证与cv2读入类型一致
'''
img = np.asarray(Image.open(self.images[index]))
mask = np.asarray(Image.open(self.mask[index]),dtype=np.int32)
if self.trans is not None:
img,mask = self.trans(img,mask)
return img,mask为什么不直接使用cv2呢?
cv2.imread(path, flags)
path: 该参数制定图片的路径,可以使用相对路径,也可以使用绝对路径;
flags:指定以何种方式加载图片,有三个取值:
cv2.IMREAD_COLOR:读取一副彩色图片,图片的透明度会被忽略,默认为该值,实际取值为1;
cv2.IMREAD_GRAYSCALE:以灰度模式读取一张图片,实际取值为0
cv2.IMREAD_UNCHANGED:加载一副彩色图像,透明度不会被忽略起初也想着是直接使用cv2.imread,但是PASCAL VOC2012中mask是调色板模式(单通道,像素取值为[0,255])存储的,cv2.IMREAD_UNCHANGED和cv2.IMREAD_COLOR读入后会创建三通道的数据,使用cv2.IMREAD_GRAYSCALE读入后原有像素值会发生改变(255变成了220).
而PIL的image.open可以直接读入调色板模式的图片,只需要对数据类型进行改变即可。
Transforms
使用的是albumentations图像处理库,这个库中有很多高度封装的transform函数,可以实现傻瓜式同时对image和mask进行转换(pytorch自带的transform无法傻瓜式同时转换)
训练集
数据增强操作
- 随机变化原图,使用双线插值的模式,随机将原图放大到[0.5,2]倍的大小
- 模型训练默认的输入大小为480x480图片,数据集中的有些图片随机变化后无法满足要求,所以要进行填充,这里要注意image填充0也就是背景,mask填充255(后续计算损失时可以忽略掉像素值为255的像素,就不会产生影响了)
- 随机剪切处480x480大小的图片
- 随机进行水平翻转
还要注意image需要调用ToTensor函数,但mask不能直接调用ToTensor函数,因为ToTensor操作会进行归一化,而mask是调色板模式的图片,其中的像素值是处于[0,255]之间的,转化后会出错,只需要手动将他转化为Tensor即可
这里还要注意 mask不需要加通道!!! 最后保证mask是(batch,height,width)格式就行,否则会影响到后续nn.CrossEntropyLoss的计算
class Train_transforms():
def __init__(self,output_size=480,scale_prob=0.5,flip_prob=0.5,mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
self.aug1 = A.Compose([
#随机变换原图
A.RandomScale(scale_limit=[0.5,1.5],interpolation=cv2.INTER_NEAREST,p=scale_prob),
#小于480x480的img和mask进行填充
A.PadIfNeeded(min_height=output_size,min_width=output_size,value=0,mask_value=255),
#剪切
A.RandomCrop(height=output_size,width=output_size,p=1),
#翻转
A.HorizontalFlip(p=flip_prob)
])
self.aug2 = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=mean,std=std)
])
def __call__(self,image,mask):
augmented = self.aug1(image=image,mask=mask)
image,mask = augmented['image'],augmented['mask']
image = self.aug2(image)
mask = torch.as_tensor(np.array(mask),dtype=torch.int64)
return image,mask测试集
转换了图片大小到480x480
class Validate_trans():
def __init__(self,output_size=480,mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
self.aug1 = A.Resize(output_size,output_size,interpolation=cv2.INTER_NEAREST)
self.aug = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=mean,std=std)
])
def __call__(self,image,mask):
augmented = self.aug1(image=image,mask=mask)
image,mask = augmented['image'],augmented['mask']
image = self.aug(image)
mask = torch.as_tensor(np.array(mask),dtype=torch.int64)
return image,mask模型搭建
backbone使用的是VGG模型,具体使用的是VGG16也就是下图中的D

#vgg块
def vgg_block(in_channels,out_channels,num):
block = []
for _ in range(num):
block.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, stride=1))
block.append(nn.ReLU())
in_channels = out_channels
block.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*block)
class VGG(nn.Module):
def __init__(self,num_classes,struct,in_channel=3):
super(VGG, self).__init__()
blk = []
out_channels = []
conv_nums = []
for num,out_channel in struct:
out_channels.append(out_channel)
conv_nums.append(num)
#这里这样写便于后续取出某层的输出
self.layer1 = vgg_block(in_channel,out_channels[0],conv_nums[0])
self.layer2 = vgg_block(out_channels[0], out_channels[1], conv_nums[1])
self.layer3 = vgg_block(out_channels[1], out_channels[2], conv_nums[2])
self.layer4 = vgg_block(out_channels[2], out_channels[3], conv_nums[3])
self.layer5 = vgg_block(out_channels[3], out_channels[4], conv_nums[4])
blk=[nn.Flatten(),
nn.Linear(7*7*512,4096),
nn.Dropout(0.5),
nn.ReLU(),
nn.Linear(4096,4096),
nn.Dropout(0.5),
nn.ReLU(),
nn.Linear(4096,num_classes)]
self.top = nn.Sequential(*blk)
self.__init_net()
def forward(self,x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.top(x)
return x
def __init_net(self):
for layer in self.modules():
if type(layer) == nn.Conv2d:
nn.init.kaiming_normal_(layer.weight,mode='fan_out',nonlinearity='relu')
elif type(layer) == nn.Linear:
nn.init.xavier_normal_(layer.weight)
elif type(layer) == nn.BatchNorm2d:
nn.init.constant_(layer.weight,1) #均值为0
nn.init.constant_(layer.bias,0) #方差为1FCN-Head
FCN-Head也就是网络结构中的FC6和FC7
class FCN_Head(nn.Module):
def __init__(self,in_channel,out_channel):
super(FCN_Head, self).__init__()
self.fc6 = nn.Sequential(
nn.Conv2d(in_channel,out_channel,kernel_size=7,stride=1,padding=3),
nn.BatchNorm2d(out_channel),
nn.ReLU(),
nn.Dropout(0.1)
)
self.fc7 = nn.Sequential(
nn.Conv2d(out_channel,out_channel,kernel_size=1),
nn.BatchNorm2d(out_channel),
nn.ReLU(),
nn.Dropout(0.1)
)
def forward(self,x):
x = self.fc6(x)
x = self.fc7(x)
return x
FCN-8s
class FCN(nn.Module):
def __init__(self,backbone,head,num_classes,channel_nums):
super(FCN, self).__init__()
self.backbone = backbone
self.head = head
#调整通道数
self.layer3_conv = nn.Conv2d(channel_nums[0],num_classes,kernel_size=1) #256
self.layer4_conv = nn.Conv2d(channel_nums[1],num_classes,kernel_size=1) #512
self.layer5_conv = nn.Conv2d(channel_nums[2],num_classes,kernel_size=1) #4096
#转置卷积层1
self.transpose_conv1 =nn.Sequential(
nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(num_classes),
nn.ReLU()
)
# 转置卷积层2
self.transpose_conv2 = nn.Sequential(
nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(num_classes),
nn.ReLU()
)
# 转置卷积层3
self.transpose_conv3 = nn.Sequential(
nn.ConvTranspose2d(num_classes,num_classes,kernel_size=16,stride=8,padding=4),
nn.BatchNorm2d(num_classes),
nn.ReLU()
)
def forward(self,x):
#out = OrderedDict {layer4:{},layer5:{},layer3:{}}
out = self.backbone(x)
layer5_out, layer4_out,layer3_out = out['layer5'],out['layer4'],out['layer3']
layer5_out = self.head(layer5_out)
layer5_out = self.layer5_conv(layer5_out)
layer4_out = self.layer4_conv(layer4_out)
layer3_out = self.layer3_conv(layer3_out)
x = self.transpose_conv1(layer5_out)
x = self.transpose_conv2(x + layer4_out)
x = self.transpose_conv3(x + layer3_out)
return xdef fcn_vgg16(num_classes=20,pretrain_backbone=False):
num_classes += 1
struct = [(2, 64), (2, 128), (3, 256), (3, 512), (3, 512)]
backbone = VGG(num_classes=num_classes,struct=struct)
if pretrain_backbone is True:
#https://download.pytorch.org/models/vgg16-397923af.pth
load_weights(backbone,'../weights/vgg16.pth')
return_layers = {'layer3':"layer3",'layer4':'layer4','layer5':"layer5"}
backbone = torchvision.models._utils.IntermediateLayerGetter(backbone,return_layers)
# x = torch.randn((1,3,224,224))
# x = backbone(x)
head = FCN_Head(in_channel=512,out_channel=4096)
model = FCN(backbone=backbone,head=head,num_classes=num_classes,channel_nums=[256,512,4096])
return modelfcn_vgg16模型
def fcn_vgg16(num_classes=20,pretrain_backbone=False):
num_classes += 1
#vgg16结构
struct = [(2, 64), (2, 128), (3, 256), (3, 512), (3, 512)]
backbone = VGG(num_classes=num_classes,struct=struct)
if pretrain_backbone is True:
#https://download.pytorch.org/models/vgg16-397923af.pth
load_weights(backbone,'../weights/vgg16.pth')
return_layers = {'layer3':"layer3",'layer4':'layer4','layer5':"layer5"}
backbone = torchvision.models._utils.IntermediateLayerGetter(backbone,return_layers)
# x = torch.randn((1,3,224,224))
# x = backbone(x)
head = FCN_Head(in_channel=512,out_channel=4*512)
#layer3 layer4 fcn_head输出通道数
model = FCN(backbone=backbone,head=head,num_classes=num_classes,channel_nums=[256,512,4096])
return model训练
辅助函数
语义分割混淆矩阵:用于计算global acc、acc、IoU
class ConfusionMatrix():
def __init__(self,num_classes):
self.n = num_classes
self.mat = None
def update(self,a,b):
if self.mat is None:
self.mat = torch.zeros(self.n,self.n,device=a.device)
#统计所有有效预测像素的索引
k = (a>=0) & (a < self.n)
#计数
indexs = self.n * a[k].to(torch.int64) + b[k]
self.mat += torch.bincount(indexs,minlength=self.n**2).reshape(self.n,self.n)
def reset(self):
self.mat.zero_()
def compute(self):
h = self.mat.float()
global_acc = torch.diag(h).sum() / h.sum()
acc = torch.diag(h)/h.sum(1)
iou = torch.diag(h) / (h.sum(1)+h.sum(0) - torch.diag(h))
return global_acc,acc,iou训练函数
def train(model,train_iter,validate_iter,loss,optimizer,epochs,num_classes=21):
confusion_matrix = ConfusionMatrix(num_classes=num_classes)
device = get_device()
best_mean_iou = 0
for epoch in range(1,epochs):
train_loss = 0
batch_id = 0
train_num = 0
model.train()
for X,y in train_iter:
batch_id += 1
train_num += len(X)
X,y = X.to(device),y.to(device)
y_hat = model(X)
l = loss(y_hat,y)
train_loss += l.item()
optimizer.zero_grad()
l.backward()
optimizer.step()
if batch_id % 30 == 0:
print(f"epoch{epoch}[{batch_id}/{len(train_iter)}]:loss:{train_loss / train_num}")
model.eval()
vaild_loss = 0
valid_num = 0
for X, y in validate_iter:
with torch.no_grad():
X, y = X.to(device), y.to(device)
y_hat = model(X)
l = loss(y_hat, y)
vaild_loss += l.item()
valid_num += len(X)
confusion_matrix.update(y.flatten(), y_hat.argmax(1).flatten())
global_acc, acc, IoU = confusion_matrix.compute()
print(
f"epoch:{epoch},train_loss:{train_loss / train_num},valid_loss:{vaild_loss / valid_num},global_acc:{global_acc},acc:{acc.mean()},mean_IoU:{IoU.mean()}")
if best_mean_iou < IoU:
weights = model.state_dict()
torch.save(weights, './weights/fcn_vgg16.pth')
confusion_matrix.reset()预测
辅助函数
使用下述代码可以读入mask中的调色板模式,也就是每个像素值对应的RGB值,这样在得到预测后的图片时就可以使用调色板进行调色了。
# 读取mask标签
target = Image.open("2007_000039.png")
# 获取调色板
palette = target.getpalette()
palette = np.reshape(palette, (-1, 3)).tolist()
# 转换成字典子形式
pd = dict((i, color) for i, color in enumerate(palette))
json_str = json.dumps(pd)
with open("palette.json", "w") as f:
f.write(json_str)预测函数
def main():
classes = 20
weights_path = './weights/fcn_vgg16.pth'
img_path = './test.jpg'
pallette_path = "./utils/palette.json"
with open(pallette_path,'rb') as f:
pallette_dict = json.load(f)
pallette = []
for v in pallette_dict.values():
pallette += v
#获取设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} deviece".format(device))
#创建模型
model = fcn_vgg16().to(device)
weights_dict = torch.load(weights_path,map_location='cpu')
# #去除辅助分类器
# for k in list(weights_dict.keys()):
# if "aux" in k:
# del weights_dict[k]
#加载权重
model.load_state_dict(weights_dict)
model.to(device)
#加载图片
original_img = Image.open(img_path)
#转换
data_transform = transforms.Compose([transforms.Resize((480,480)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))])
img = data_transform(original_img)
#添加batch维度
img = torch.unsqueeze(img,dim=0)
model.eval()
with torch.no_grad():
output = model(img.to(device))
prediction = output.argmax(1).squeeze(0) #消除batch维度
prediction = prediction.to('cpu').numpy().astype(np.uint8)
mask = Image.fromarray(prediction)
mask.putpalette(pallette)
mask.save("test_result.png")
#原图和分割图混在一起
def blend():
image1 = Image.open("test.jpg")
image2 = Image.open("test_result.png")
image1 = image1.convert('RGBA')
image2 = image2.convert('RGBA')
#blended_img = img1 * (1 – alpha) + img2* alpha 进行
image1 = image1.resize(image2.size)
image = Image.blend(image1,image2,0.4)
image.show()参考链接:
FCN网络结构详解(语义分割)_哔哩哔哩_bilibiliFCN讲解:FCN网络结构详解(语义分割)_哔哩哔哩_bilibili
FCN源码实现:GitHub - WZMIAOMIAO/deep-learning-for-image-processing: deep learning for image processing including classification and object-detection etc.
安利一个宝藏UP主~
b站 霹雳吧啦Wz