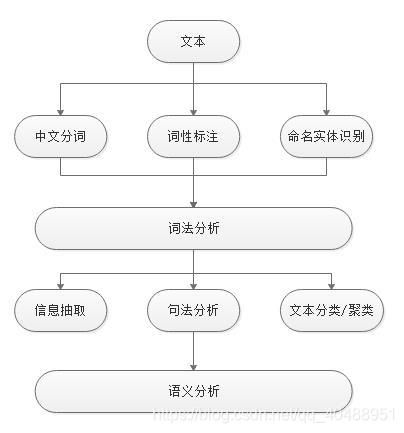
NLP-HanLP基础
1、导入词典
from pyhanlp import *
def load_dictionary():
"""
加载HanLP中的mini词库
:return: 一个set形式的词库
"""
IOUtil = JClass('com.hankcs.hanlp.corpus.io.IOUtil')
path = "CoreNatureDictionary.mini.txt" #字典所在的路径
dic = IOUtil.loadDictionary([path]) #参数为列表形式
return set(dic.keySet()) #返回集合
if __name__ == '__main__':
dic = load_dictionary()
print(len(dic))
print(list(dic)[0])2、使用字典进行分词
from pyhanlp import *
#在字典中加入‘路麟城 nr 1’保证分词正确,删除bin文件重新运行
print(HanLP.segment('''路明非累了。其实在路麟城第二次带他去那充满水银蒸汽的炼金术矩阵见小魔鬼时,
他已经决定要接受切割了。'''))
for term in HanLP.segment('''你好,欢迎在python中调用hanlp的api'''):
print(f'{term.word}\t{term.nature}')
------------------------------------------------------------
[路明非/nr, 累/a, 了/ule, 。/w, 其实/d, 在/p, 路麟城/nr, 第二/mq, 次/qv, 带/v, 他/rr, 去/vf, 那/rzv, 充满/v, 水银/n, 蒸汽/n, 的/ude1, 炼金术/n, 矩阵/n, 见/v, 小魔鬼/nz, 时/qt, ,/w,
/w, 他/rr, 已经/d, 决定/v, 要/v, 接受/v, 切割/v, 了/ule, 。/w]
路明非 nr
累 a
了 ule
。 wfrom pyhanlp import *
HanLP.Config.ShowTermNature = False #不显示词性
#导入分词器
segment = JClass('com.hankcs.hanlp.seg.Other.AhoCorasickDoubleArrayTrieSegment')()
segment.enablePartOfSpeechTagging(True) #识别英文和数字
print(segment.seg("江西鄱阳湖干枯,中国six最大淡水湖变成大草原,tree"))3、加载语料库
'my_cws_corpus.txt'
商品 和 服务
商品 和服 物美价廉
服务 和 货币
--------------------------------------
from pyhanlp import *
CorpusLoader = SafeJClass('com.hankcs.hanlp.corpus.document.CorpusLoader')
sents = CorpusLoader.convert2SentenceList('my_cws_corpus.txt')
for sent in sents:
print(sent)
-------------------
[商品, 和, 服务]
[商品, 和服, 物美价廉]
[服务, 和, 货币]4、语法统计
from pyhanlp import *
NatureDictionaryMaker = SafeJClass('com.hankcs.hanlp.corpus.dictionary.NatureDictionaryMaker')
CorpusLoader = SafeJClass('com.hankcs.hanlp.corpus.document.CorpusLoader')
def train_bigram(corpus_path,model_path):
sents = CorpusLoader.convert2SentenceList(corpus_path)
for sent in sents:
#为兼容hanlp字典格式,为每个单词添加占位符
for word in sent:
word.setLabel('n')
#创建maker对象
maker = NatureDictionaryMaker()
#进行一元、二元统计
maker.compute(sents)
#保存文件,会得到三个文件
maker.saveTxtTo(model_path)
if __name__ == '__main__':
train_bigram('my_cws_corpus.txt','my_cws_model')5、获取词频
from pyhanlp import *
#必须用双引号
def load_bigram(model_path):
#更改字典路径
HanLP.Config.CoreDictionaryPath = model_path + ".txt"
HanLP.Config.BiGramDictionaryPath = model_path + ".ngram.txt"
CoreDictionary = SafeJClass('com.hankcs.hanlp.dictionary.CoreDictionary')
CoreBiGramTableDictionary = SafeJClass('com.hankcs.hanlp.dictionary.CoreBiGramTableDictionary')
print(CoreDictionary.getTermFrequency("商品"))
print(CoreBiGramTableDictionary.getBiFrequency("商品","和"))
if __name__ == '__main__':
load_bigram('my_cws_model')6、构建词网
from jpype import JString
from pyhanlp import *
WordNet = JClass('com.hankcs.hanlp.seg.common.WordNet')
Vertex = JClass('com.hankcs.hanlp.seg.common.Vertex')
#更改配置中字典路径
HanLP.Config.CoreDictionaryPath = "my_cws_model.txt"
CoreDictionary = LazyLoadingJClass('com.hankcs.hanlp.dictionary.CoreDictionary')
def generate_wordnet(sent, trie):
searcher = trie.getSearcher(JString(sent), 0)
wordnet = WordNet(sent)
while searcher.next():
wordnet.add(searcher.begin + 1,
Vertex(sent[searcher.begin:searcher.begin + searcher.length], searcher.value, searcher.index))
# 原子分词,保证图连通
vertexes = wordnet.getVertexes()
i = 0
while i < len(vertexes):
if len(vertexes[i]) == 0: # 空白行
j = i + 1
for j in range(i + 1, len(vertexes) - 1): # 寻找第一个非空行 j
if len(vertexes[j]):
break
wordnet.add(i, Vertex.newPunctuationInstance(sent[i - 1: j - 1])) # 填充[i, j)之间的空白行
i = j
else:
i += len(vertexes[i][-1].realWord)
return wordnet
if __name__ == '__main__':
sent = "商品和服务"
wordnet = generate_wordnet(sent, CoreDictionary.trie)
print(wordnet)7、中文分词
from jpype import JString
from pyhanlp import *
WordNet = JClass('com.hankcs.hanlp.seg.common.WordNet')
Vertex = JClass('com.hankcs.hanlp.seg.common.Vertex')
CoreDictionary = LazyLoadingJClass('com.hankcs.hanlp.dictionary.CoreDictionary')
CoreBiGramTableDictionary = SafeJClass('com.hankcs.hanlp.dictionary.CoreBiGramTableDictionary')
ViterbiSegment = JClass('com.hankcs.hanlp.seg.Viterbi.ViterbiSegment')
DijkstraSegment = JClass('com.hankcs.hanlp.seg.Dijkstra.DijkstraSegment')
HanLP.Config.CoreDictionaryPath = "my_cws_model.txt"
HanLP.Config.BiGramDictionaryPath = "my_cws_model.ngram.txt"
def load_bigram(sent, verbose=True, ret_viterbi=True):
if verbose:
wordnet = generate_wordnet(sent, CoreDictionary.trie)
print(viterbi(wordnet))
return ViterbiSegment().enableAllNamedEntityRecognize(False).enableCustomDictionary(
False) if ret_viterbi else DijkstraSegment().enableAllNamedEntityRecognize(False).enableCustomDictionary(False)
def generate_wordnet(sent, trie):
searcher = trie.getSearcher(JString(sent), 0)
wordnet = WordNet(sent)
while searcher.next():
wordnet.add(searcher.begin + 1,
Vertex(sent[searcher.begin:searcher.begin + searcher.length], searcher.value, searcher.index))
# 原子分词,保证图连通
vertexes = wordnet.getVertexes()
i = 0
while i < len(vertexes):
if len(vertexes[i]) == 0: # 空白行
j = i + 1
for j in range(i + 1, len(vertexes) - 1): # 寻找第一个非空行 j
if len(vertexes[j]):
break
wordnet.add(i, Vertex.newPunctuationInstance(sent[i - 1: j - 1])) # 填充[i, j)之间的空白行
i = j
else:
i += len(vertexes[i][-1].realWord)
return wordnet
#计算词网路径的最短距离
def viterbi(wordnet):
nodes = wordnet.getVertexes()
# 前向遍历
for i in range(0, len(nodes) - 1):
for node in nodes[i]:
for to in nodes[i + len(node.realWord)]:
to.updateFrom(node) # 根据距离公式计算节点距离,并维护最短路径上的前驱指针from
# 后向回溯
path = [] # 最短路径
f = nodes[len(nodes) - 1].getFirst() # 从终点回溯
while f:
path.insert(0, f)
f = f.getFrom() # 按前驱指针from回溯
return [v.realWord for v in path]
if __name__ == '__main__':
sent = "金融和服务"
load_bigram(sent, verbose=True, ret_viterbi=True)8、模型评测
from pyhanlp import *
from msr import msr_dict, msr_train, msr_model, msr_test, msr_output, msr_gold
from ngram_segment import load_bigram
CWSEvaluator = SafeJClass('com.hankcs.hanlp.seg.common.CWSEvaluator')
if __name__ == '__main__':
sent = "商品和服务"
segment = load_bigram(sent) # 加载
#segment会在msr_test语料库上进行分词,输出结果保存在msr_output,msr_gold是预设好的与msr_test对应的标准答案,与msr_output对比统计出精确率
result = CWSEvaluator.evaluate(segment, msr_test, msr_output, msr_gold, msr_dict) # 预测打分
print(result)9、词性标注
1、隐马尔可夫模型
from pyhanlp import *
from pku import PKU199801_TRAIN
HMMPOSTagger = JClass('com.hankcs.hanlp.model.hmm.HMMPOSTagger')
AbstractLexicalAnalyzer = JClass('com.hankcs.hanlp.tokenizer.lexical.AbstractLexicalAnalyzer')
PerceptronSegmenter = JClass('com.hankcs.hanlp.model.perceptron.PerceptronSegmenter')
FirstOrderHiddenMarkovModel = JClass('com.hankcs.hanlp.model.hmm.FirstOrderHiddenMarkovModel')
SecondOrderHiddenMarkovModel = JClass('com.hankcs.hanlp.model.hmm.SecondOrderHiddenMarkovModel')
def train_hmm_pos(corpus, model):
tagger = HMMPOSTagger(model) # 创建词性标注器
tagger.train(corpus) # 训练
# print(', '.join(tagger.tag("他", "的", "希望", "是", "希望", "上学"))) # 预测
analyzer = AbstractLexicalAnalyzer(PerceptronSegmenter(), tagger) # 构造词法分析器
print(analyzer.analyze("他的希望是希望上学")) # 分词+词性标注
return tagger
if __name__ == '__main__':
tagger = train_hmm_pos(PKU199801_TRAIN, FirstOrderHiddenMarkovModel())2、感知机模型
from pyhanlp import *
from pku import PKU199801_TRAIN, POS_MODEL
POSTrainer = JClass('com.hankcs.hanlp.model.perceptron.POSTrainer')
PerceptronPOSTagger = JClass('com.hankcs.hanlp.model.perceptron.PerceptronPOSTagger')
AbstractLexicalAnalyzer = JClass('com.hankcs.hanlp.tokenizer.lexical.AbstractLexicalAnalyzer')
PerceptronSegmenter = JClass('com.hankcs.hanlp.model.perceptron.PerceptronSegmenter')
def train_perceptron_pos(corpus):
trainer = POSTrainer()
trainer.train(corpus, POS_MODEL) # 训练
tagger = PerceptronPOSTagger(POS_MODEL) # 加载
print(', '.join(tagger.tag("他", "的", "希望", "是", "希望", "上学"))) # 预测
analyzer = AbstractLexicalAnalyzer(PerceptronSegmenter(), tagger) # 构造词法分析器
print(analyzer.analyze("李狗蛋的希望是希望上学")) # 分词+词性标注
return tagger
if __name__ == '__main__':
train_perceptron_pos(PKU199801_TRAIN)3、条件随机场模型(计算消耗非常大)
from pyhanlp import *
from pku import POS_MODEL, PKU199801_TRAIN
CRFPOSTagger = JClass('com.hankcs.hanlp.model.crf.CRFPOSTagger')
AbstractLexicalAnalyzer = JClass('com.hankcs.hanlp.tokenizer.lexical.AbstractLexicalAnalyzer')
PerceptronSegmenter = JClass('com.hankcs.hanlp.model.perceptron.PerceptronSegmenter')
def train_crf_pos(corpus):
# 选项1.使用HanLP的Java API训练,慢
tagger = CRFPOSTagger(None) # 创建空白标注器
tagger.train(corpus, POS_MODEL) # 训练
print('训练完成')
tagger = CRFPOSTagger(POS_MODEL) # 加载
# 选项2.使用CRF++训练,HanLP加载。(训练命令由选项1给出)
# tagger = CRFPOSTagger(POS_MODEL + ".txt")
print(', '.join(tagger.tag("他", "的", "希望", "是", "希望", "上学"))) # 预测
analyzer = AbstractLexicalAnalyzer(PerceptronSegmenter(), tagger) # 构造词法分析器
print(analyzer.analyze("李狗蛋的希望是希望上学")) # 分词+词性标注
return tagger
if __name__ == '__main__':
tagger = train_crf_pos(PKU199801_TRAIN)10、命名实体识别
1、角色标注模型
from pyhanlp import *
from test_utility import test_data_path
from NLP import pku
EasyDictionary = JClass('com.hankcs.hanlp.corpus.dictionary.EasyDictionary')
NRDictionaryMaker = JClass('com.hankcs.hanlp.corpus.dictionary.NRDictionaryMaker')
Sentence = JClass('com.hankcs.hanlp.corpus.document.sentence.Sentence')
MODEL = test_data_path() + "/nr"
DijkstraSegment = JClass('com.hankcs.hanlp.seg.Dijkstra.DijkstraSegment')
def train(corpus, model):
dictionary = EasyDictionary.create(HanLP.Config.CoreDictionaryPath) # 核心词典
maker = NRDictionaryMaker(dictionary) # 训练模块
maker.train(corpus) # 在语料库上训练
maker.saveTxtTo(model) # 输出HMM到txt
def load(model):
HanLP.Config.PersonDictionaryPath = model + ".txt" # data/test/nr.txt
HanLP.Config.PersonDictionaryTrPath = model + ".tr.txt" # data/test/nr.tr.txt
segment = DijkstraSegment() # 该分词器便于调试
return segment
train(pku.PKU199801, MODEL)
segment = load(MODEL)
HanLP.Config.enableDebug()
print(segment.seg("龚学平等领导"))2、序列标注模型
from pyhanlp import *
from NLP import pku
NERTrainer = JClass('com.hankcs.hanlp.model.perceptron.NERTrainer')
PerceptronNERecognizer = JClass('com.hankcs.hanlp.model.perceptron.PerceptronNERecognizer')
PerceptronSegmenter = JClass('com.hankcs.hanlp.model.perceptron.PerceptronSegmenter')
PerceptronPOSTagger = JClass('com.hankcs.hanlp.model.perceptron.PerceptronPOSTagger')
Sentence = JClass('com.hankcs.hanlp.corpus.document.sentence.Sentence')
AbstractLexicalAnalyzer = JClass('com.hankcs.hanlp.tokenizer.lexical.AbstractLexicalAnalyzer')
Utility = JClass('com.hankcs.hanlp.model.perceptron.utility.Utility')
def train(corpus, model):
trainer = NERTrainer()
return PerceptronNERecognizer(trainer.train(corpus, model).getModel())
def test(recognizer):
word_array = ["华北", "电力", "公司"] # 构造单词序列
pos_array = ["ns", "n", "n"] # 构造词性序列
ner_array = recognizer.recognize(word_array, pos_array) # 序列标注
for word, tag, ner in zip(word_array, pos_array, ner_array):
print("%s\t%s\t%s\t" % (word, tag, ner))
analyzer = AbstractLexicalAnalyzer(PerceptronSegmenter(), PerceptronPOSTagger(), recognizer)
print(analyzer.analyze("华北电力公司董事长谭旭光和秘书胡花蕊来到美国纽约现代艺术博物馆参观"))
scores = Utility.evaluateNER(recognizer, pku.PKU199801_TEST)
Utility.printNERScore(scores)
if __name__ == '__main__':
recognizer = train(pku.PKU199801_TRAIN, pku.NER_MODEL)
test(recognizer)
analyzer = PerceptronLexicalAnalyzer(PerceptronSegmenter(), PerceptronPOSTagger(), recognizer) # ①
sentence = Sentence.create("与/c 特朗普/nr 通/v 电话/n 讨论/v [太空/s 探索/vn 技术/n 公司/n]/nt") # ②
while not analyzer.analyze(sentence.text()).equals(sentence): # ③
analyzer.learn(sentence)11、信息抽取
1)信息熵:用来描述搭配的丰富程度,x为可能出现的搭配,x的可能性越多,H(x)越大
![]()
2)互信息:用来描述一个词语的稳定程度,x,y为词语中的单字,词语稳定程度小,意味着单字分开出现的频率大于同时出现的频率,意味着I(x,y)越小
![]()
信息熵与互信息越大,该片段左右的搭配越多,该片段越稳定,该片段越可能是一个词
from pyhanlp import *
from test_utility import ensure_data
HLM_PATH = ensure_data("红楼梦.txt", "http://file.hankcs.com/corpus/红楼梦.zip")
word_info_list = HanLP.extractWords(IOUtil.newBufferedReader(HLM_PATH), 100, True, 4, 0.0, .5, 100)
print(word_info_list)3)TF-IDF:本文档中出现频率高,其他文档中出现频率底,更能代表本文档的关键词
![]()
提取关键词:
from pyhanlp import *
TfIdfCounter = JClass('com.hankcs.hanlp.mining.word.TfIdfCounter')
if __name__ == '__main__':
counter = TfIdfCounter()
counter.add("《女排夺冠》", "女排北京奥运会夺冠") # 输入多篇文档
counter.add("《羽毛球男单》", "北京奥运会的羽毛球男单决赛")
counter.add("《女排》", "中国队女排夺北京奥运会金牌重返巅峰,观众欢呼女排女排女排!")
counter.compute() # 输入完毕
for id in counter.documents():
print(id + " : " + counter.getKeywordsOf(id, 3).toString()) # 根据每篇文档的TF-IDF提取关键词
# 根据语料库已有的IDF信息为语料库之外的新文档提取关键词
print(counter.getKeywords("奥运会反兴奋剂", 2))提取关键短语:
from pyhanlp import *
text = '''路明非累了。其实在路麟城第二次带他去那充满水银蒸汽的炼金术矩阵见小魔鬼时,他已经决定要接受切割了。
因为他看着被捆在青铜柱上的小魔鬼,那灰白的脸,紧闭的双眼,他觉得是时候做个了断了,至于是否能把一切搞清楚,已经无所谓了。
说不定答案能在“切割”的时候找到呢?自从师兄失踪以来,他就被人当作一个疯子,后来那个高大的老绅士希尔伯特·让·昂热突然被袭击,
居然就这么容易就倒下了。于是他路明非就无缘无故变成了通缉犯,被迫全世界逃亡,明明他是个超级英雄,为秘党屠了好几个龙王,
可有时候命运就是这样捉弄人。他现在连自己是个什么都是不知道,他厌倦了,恐惧了,正所谓越接近真相就越害怕得知真相。'''
phrase_list = HanLP.extractPhrase(text, 5)
print(phrase_list) #结果为二元短语
-------------------------------------------------------
[命运捉弄人, 就越害怕, 希尔伯特昂热, 真相就越, 秘党屠龙王]4)TextRank:进入本节点的链越多,本节点的权重越高,从本节点输出的链越多,本节点输出的权重越低,d为(0,1)之间的常数
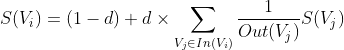
提取关键词:
from pyhanlp import *
content = '''过去的这几天,路麟城满足了他所提的所有要求,确认了老妈还活着,也得到了自己这个爸爸的承诺:
切割完成之后会带着他和老妈过上好生活。路明非当然也不信这鬼话,可是这人至少名义上是他的父亲,他也无法否认他的身份,
他已经没有几个人可以相信了。师姐算一个,但估计现在已经被凯撒接走了吧,也不知道他过得怎么样。师兄也算一个,
但他现在可能还在外面承受暴风雪的寒凉,路明非相信楚子航肯定会来找他的,无论是以前那个师兄还是现在心理年龄只有15岁的他。'''
TextRankKeyword = JClass("com.hankcs.hanlp.summary.TextRankKeyword")
keyword_list = HanLP.extractKeyword(content, 5)
print(keyword_list)
-----------------------------------------------------
[现在, 老妈, 会, 路明非, 相信]提取关键句:
from pyhanlp import *
document = '''路明非累了。其实在路麟城第二次带他去那充满水银蒸汽的炼金术矩阵见小魔鬼时,他已经决定要接受切割了。
因为他看着被捆在青铜柱上的小魔鬼,那灰白的脸,紧闭的双眼,他觉得是时候做个了断了,至于是否能把一切搞清楚,已经无所谓了。
说不定答案能在“切割”的时候找到呢?自从师兄失踪以来,他就被人当作一个疯子,后来那个高大的老绅士希尔伯特·让·昂热突然被袭击,
居然就这么容易就倒下了。于是他路明非就无缘无故变成了通缉犯,被迫全世界逃亡,明明他是个超级英雄,为秘党屠了好几个龙王,
可有时候命运就是这样捉弄人。他现在连自己是个什么都是不知道,他厌倦了,恐惧了,正所谓越接近真相就越害怕得知真相。'''
sentence_list = HanLP.extractSummary(document, 3)
print(sentence_list)
-----------------------------------------------------
[他已经决定要接受切割了, 其实在路麟城第二次带他去那充满水银蒸汽的炼金术矩阵见小魔鬼时, 因为他看着被捆在青铜柱上的小魔鬼]12、文本聚类
聚类:
from pyhanlp import *
from test_utility import ensure_data
ClusterAnalyzer = JClass('com.hankcs.hanlp.mining.cluster.ClusterAnalyzer')
sogou_corpus_path = ensure_data('搜狗文本分类语料库迷你版',
'http://file.hankcs.com/corpus/sogou-text-classification-corpus-mini.zip')
if __name__ == '__main__':
for algorithm in "kmeans", "repeated bisection":
print("%s F1=%.2f\n" % (algorithm, ClusterAnalyzer.evaluate(sogou_corpus_path, algorithm) * 100))分类:
import os
from pyhanlp import SafeJClass
from test_utility import ensure_data
NaiveBayesClassifier = SafeJClass('com.hankcs.hanlp.classification.classifiers.NaiveBayesClassifier')
IOUtil = SafeJClass('com.hankcs.hanlp.corpus.io.IOUtil')
sogou_corpus_path = ensure_data('搜狗文本分类语料库迷你版',
'http://file.hankcs.com/corpus/sogou-text-classification-corpus-mini.zip')
def train_or_load_classifier():
model_path = sogou_corpus_path + '.ser'
if os.path.isfile(model_path):
return NaiveBayesClassifier(IOUtil.readObjectFrom(model_path))
classifier = NaiveBayesClassifier()
classifier.train(sogou_corpus_path)
model = classifier.getModel()
IOUtil.saveObjectTo(model, model_path)
return NaiveBayesClassifier(model)
if __name__ == '__main__':
classifier = train_or_load_classifier()
text = "C罗获2018环球足球奖最佳球员 德尚荣膺最佳教练"
print(classifier.classify(text))13、句法分析
from pyhanlp import *
from test_utility import ensure_data
KBeamArcEagerDependencyParser = JClass('com.hankcs.hanlp.dependency.perceptron.parser.KBeamArcEagerDependencyParser')
CTB_ROOT = ensure_data("ctb8.0-dep", "http://file.hankcs.com/corpus/ctb8.0-dep.zip")
CTB_TRAIN = CTB_ROOT + "/train.conll"
CTB_DEV = CTB_ROOT + "/dev.conll"
CTB_TEST = CTB_ROOT + "/test.conll"
CTB_MODEL = CTB_ROOT + "/ctb.bin"
BROWN_CLUSTER = ensure_data("wiki-cn-cluster.txt", "http://file.hankcs.com/corpus/wiki-cn-cluster.zip")
if __name__ == '__main__':
parser = KBeamArcEagerDependencyParser.train(CTB_TRAIN, CTB_DEV, BROWN_CLUSTER, CTB_MODEL)
print(parser.parse("人吃鱼"))
score = parser.evaluate(CTB_TEST)
print("UAS=%.1f LAS=%.1f\n" % (score[0], score[1]))