【AI简报20210514期】开源项目树莓派复古相机、L4自动驾驶新闻速递

嵌入式AI
1. 地平线L4级自动驾驶芯片流片成功,预计2022年量产上市
原文:
https://www.163.com/dy/article/G9I96HCO05508TBC.html
5月9日消息,AI芯片公司地平线对外披露,公司第三款车规级芯片征程5 Journey 5(简称J5),比预定日程提前一次性流片成功并且顺利点亮。征程5系列芯片是地平线第三代车规级产品,面向L4高等级自动驾驶,将在今年内正式发布。据此前官方披露的消息,基于J5的合作车型量产预计在2022年。据了解,J5单芯片 AI 算力高达 96 TOPS,基于J5集成的智能驾驶计算平台算力将达200 Tops-1000 Tops。

2. 百度Apollo Air横空出世,L4自动驾驶原来可以这样操作?
原文:
https://finance.sina.com.cn/tech/2021-05-14/doc-ikmxzfmm2391502.shtml
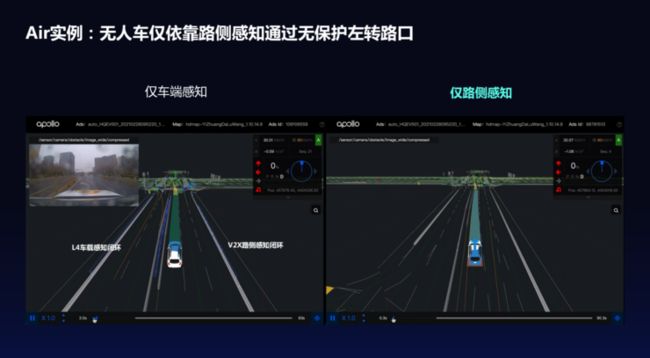
百度此次发布的Apollo Air,是目前全球唯一仅通过路侧感知就能实现开放道路L4自动驾驶闭环的技术,是其在智能出行领域的重大技术突破。Apollo Air技术可以在没有车端传感器、仅借助路端轻量感知和红绿灯信息的情况下,通过利用V2X、5G等无线通信技术实现车-路-云的信息交互,从而赋能自动驾驶。未来,百度Apollo Air还将通过开源、标准化的方式,定期披露相关的研发案例和数据,推动形成对于车路协同方案的业界共识,明确符合自动驾驶需求的基础设施技术条件,将Apollo Air打造成业界共享的车路协同平台,进而带动自动驾驶,乃至整个智慧交通行业的发展。
3. 安全公司Flexxon推出带有嵌入式AI安全功能的X-Phy固态硬盘
原文:
https://www.cnbeta.com/articles/tech/1125543.htm
总部位于新加坡的安全公司Flexxon推出了一款具有嵌入式人工智能安全功能的固态硬盘,该公司表示,该产品有望自主防止传统威胁,如恶意软件和病毒,或对硬盘的物理篡改。这款先进的固态硬盘控制器依靠数个内置的Arm Cortex R内核实现了相当复杂的用于安全判断的计算能力。该平台依赖于一种技术,Flexxon称之为AI One Core Quantum Engine和一种特殊的安全固件。不过,公司对其技术的描述依然是模糊的,因此不清楚其引擎是一个完全自给自足/隔离的平台,还是一个软件、硬件和固件的组合。
4. 深兰科技重磅发布新一代人工智能5G+AI边缘计算产品!
原文:
https://robot.ofweek.com/2021-05/ART-8321205-8460-30498040.html
为了增强AI软硬件产品的竞争力,深兰科技嵌入式平台部设计开发了多款嵌入式系统模块,包括AI边缘计算模块-五岳系列、协处理器系统模块等,可实现模块化快速搭建不同产品的基座。这一系列产品的研发,也秉承了深兰的“沃土模式”的理念,旨在推动工业、汽车、城市、农业、医疗等领域的智能化进程。

4月22日,在深兰工业智能创新研究院(宁波)有限公司成立仪式上,深兰科技重磅发布了新一代人工智能5G+AI边缘计算产品,包括泰山、嵩山和衡山等AI边缘计算系列产品,在算力、算法兼容、性能、功耗与应用场景等多方面为使用者提供了较为全面的边缘计算解决方案。
5. 凌华科技推出业内首款基于NVIDIA Turing架构的MXM图形模块
原文:
https://www.ednchina.com/products/6962.html
凌华科技EGX-MXM-T1000、EGX-MXM-RTX3000和 EGX-MXM-RTX5000是业内首批基于NVIDIA Turing 架构的嵌入式GPU模块
凌华科技嵌入式MXM 图形模块可增强边缘计算和嵌入式AI的运算能力,加速解决嵌入式应用在尺寸、重量与功耗(SWaP)方面所面临的挑战
凌华科技嵌入式图形模块符合Mobile PCI Express Module(MXM)图形接口标准
6.【专利解密】百度AI芯片运算方案实现按需动态分配计算资源
原文:
https://laoyaoba.com/n/780495
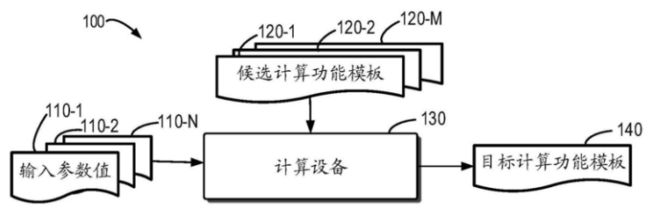 【嘉勤点评】百度发明的人工智能芯片计算方案,根据不同的计算数据为计算模块分配不同的硬件资源,从而在保证运算效率的同时,使得芯片的设计可以动态地适应不同的应用场景,并且实现可动态配置参数的效果。目前,人工智能的比较依赖深度学习的发展,而深度学习技术对计算能力有非常高的要求。由于性能、成本和功耗等各方面的限制,传统的处理器很难满足深度学习的要求。因此,在这种背景下,为了应对量级增长的算力需求,百度发明了昆仑AI芯片。昆仑AI芯片具有高效、低成本和易用三大特征,其针对语音、NLP、图像等专门优化,同等性能下成本降低10倍,支持paddle等多个深度学习框架、编程灵活度高、灵活支持训练和预测。
【嘉勤点评】百度发明的人工智能芯片计算方案,根据不同的计算数据为计算模块分配不同的硬件资源,从而在保证运算效率的同时,使得芯片的设计可以动态地适应不同的应用场景,并且实现可动态配置参数的效果。目前,人工智能的比较依赖深度学习的发展,而深度学习技术对计算能力有非常高的要求。由于性能、成本和功耗等各方面的限制,传统的处理器很难满足深度学习的要求。因此,在这种背景下,为了应对量级增长的算力需求,百度发明了昆仑AI芯片。昆仑AI芯片具有高效、低成本和易用三大特征,其针对语音、NLP、图像等专门优化,同等性能下成本降低10倍,支持paddle等多个深度学习框架、编程灵活度高、灵活支持训练和预测。
AI前沿
7. 阿里发布千亿参数规模AI模型,可设计30多种物品高清图像
原文:
https://www.sohu.com/a/453581760_170520
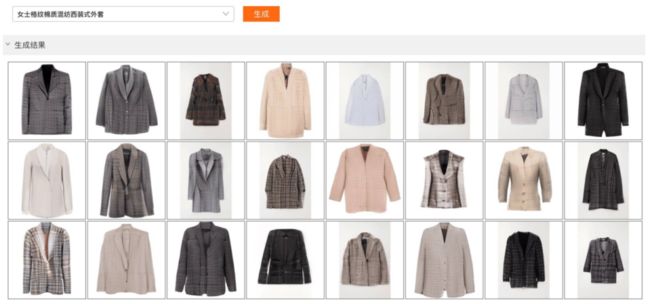
3月2日,阿里巴巴与清华大学联合发布业界最大的中文多模态预训练AI模型M6,该模型参数规模超千亿,同时具备文本、图像的理解和生成能力,图像设计效率超越人类,可应用于产品设计、信息检索、机器人对话、文学创作等领域。
8. Google发布语义分割新数据集!顺带开发个模型屠榜,已被CVPR2021接收
原文:
http://finance.sina.com.cn/tech/csj/2021-04-28/doc-ikmyaawc2304002.shtml
论文: https://arxiv.org/abs/2012.05258
Google提出一个全新的模型ViP-DeepLab,通过深度感知视频全景分割来学习视觉感知,已被CVPR 2021接受,旨在同时解决单眼深度估计和视频全景分割。
论文: ViP-DeepLab: Learning Visual Perception with Depth-aware Video Panoptic Segmentation, 作者提出一个统一模型:ViP-DeepLab,试图解决视觉中长期存在且具有挑战性的逆向投影问题,作者将其建模为从透视图像序列中还原点云,同时为每个点提供实例级的语义解释。作者将这一联合任务命名为深度感知视频全景分割,并为其提出了一个新的评估指标以及两个衍生数据集,并表示这些数据集将被公开。在单个子任务上,ViP-DeepLab 取得了最先进的结果,在 Cityscapes-VPS 上比之前的方法 VPQ 高出5.1%,在 KITTI 单目深度估计基准上排名第一,在 KITTI MOTS 行人上排名第一。
参考:https://zhuanlan.zhihu.com/p/336886066
开源项目
他给女朋友做了个树莓派复古相机,成本不到700元丨开源
原文:
https://mp.weixin.qq.com/s/MNcXa3yilVIrrj2M2wcdJw
https://github.com/penk/ruha.camera

手机拍照不够爽,带个单反又太重?
试试做个树莓派复古相机,还能自己编写处理算法的那种, 成本不到700元。
霸榜多个CV任务,开源仅两天,微软分层ViT模型收获近2k star
原文:
https://finance.sina.com.cn/tech/2021-04-15/doc-ikmxzfmk6957020.shtml
github: https://github.com/microsoft/Swin-Transformer
论文地址:https://arxiv.org/pdf/2103.14030.pdf
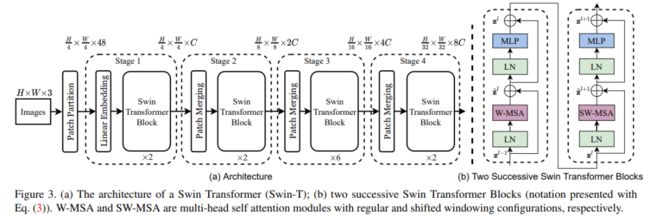
屠榜各大 CV 任务的微软 Swin Transformer,近日开源了代码和预训练模型。自 2017 年 6 月谷歌提出 Transformer 以来,它便逐渐成为了自然语言处理领域的主流模型。最近一段时间,Transformer 更是开启了自己的跨界之旅,开始在计算机视觉领域大展身手,涌现出了多个基于 Transformer 的新模型,如谷歌用于图像分类的 ViT 以及复旦、牛津、腾讯等机构的 SETR 等。由此,「Transformer 是万能的吗?」也一度成为机器学习社区的热门话题。
文末福利
从SGD到NadaMax,十种优化算法原理及实现
原文:
https://mp.weixin.qq.com/s/bRnd7B7oZgJfujbKHsJVfw
本文总结了下面十个优化算法的公式,以及简单的Python实现:
SGD
Momentum
Nesterov Momentum
AdaGrad
RMSProp
AdaDelta
Adam
AdaMax
Nadam
NadaMax
深度学习最常用的10个激活函数!
原文:
https://mp.weixin.qq.com/s/Bbz1GmZbDMtQgCdryv5bWg
Sigmoid 激活函数
Tanh / 双曲正切激活函数
ReLU 激活函数
Leaky ReLU
ELU
PReLU
Softmax
Swish
Maxout
Softplus
![]()
你可以添加微信17775982065为好友,注明:公司+姓名,拉进 RT-Thread 官方微信交流群!
???????????? 点击阅读原文报名培训