程序中的字符串编码处理
GB2312是简体中文系统的标准编码 用“区” 跟“位”的概念表示 称之为区位码
区指代大的范围 位相当于偏移量。
每个汉字占两个字节
高位字节”的范围是0xB0-0xF7,“低位字节”的范围是0xA1-0xFE。
它的规律好像是按拼音a到z的顺序排列的
“啊”字是GB2312之中的第一个汉字,它的区位码就是1601
为此我们现在用代码的方式输出一个汉字
c#下是little字节序 b0跑后面去了。
1 ushort u = 0xa1b0; 2 byte[] chs =BitConverter.GetBytes(u); 3 Console.Write(Encoding.GetEncoding("GB2312").GetString(chs));
屏幕上输出的是汉字“啊”
但是注意并不代表 写个循环从0xbA1 到0xf7fe就可以输出所有的汉字,这个很简单比如高位从1到9 低位从1到9 只有81种组合。
并不代表99-11就是结果 这么二的问题 晕。实际上通过这种方式汉字的个数总共是6768个,理解了区位码的概念后你就知道怎样去处理gb2312的汉字编码了。
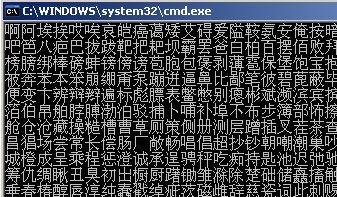
下面我们就用这种方式来输出所有的汉字
1 //gb2312 2 //B0-F7,低字节从A1-FE 3 //byte hi = 0xB0; 4 //byte lo = 0xA1; 5 for (byte i = 0xB0; i <= 0xF7; i++) 6 { 7 for (byte j = 0xA1; j <= 0xFE; j++) 8 { 9 //byte t = (byte)(j | (byte)0x01); 10 Console.Write(Encoding.GetEncoding("GB2312").GetString(new byte[] { i, j })); 11 } 12 }
关于GB2312的解释:http://baike.baidu.com/view/443268.htm?fromId=25492
, ASCII是美国信息交换标准码 他是从0~127,一个字节8位最高是255 就是说一个字节都用不完。
GB2312里也有字母 称之为全角字符 ,gb2312里也包括ascii码称之为半角字符。
全角字符看上去怪怪的 感觉有点不一样 就像这样 全角: A半角:A 全角:a 半角:a
全角字符除了在文字系统里用到没什么实际作用。
全角字符的第一个字节总是被置为163,而第二个字节则是相同半角字符码加上128(不包括空格)。
如半角A为65,则全角A则是163(第一个字节)、193(第二个字节,128+65)。
知道这个规律 那么我们也可以遍历处所有ascii对应的全角字符:
1 /** 2 *实际上,全角字符的第一个字节总是被置为163, 3 *而第二个字节则是相同半角字符码加上128(不包括空格)。 4 *如半角A为65,则全角A则是163(第一个字节)、193(第二个字节,128+65)。 5 */ 6 for (byte k = 0x00; k < 0x7f; k++) 7 { 8 byte[] ch = new byte[2]; 9 ch[0] = 163; 10 ch[1] = (byte)(128 + k); 11 Console.Write(Encoding.GetEncoding("GB2312").GetString(ch)); 12 }

关于全角字符的解释:http://baike.baidu.com/view/41233.htm
winXp下文本文件默认的保存编码是ansi ,注意 这个ansi 他的概念跟GB2312又有不同,除此之外还有unicode 、utf-8
他们之间的关系是:
不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS 等各自的编码标准。
这些使用 2 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。
在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码
C#进行文本读取时新同学最容易出现不理解为什么文本文件读取时是乱码
1 StreamReader sr = new StreamReader(Application.StartupPath + @"\config.txt"); 2 string line; 3 while ((line = sr.ReadLine()) != null) 4 { 5 Console.WriteLine(line); 6 }
因为读取的方式 也就是解码的方式跟文本存储时不一样,所以初始化streamReader时最好指定编码,Default即ANSI
1 StreamReader sr = new StreamReader(Application.StartupPath + @"\config.txt", System.Text.Encoding.Default);
关于ansi Unicode的区别:http://blog.csdn.net/chaijunkun/article/details/4654397
http://www.regexlab.com/zh/encoding.htm