SVM --- 支持向量机
一、SVM概述
在机器学习领域中,SVM(支持向量机)是一种可用于分类和回归任务监督学习算法,在实践中,它的主要应用场景是分类。为了解释这个算法,首先我们可以想象一大堆数据,其中每个数据是高维空间中的一个点,数据的特征有多少,空间的维数就有多少。相应的,数据的位置就是其对应各特征的坐标值。为了用一个超平面尽可能完美地分类这些数据点,我们就要用SVM算法来找到这个超平面。
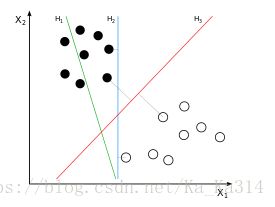
在这个算法中,所谓“支持向量”指的是那些在间隔区边缘的训练样本点,而“机”则是用于分类的那个最佳决策边界(线/面/超平面)。SVM寻找区分两类的超平面,使边际最大。
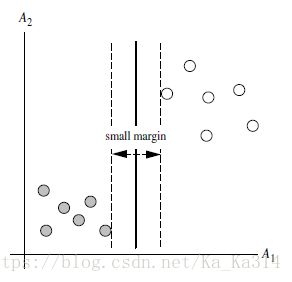

那么如何找到边际最大的超平面?首先要知道点到超平面的距离
二、点到超平面的距离公式
既然这样的直线是存在的,那么我们怎样寻找出这样的直线呢?与二维空间类似,超平面的方程也可以写成一下形式:
![]()
有了超平面的表达式之后,我们就可以计算 样本点到平面的距离了,计算公式如下:

假设有一个样本的中的样本点
![]()
其中表示![]() 为特征变量。那么该点到超平面的距离就可以用如下公式进行计算:
为特征变量。那么该点到超平面的距离就可以用如下公式进行计算:
因为
![]()
所以以上式子可以简化成:
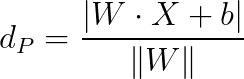
其中||W||为超平面的范数,常数b类似于直线方程中的截距。
三、线性可分
3.1、公式推导
所有的数据点分布在超平面的左右两侧:
所有超平面右侧的点满足:![]()
所有超平面左侧的点满足: ![]()
假设![]() 表示所有数据点的根据超平面的分割标签,的值为1或者-1,以上2个式子可以综合为:
表示所有数据点的根据超平面的分割标签,的值为1或者-1,以上2个式子可以综合为:
![]()
此时我们可以适当调整b的值,使式子满足:
![]()
当满足如下等式的点(即所有坐落在边际的两边的的超平面上的点),我们称为支持向量
![]()
根据以上的推导,可以将点到平面点的距离公式改写成:
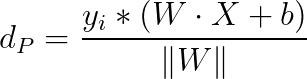
此时求最大间隔距离的超平面为:
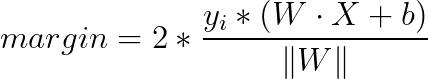
由于所有坐落在边际的两边的超平面上的点的值为1,所以实际的求导的最大间隔距离的超平面公式为:
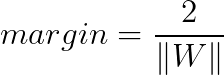
margin以外的样本点对于确定分离超平面没有贡献,换句话说,SVM是有很重要的训练样本(支持向量)所确定的。至此,SVM
分类问题可描述为在全部分类正确的情况下,最大化 (等价于最小化
(等价于最小化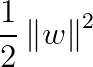 );线性分类的约束最优化问题:
);线性分类的约束最优化问题:
![]()
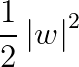
![]()
![]()
对每一个不等式约束引进拉格朗日乘子(Lagrange multiplier)αi≥0,i=1,2,⋯,N;构造拉格朗日函数(Lagrange function):
![L(w,b,\alpha) = \frac{1}{2}\left | w \right |^{2} - \sum_{i=1}^{N}\alpha_{i}[y_{i}(w\cdot x_{i} + b) - 1]](http://img.e-com-net.com/image/info8/4b43ecef221d4ea6835e578bc5d1f6e1.gif)
根据拉格朗日对偶性,原始的约束最优化问题可等价于极大极小的对偶问题:

将![]() 对w,b求偏导并令其等于0,则
对w,b求偏导并令其等于0,则
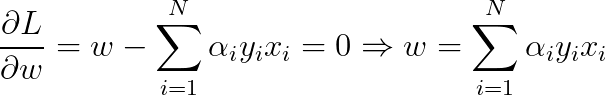

将上述式子代入拉格朗日函数中,对偶问题转为
![]()

等价于最优化问题:
![]()

![]()
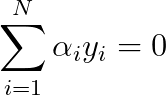
![]()
线性可分是理想情形,大多数情况下,由于噪声或特异点等各种原因,训练样本是线性不可分的。因此,需要更一般化的学习算法。
3.2、简单示例

3.3、Python实现SVM线性可分
示例一:
# 引入svm模块
from sklearn import svm
# 定义3个点
x = [[2, 0], [1, 1], [2, 3]]
# 分类标记
y = [0, 0, 1]
# 建立SVM分类器,线性可分
clf = svm.SVC(kernel = 'linear')
# 建立SVM模型
clf.fit(x, y)
print(clf)
# 支持向量
print(clf.support_vectors_)
# 训练集中的支持向量的下标值
print(clf.support_)
# 分类中各自有多少个支持向量
print(clf.n_support_)
print(clf.predict([[4,5]]))
示例二:(绘制超平面)
import numpy as np
# 导入绘图包
import pylab as pl
from sklearn import svm
# 创建40个训练点
# 每次运行时随机抓取的点不变
np.random.seed(0)
X = np.r_[np.random.randn(20, 2) - [2, 2], np.random.randn(20, 2) + [2, 2]]
Y = [0]*20 + [1]*20
# 建立模型
clf = svm.SVC(kernel='linear')
clf.fit(X, Y)
# switching to the generic n-dimensional parameterization of the hyperplan to the 2D-specific equation
# of a line y=a.x +b: the generic w_0x + w_1y +w_3=0 can be rewritten y = -(w_0/w_1) x + (w_3/w_1)
# 获取w
w = clf.coef_[0]
# 斜率,-(w_0/w_1)
a = -w[0]/w[1]
print("w: ", w)
print("a: ", a)
xx = np.linspace(-5, 5)
# clf.intercept_[0] 获取b(w_3)的值,y = -(w_0/w_1) x + (w_3/w_1)
yy = a*xx - (clf.intercept_[0])/w[1]
# 获取下方的支持向量
b = clf.support_vectors_[0]
yy_down = a*xx + (b[1] - a*b[0])
# 获取上方的支持向量
b = clf.support_vectors_[-1]
yy_up = a*xx + (b[1] - a*b[0])
# 绘制图形
pl.plot(xx, yy, 'k--')
pl.plot(xx, yy_down, 'k--')
pl.plot(xx, yy_up, 'k--')
pl.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1],
s=80, facecolors='none')
pl.scatter(X[:, 0], X[:, 1], c=Y, cmap=pl.cm.Paired)
pl.axis('tight')
pl.show()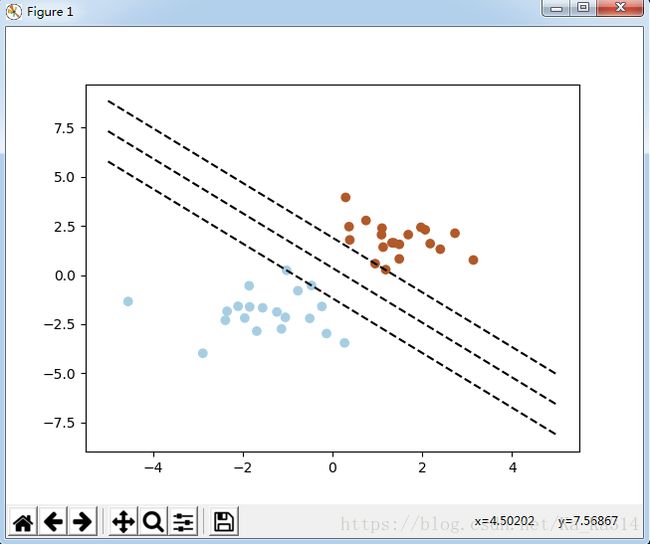
四、线性不可分
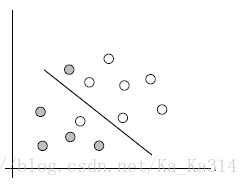
如上图,数据集在空间中对应的向量不可被一个超平面区分开,这种线性不可分的情况该如何处理啦?
一般有两个步骤来解决此类问题:
- 利用一个非线性的映射把原数据集中的向量点转化到一个更高维度的空间中
- 在这个高维度的空间中找一个线性的超平面来根据线性可分的情况处理

那么又如何利用非线性映射把原始数据转化到高维中啦?
例如:
3维输入向量:![]()
转化到6维空间Z中:
![]()
![]()
新的决策超平面:![]() ,其中W和Z是向量,这个超平面是线性的:
,其中W和Z是向量,这个超平面是线性的:
![]()
![]()
在线性SVM中转化为最优化问题时求解的公式计算都是以内积(dot product)的形式出现的![]() ,其中是把
,其中是把
训练集中的向量点转化到高维的非线性映射函数,因为内积的算法复杂度非常大,那么如何解决计算内积时算法复杂度的问题?
我们可以利用核函数来取代计算非线性映射函数的内积:
![]()
根据线性的超平面推导可知,非线性的超平面为:
![]()
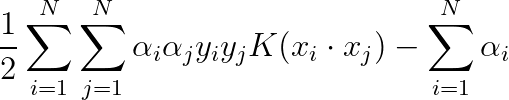
![]()
![]()
常用的核函数:
(1)h度多项式核函数(polynomial kernel of degree h):![]()
(2)高斯径向基核函数(Gaussian radial basis function kernel):![]()
(3)S型核函数(Sigmoid function kernel):![]()
核函数示例:
假设定义两个向量: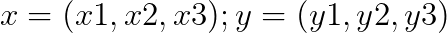
定义方程:
![]()
假设:![]()
那么:
![]()
![]()
![]()
如果使用核计算的方法,那么计算将变得非常简单:
![]()