SIFT图像特征匹配学习笔记
来源
https://www.analyticsvidhya.com/blog/2019/10/detailed-guide-powerful-sift-technique-image-matching-python/
参考
OpenCV-Python之——图像SIFT特征提取
https://www.jianshu.com/p/65a56a2f63e3
总览
- SIFT(尺度不变特征变换)简单介绍
- 如何使用SIFT执行特征匹配
- python实现SIFT
介绍
看一下下面的图像组合,并考虑它们之间的共同元素:
显然我们可以看到每张图片都有埃菲尔铁塔,同时我们也可以注意到每张图像都有不同的背景,这是因为图片从不同角度拍摄的,并且在前景中也有不同的对象。
如何让计算机“看到”每张图像中的埃菲尔铁塔就是我们要解决的问题。
因此,在本文中,我们将讨论一种图像匹配算法SIFT,该算法可从图像中识别出关键特征,并能够将这些特征与同一对象的新图像进行匹配。
目录
1.SIFT简介
2.构造比例尺空间
2.1高斯模糊
2.2高斯的差异
3.关键点局部化
3.1局部最大值/最小值
3.2 关键点选择
4.方向匹配
4.1计算幅值和方向
4.2创建幅值和方向直方图
5.关键点描述符
6.特征提取与特征匹配
1.SIFT简介
SIFT(即尺度不变特征变换)是Computer Vision中的特征检测算法。
SIFT可以帮助我们定位图像中的局部特征(通常称为图像的“关键点”)。这些关键点满足比例不变性和旋转不变性,可用于各种计算机视觉应用,例如图像匹配,对象检测,场景检测等。
在模型训练期间,我们还可以将SIFT生成的关键点用作图像的特征。与边缘特征或HOG特征相比,SIFT特征的主要优点是它不受图像大小或方向的影响。
例如,下面是对图片的两种简单操作,缩小和旋转,两幅图像中的特征仍然可以匹配。

让我们了解如何识别这些关键点,以及确保比例和旋转不变性的技术是什么。广义上讲,整个过程可以分为以下四个部分:
- 构造比例空间:确保要素与比例无关
- 关键点本地化:确定合适的特征或关键点
- 方向分配:确保关键点是旋转不变的
- 关键点描述符:为每个关键点分配唯一的指纹
2.构造比例尺空间
我们需要识别给定图像中最鲜明的特征,同时忽略任何噪声。此外,我们需要确保特征不依赖于比例。这些是关键概念。
2.1高斯模糊
高斯模糊技术可以减少图像中的噪点
对于图像中的每个像素,高斯模糊会基于其相邻像素计算一个值。以下是应用高斯模糊前后的图像示例。如您所见,纹理和次要细节将从图像中删除,并且仅保留诸如形状和边缘之类的相关信息:

高斯模糊成功地去除了图像中的噪点,我们重点介绍了图像的重要特征。现在,我们需要确保这些特征一定不能与比例相关。这意味着我们将通过创建“比例空间”来在多个比例上搜索这些特征。
比例空间是由单个图像生成的具有不同比例的图像的集合。
因此,这些模糊图像是针对多个比例创建的。要创建一组不同比例的新图像,我们将获取原始图像并将比例缩小一半。对于每个新图像,我们将创建模糊版本,如上所述。
例如,我们有尺寸为(275,183)的原始图像和尺寸为(138,92)的缩放图像。对于这两个图像,将创建两个模糊图像:

您可能在想–我们需要缩放图像多少次,并且需要为每个缩放图像创建多少后续的模糊图像?理想的图片缩放次数应该是四次,并且每次模糊图像的数量应该是五个。
2.2高斯的差异
到目前为止,我们已经创建了多个比例的图像(通常由σ表示),并对每个图像都使用了高斯模糊,以减少图像中的噪声。接下来,我们将尝试使用一种被称为高斯差分(DOG)的技术来增强特征。
高斯差分(DOG)是一种特征增强算法,就是将两幅图像在不同参数下的高斯滤波结果相减,得到高斯差分图。
高斯差分(DOG)实现示意图

我们为不同比例的每一组图像进行高斯差分操作,可以得到四幅新图像。
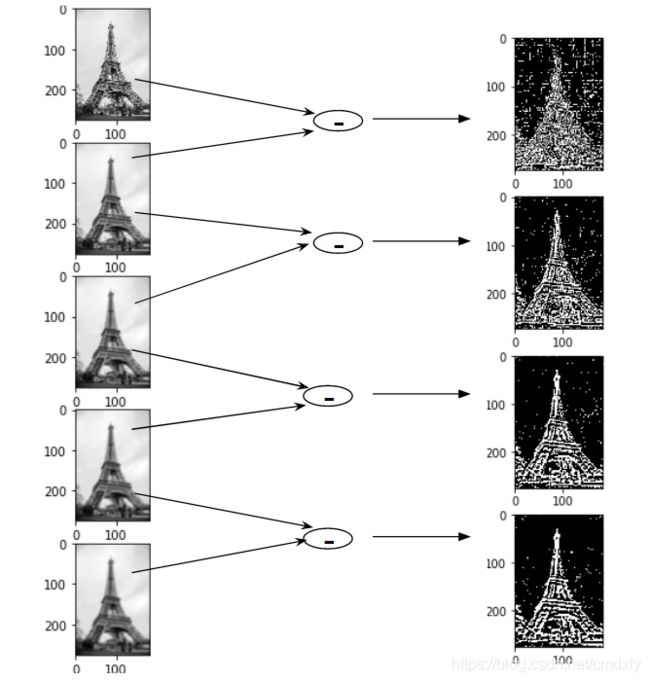
这样我们就为每一幅图像都增强了特征,现在我们有了四组新图像,我们将使用它来找到重要的关键点。
3.关键点局部化
创建图像后,下一步就是从图像中找到可用于特征匹配的重要关键点。也就是找到图像的局部最大值和最小值。这部分分为两个步骤:
- 查找局部最大值和最小值
- 删除低对比度的关键点(关键点选择)
3.1局部最大值/最小值
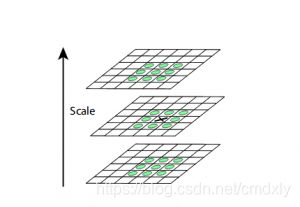
为了定位局部最大值和最小值,我们需要遍历图像中的每个像素,并将其与相邻像素进行比较。
当我说“邻近”时,它不仅包括该像素的周围像素,还包括该尺寸的图片中上一个和下一个图像的九个像素。
这意味着将每个像素值与其他26(9+8+9)个像素值进行比较,以确定是否为局部最大值/最小值。例如,在下图中,我们从某尺寸的图像中获得了三幅图像。将标记为x的像素与相邻像素(绿色)进行比较,如果它是相邻像素中最高或最低的像素,则将其选择为关键点:
3.2 关键点选择
到目前为止,我们已经成功地生成了尺度不变的关键点。但是,这些关键点中的一些可能对噪声没有鲁棒性。这就是为什么我们需要执行最终检查以确保我们拥有最准确的关键点来表示图像特征的原因。
因此,我们将消除对比度低或非常靠近边缘的关键点。
为了处理低对比度关键点,将为每个关键点计算二阶泰勒展开。如果结果值小于0.03(幅度),则我们剔除该关键点。
那么,我们如何处理其余关键点呢?好吧,我们执行检查以确定位置不佳的关键点。那些是靠近边缘并具有高边缘响应但对少量噪声不稳健的关键点,使用二阶Hessian矩阵来识别此类关键点,并进行剔除。
现在我们已经执行了对比测试和边缘测试以拒绝不稳定的关键点,现在我们将为每个关键点分配一个方向值以使旋转不变。
4.方向匹配
在此阶段,我们已经为图像设置了一组稳定的关键点。现在,我们将为每个关键点分配一个方向,以使它们在图像翻转中不会改变。我们可以再次将此步骤分为两个较小的步骤:
1.计算幅值和方向
2.创建大小和方向的直方图
4.1计算幅值和方向
考虑下面显示的示例图像:
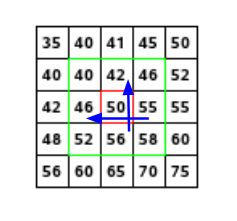
假设我们要找到红色像素值的梯度和方向。为此,我们将通过取55和46与56和42之间的差值来计算x和y方向上的梯度。得出的分别是Gx :55-46= 9和Gy :56-42= 14。
一旦有了梯度,就可以使用以下公式找到幅度和方向:
dg = ((Gx)**2 +(Gy)**2)**0.5 = 16.64
φ = arctan(Gx/Gy)=57.17
假设我们具有这些像素的梯度和方向值,那我们现在就可以创建直方图。
4.2创建幅值和方向直方图
在x轴上,我们将有一个角度值的容器,例如0-9、10 – 19、20-29,最大为360。由于我们的角度值为57,它将落在第6个容器中。第6个bin值将与像素大小成比例,即16.64。我们将对关键点周围的所有像素执行此操作。
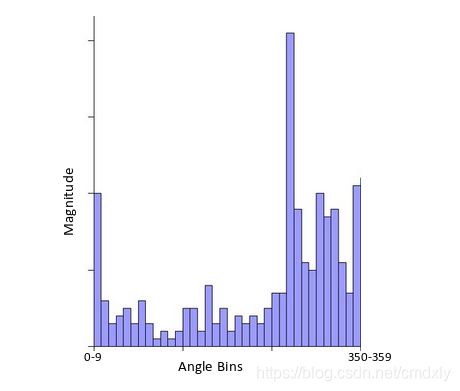
该直方图将在某个点达到峰值。我们看到峰值的位置将是关键点的方向。此外,如果存在另一个显着的峰值(在80 – 100%之间),则会生成另一个关键点,其大小和比例与用于生成直方图的关键点相同。角度或方向将等于具有峰值的新bin。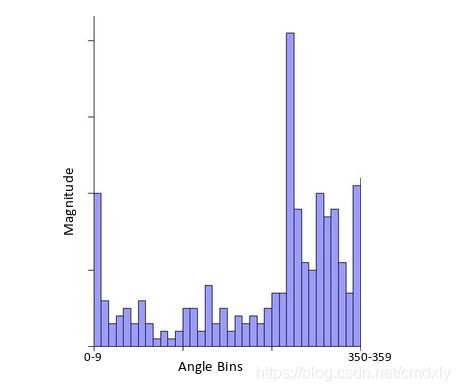
在这一点上,实际上可以说,关键点的数量可能会有所增加。
5.关键点描述符
这是SIFT的最后一步。到目前为止,我们有稳定的关键点,它们满足比例尺不变性和旋转不变性。在本节中,我们将使用相邻像素,它们的方向和大小为该关键点生成唯一的指纹,称为“描述符”。
另外,由于我们使用周围的像素,因此描述符不会受到图像的照度或亮度的影响。
我们首先将在关键点周围采用16×16的邻域。此16×16块进一步分为4×4子块,对于这些子块中的每一个,我们使用幅度和方向生成直方图。

在此阶段,增加了箱的大小,我们只取了8个箱(不是36个)。这些箭头中的每一个代表8个bin,箭头的长度定义了幅度。因此,每个关键点总共有128个bin值。
6.特征提取与特征匹配
6.1 特征提取 -python + opencv
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# author:lucky
# albert time:2020/10/2
import cv2 as cv
import numpy as np
# import matplotlib.pyplot as plt
#读取图像
img = cv.imread('Eiffeltower.jpg')
#图像灰度处理
imgGray = cv.cvtColor(img,cv.COLOR_RGB2GRAY)
#寻找键点
sift = cv.xfeatures2d.SIFT_create()
keypoints,descriptors = sift.detectAndCompute(img,None)
#画出关键点
img = cv.drawKeypoints(imgGray,keypoints,img)
cv.imshow('img',img)
cv.imwrite('Eiffeltower_Keypoint.jpg',img)
cv.waitKey(0)

6.2特征匹配 - c++ + opencv
LOG_DEBUG("Beging siftPointsDetect !!!" );
cv::Mat img1 = cv::imread(imgName1);
cv::Mat img2 = cv::imread(imgName2);
if (img1.empty() || img2.empty())
{
LOG_ERROR("siftPointsDetect error : cannot reading image!!!");
return false;
}
// sift特征提取
std::vector<cv::KeyPoint> vec_keyPoint1, vec_keyPoint2;
cv::Ptr<cv::Feature2D> feature = SIFT::create(pointNum); // 提取pointNum个特征点
feature->detect(img1, vec_keyPoint1);
feature->detect(img2, vec_keyPoint2);
LOG_INFO("detect feature success !!!");
cv::Mat describ1, describ2;
feature->compute(img1, vec_keyPoint1, describ1);
feature->compute(img2, vec_keyPoint2, describ2);
LOG_INFO("generate descriptor !!!");
//绘制特征点(关键点)
cv::Mat feature_pic1, feature_pic2;
cv::drawKeypoints(img1, vec_keyPoint1, feature_pic1, cv::Scalar(0, 255, 0), cv::DrawMatchesFlags::DRAW_RICH_KEYPOINTS);
cv::drawKeypoints(img2, vec_keyPoint1, feature_pic2, cv::Scalar(0, 255, 0), cv::DrawMatchesFlags::DRAW_RICH_KEYPOINTS);
//显示结果
cv::imshow("feature1.jpg", feature_pic1);
cv::imshow("feature2.jpg", feature_pic2);
cv::FlannBasedMatcher matcher; //实例化FLANN匹配器
std::vector<cv::DMatch> matches; //定义匹配结果变量
matcher.match(describ1, describ2, matches); //实现描述符之间的匹配
string strMatchsSize = to_string(matches.size());
LOG_INFO("per image detect feature point number: " + strMatchsSize);
cv::Mat oriMatchRes;
cv::drawMatches(img1, vec_keyPoint1, img2, vec_keyPoint2, matches, oriMatchRes,
cv::Scalar(0, 255, 0), cv::Scalar::all(-1));
cv::imshow("oriMatchResult.jpg", oriMatchRes);

