论文翻译|强化学习的神经组合优化
论文翻译|强化学习的神经组合优化

摘要
本文提出了一个使用神经网络和强化学习来解决组合优化问题的框架。我们专注于旅行商问题 (TSP) 并训练一个循环神经网络,该网络在给定一组城市坐标的情况下,预测不同城市排列的分布。使用负旅行长度作为奖励信号,我们使用策略梯度方法优化循环神经网络的参数。我们将在一组训练图上学习网络参数与在单个测试图上学习它们进行比较。尽管计算成本很高,但无需太多工程和启发式设计,神经组合优化在具有多达 100 个节点的 2D 欧几里得图上实现了接近最佳的结果。应用于 KnapSack,另一个 NP-hard 问题,同样的方法为最多 200 个项目的实例获得最佳解决方案
1 引言
组合优化是计算机科学中的一个基本问题。一个典型的例子是旅行商问题 (TSP),其中给定一个图,需要搜索排列空间以找到具有最小总边权重(旅行长度)的最佳节点序列。 TSP 及其变体在规划、制造、遗传学等方面有无数应用(有关概述,请参见(Applegate 等,2011))。
寻找最佳 TSP 解决方案是 NP-hard 问题,即使在二维欧几里得情况下(Papadimitriou,1977),其中节点是 2D 点,边权重是点对之间的欧几里得距离。在实践中,TSP 求解器依靠手工启发式方法来指导他们的搜索程序有效地找到有竞争力的旅游。尽管这些启发式方法在 TSP 上运行良好,但一旦问题陈述略有变化,就需要对其进行修改。相比之下,机器学习方法通过根据训练数据自动发现自己的启发式方法,有可能适用于许多优化任务,因此与仅针对一项任务优化的求解器相比,需要的手工工程更少。
虽然大多数成功的机器学习技术都属于监督学习系列,其中学习了从训练输入到输出的映射,但监督学习不适用于大多数组合优化问题,因为人们无法获得最佳标签。但是,可以使用验证器比较一组解决方案的质量,并向学习算法提供一些奖励反馈。因此,我们遵循强化学习 (RL) 范式来解决组合优化问题。我们凭经验证明,即使使用最佳解决方案作为标记数据来优化监督映射,与探索不同旅行并观察其相应奖励的 RL 代理相比,泛化性也相当差。
我们提出了神经组合优化,这是一个使用强化学习和神经网络解决组合优化问题的框架。我们考虑了两种基于策略梯度的方法(Williams,1992)。第一种方法称为 RL 预训练,它使用训练集来优化循环神经网络 (RNN),该网络将解决方案的随机策略参数化,使用预期奖励作为目标。在测试时,策略是固定的,通过贪婪解码或采样进行推理。第二种方法称为主动搜索,不涉及预训练。
它从随机策略开始,并在单个测试实例上迭代优化 RNN 参数,再次使用预期的奖励目标,同时跟踪在搜索过程中采样的最佳解决方案。我们发现结合 RL 预训练和主动搜索在实践中效果最好。在具有多达 100 个节点的 2D 欧几里得图上,神经组合优化显着优于 TSP 的监督学习方法(Vinyals 等人,2015b),并且在允许更多计算时间时获得接近最优的结果。我们通过在 KnapSack 问题上测试相同的方法来说明它的灵活性,对于最多 200 个项目的实例,我们得到了最佳结果。这些结果让我们深入了解如何将神经网络用作解决组合优化问题的通用工具,尤其是那些难以设计启发式算法的问题。
2 先前的工作
旅行商问题是一个经过充分研究的组合优化问题,并且已经为欧几里得图和非欧几里得图提出了许多精确或近似算法。 Christofides (1976) 提出了一种启发式算法,该算法涉及计算最小生成树和最小权重完美匹配。该算法具有多项式运行时间,并返回保证在 1.5 倍因子内的解,以达到 TSP 的度量实例中的最优性。
最著名的 TSP 精确动态规划算法的复杂度为 Θ(2nn 2 ),因此无法扩展到大型实例,例如 40 个点。然而,最先进的 TSP 求解器,由于精心手工设计的启发式方法,描述了如何以有效的方式导航可行解的空间,可以求解具有数千个节点的对称 TSP 实例。 Concorde (Applegate et al., 2006) 被广泛接受为最好的精确 TSP 求解器之一,它使用切割平面算法 (Dantzig et al., 1954; Padberg & Rinaldi, 1990; Applegate et al., 2003),迭代地解决 TSP 的线性规划松弛问题,并结合分支定界方法修剪搜索空间中可证明不包含最佳解决方案的部分。类似地,Lin-Kernighan-Helsgaun 启发式算法(Helsgaun,2000)受 LinKernighan 启发式算法(Lin & Kernighan,1973)的启发,是对称 TSP 的最先进的近似搜索启发式算法,并且已被证明可以解决数百个实例节点优化。
更通用的求解器,例如处理 TSP 超集的 Google 的车辆路径问题求解器 (Google, 2016),通常依赖于本地搜索算法和元启发式算法的组合。本地搜索算法基于手工设计的启发式算法(例如 2-opt (Johnson, 1990))在候选解决方案上应用一组指定的本地移动运算符,以在搜索空间中从解决方案导航到解决方案。然后应用元启发式来提出上坡移动并逃避局部最优。 TSP 及其变体的元启发式的一个流行选择是引导局部搜索(Voudouris & Tsang,1999),它通过惩罚它认为不应该出现在一个好的解决方案中的特定解决方案特征来摆脱局部最小值。
将现有的搜索启发式应用于新遇到的问题 - 甚至类似问题的新实例 - 的困难是众所周知的挑战,它源于无免费午餐定理 (Wolpert & Macready, 1997)。由于所有搜索算法在对所有问题进行平均时具有相同的性能,因此在选择搜索算法以保证性能时必须适当地依赖于问题的先验。这一挑战激发了人们对提高优化系统运行的普遍性水平的兴趣(Burke 等人,2003 年),并且是超启发式背后的潜在动机,定义为“用于选择的搜索方法 [s] 或学习机制 [s]或生成启发式算法来解决计算搜索问题”。超启发式旨在通过部分抽象出给定组合问题选择启发式的知识密集型过程,比问题特定的方法更易于使用,并且已被证明可以在许多任务中以卓越的方式成功地结合人类定义的启发式(参见(Burke et al., 2013) 进行调查)。然而,超启发式操作是在启发式的搜索空间上运行,而不是在解决方案的搜索空间上运行,因此最初仍然依赖于人为的启发式。
神经网络在组合优化中的应用有着悠久的历史,其中大部分研究都集中在旅行商问题上 (Smith, 1999)。最早的提议之一是将 Hopfield 网络 (Hopfield & Tank, 1985) 用于 TSP。作者修改了网络的能量函数,使其等效于 TSP 目标,并使用拉格朗日乘子来惩罚违反问题约束的行为。这种方法的一个限制是它对超参数和参数初始化很敏感,正如 (Wilson & Pawley,
1988)。克服这一限制是该领域后续工作的核心,尤其是 (Aiyer et al., 1990; Gee, 1993)。与 Hopfield 网络的发展并行的是使用可变形模板模型来解决 TSP 的工作。也许最突出的是弹性网络的发明作为解决 TSP 的一种手段(Durbin,1987),以及自组织映射在 TSP 中的应用(Fort,1988;Angeniol 等,1988;Kohonen,1990)。解决可变形模板模型的局限性是该领域以下工作的核心(Burke,1994;Favata & Walker,1991;Vakhutinsky & Golden,1995)。尽管这些神经网络具有许多吸引人的特性,但它们作为研究工作仍然受到限制。在仔细进行基准测试时,与算法方法相比,它们并没有产生令人满意的结果(Sarwar 和 Bhatti,2012 年;La Maire 和 Mladenov,2012 年)。或许由于负面结果,自世纪之交以来,这个研究方向在很大程度上被忽视了。
受到序列到序列学习(Sutskever 等人,2014 年)的最新进展的推动,神经网络再次成为各个领域优化研究的主题(Yutian 等人,2016 年),包括离散领域(Zoph & Le , 2016)。特别是,在指针网络(Vinyals 等人,2015b)的介绍中重新审视了 TSP,其中以有监督的方式训练具有非参数 softmax 的循环网络来预测访问城市的序列。尽管架构有所改进,但他们的模型是使用近似求解器给出的监督信号进行训练的。
3 TSP的神经网络架构
我们在本文中关注 2D 欧几里得 TSP。给定一个输入图,表示为二维空间 s = {xi} ni=1 中的 n 个城市的序列,其中每个 xi ∈ R 2 ,我们关心的是找到点 π 的排列,称为游览,访问每个城市一次,总长度最短。我们定义由排列 π 定义的旅行长度为

其中 k·k2 表示 ℓ2 范数。我们的目标是学习随机策略 p(π | s) 的参数,该参数给定一组输入点 s,为短途旅行分配高概率,为长途旅行分配低概率。我们的神经网络架构使用链式法则将旅行的概率分解为

然后使用单独的 softmax 模块来表示(2)的 RHS 上的每一项。我们受到之前工作(Sutskever 等人,2014 年)的启发,这些工作利用基于链规则的相同分解来解决序列到序列问题,例如机器翻译。可以使用普通的序列到序列模型来解决输出词汇表为 {1, 2, . . . ,n}。
然而,这种方法有两个主要问题:(1)以这种方式训练的网络不能推广到超过 n 个城市的输入。 (2) 需要访问真实输出排列来优化具有条件对数似然的参数。我们在本文中解决了这两个问题。对于超出预先指定的图大小的泛化,我们遵循 (Vinyals et al., 2015b) 的方法,它使用一组非参数 softmax 模块,类似于 (Bahdanau et al., 2015) 中的注意力机制.这种称为指针网络的方法允许模型有效地指向输入序列中的特定位置,而不是从固定大小的词汇表中预测索引值。我们采用指针网络架构,如图 1 所示,作为我们的策略模型来参数化 p(π | s)。
该段原理公式原文引用:

3.1 构建细节
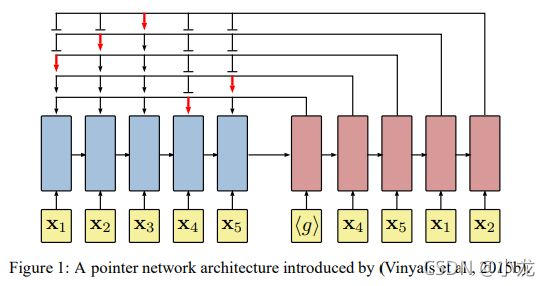
我们的指针网络包含两个循环神经网络 (RNN) 模块,编码器和解码器,它们都由长短期记忆 (LSTM) 单元。编码器网络一次读取一个城市的输入序列 s,并将其转换为潜在记忆状态序列 {enci} n i=1,其中 enci ∈ R d 。在时间步 i 编码器网络的输入是 2D 点 xi 的 d 维嵌入,这是通过所有输入步共享的 xi 的线性变换获得的。解码器网络还维护其潜在记忆状态 {deci} n i=1,其中 deci ∈ R d,并且在每个步骤 i 中,使用指向机制来生成在旅行中要访问的下一个城市的分布。一旦选择了下一个城市,它就会作为输入传递到下一个解码器步骤。第一个解码器步骤的输入(由图 1 中的 hgi 表示)是一个 d 维向量,被视为我们神经网络的可训练参数。
我们在附录 A.1 中正式定义的注意力函数将查询向量 q = deci ∈ R d 和一组参考向量 ref = {enc1, . . . , enck} 其中 enci ∈ R d ,并预测 k 个参考集上的分布 A(ref, q)。此概率分布表示模型在看到查询 q 时指向参考 ri 的程度。维尼亚尔斯等人。 (2015a) 还建议包括一些额外的计算步骤,命名的瞥见,来聚合输入序列不同部分的贡献,非常像 (Bahdanau et al., 2015)。
我们在附录 A.1 中详细讨论了这种方法。在我们的实验中,我们发现利用指向机制中的一瞥以微不足道的成本延迟产生性能提升。
4 使用策略梯度进行优化
维尼亚尔斯等人。 (2015b) 建议使用包含条件对数似然的监督损失函数训练指针网络,该函数将网络输出概率与 TSP 求解器提供的目标之间的交叉熵目标考虑在内。以这种方式从示例中学习对于 NP-hard 问题是不可取的,因为 (1) 模型的性能与监督标签的质量有关,(2) 获得高质量的标记数据是昂贵的,并且对于新的可能不可行问题陈述,(3)一个人更关心找到一个有竞争力的解决方案,而不是复制另一种算法的结果。
相比之下,我们相信强化学习 (RL) 为训练神经网络进行组合优化提供了合适的范例,尤其是因为这些问题具有相对简单的奖励机制,甚至可以在测试时使用。因此,我们建议使用无模型基于策略的强化学习来优化表示为 θ 的指针网络的参数。我们的训练目标是预期的游览长度,给定输入图 s,定义为:
![]()
在训练期间,我们的图是从分布 S 中提取的,总的训练目标涉及从图的分布中采样,即 J(θ) = Es∼S J(θ | s) 。
我们采用策略梯度方法和随机梯度下降来优化参数。 (3) 的梯度是使用众所周知的 REINFORCE 算法(Williams,1992)制定的:
![]()
其中 b(s) 表示不依赖于 π 的基线函数,并估计预期的旅行长度以减少梯度的方差。
通过绘制 B i.i.d.示例图 s1, s2, . . . , sB ∼ S 并对每个图采样一次单次游览,即 πi ∼ pθ(. | si),(4)中的梯度用蒙特卡罗采样近似如下:



基线 b(s) 的一个简单而流行的选择是网络随时间获得的奖励的指数移动平均值,以说明策略随着训练而改进的事实。虽然这种基线选择被证明足以改进 Christofides 算法,但它无法区分不同的输入图。特别是,如果 L(π ∗ |s) > b,对于困难的图 s 的最佳游览 π ∗ 可能仍然不鼓励,因为 b 在批次中的所有实例中共享。
使用参数基线来估计预期的旅行长度 Eπ∼pθ(.|s)L(π | s) 通常可以提高学习效果。因此,我们引入了一个辅助网络,称为评论家并由 θv 参数化,以学习在给定输入序列 s 的情况下我们当前策略 pθ 找到的预期旅行长度。评论家在其预测 bθv (s) 和由最新策略采样的实际旅行长度之间的均方误差目标上使用随机梯度下降进行训练。附加目标被表述为:
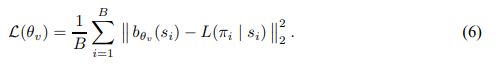
TSP 的 Critic 架构。我们现在解释我们的评论家如何将输入序列 s 映射到基线预测 bθv (s)。我们的评论家包括三个神经网络模块:1) LSTM 编码器,2) LSTM 处理块和 3) 2 层 ReLU 神经网络解码器。它的编码器与我们的指针网络的编码器具有相同的架构,并将输入序列 s 编码为潜在记忆状态序列和隐藏状态 h。与 (Vinyals et al., 2015a) 类似,进程块然后对隐藏状态 h 执行 P 步计算。每个处理步骤通过瞥见附录 A.1 中描述的记忆状态来更新这个隐藏状态,并将瞥见函数的输出作为输入提供给下一个处理步骤。在过程块的末尾,获得的隐藏状态然后被两个完全连接的层解码为基线预测(即单个标量),分别具有 d 和 1 个单元。
我们在算法 1 中描述的训练算法与 (Mnih et al., 2016) 中提出的异步优势 actor-critic (A3C) 密切相关,因为采样的游览长度和评论家的预测之间的差异是对优势函数。我们在多个工作人员之间异步执行我们的更新,但每个工作人员还处理小批量图形以获得更好的梯度估计。
4.1 搜索策略
由于评估旅行长度的成本很低,我们的 TSP 代理可以通过考虑每个图的多个候选解决方案并选择最佳解决方案,在推理时轻松模拟搜索过程。这个推理过程类似于求解器搜索大量可行解的方式。在本文中,我们考虑下面详述的两种搜索策略,我们将其称为采样和主动搜索。
**采样。**我们的第一种方法是简单地从我们的随机策略 pθ(.|s) 中采样多个候选路径并选择最短的一个。与启发式求解器相比,我们不会强制我们的模型在此过程中对不同的旅行进行采样。然而,当从我们的非参数 softmax 采样时,我们可以用温度超参数控制采样路径的多样性(见附录 A.2)。这个采样过程比贪婪解码产生了显着的改进,贪婪解码总是选择概率最大的索引。我们还考虑用随机噪声扰乱指向机制,并从获得的修改策略中贪婪地解码,类似于 (Cho, 2016),但这在我们的实验中证明不如采样有效。
**主动搜索。**与其使用固定模型进行采样并忽略从采样解决方案中获得的奖励信息,还可以在推理过程中细化随机策略 pθ 的参数,以在单个测试中最小化 Eπ∼pθ(.|s)L(π | s)输入 .当从训练有素的模型开始时,这种方法被证明特别具有竞争力。值得注意的是,当从未训练的模型开始时,它也会产生令人满意的解决方案。我们将这两种方法称为 RL 预训练-主动搜索和主动搜索,因为该模型在单个测试实例上搜索候选解决方案时会主动更新其参数。
Active Search 应用类似于算法 1 的策略梯度,但在候选解决方案 π1 上绘制蒙特卡罗样本。 . .对于单个测试输入,πB ∼ pθ(·|s)。它诉诸指数移动平均基线,而不是评论家,因为不需要区分输入。我们的 Active Search 训练算法在算法 2 中给出。我们注意到虽然 RL 训练不需要监督,但它仍然需要训练数据,因此泛化取决于训练数据的分布。相比之下,Active Search 是独立于分发的。最后,由于我们将一组城市编码为一个序列,因此我们在将输入序列提供给我们的指针网络之前随机打乱输入序列。这增加了采样过程的随机性,并导致 Active Search 的大幅改进。

5 实验
我们进行实验来研究所提出的神经组合优化方法的行为。我们考虑了三个基准任务,Euclidean TSP20、50 和 100,为此我们生成了一个包含 1, 000 个图的测试集。点在单位正方形 [0, 1]2 内随机均匀绘制。
5.1 实验细节
在所有实验中,我们使用 128 个序列的小批量、具有 128 个隐藏单元的 LSTM 单元,并将每个点的两个坐标嵌入到 128 维空间中。我们使用 Adam 优化器 (Kingma & Ba, 2014) 训练我们的模型,并对 TSP20 和 TSP50 使用 10-3 的初始学习率,对 TSP100 使用 10-4 的初始学习率,我们每 5000 步衰减 0.96 倍。我们在 [−0.08, 0.08] 内随机均匀地初始化我们的参数,并将梯度的 L2 范数剪裁为 1.0。我们最多使用一次注意力一瞥。搜索时,小批量由测试序列的复制或其排列组成。在 Active Search 中,基线衰减设置为 α = 0.99。我们在 Tensorflow (Abadi et al., 2016) 中的模型和训练代码将很快可用。表 1 总结了实验中使用的配置和不同的搜索策略。我们的方法、实验程序和结果的变化如下。
**监督学习。**除了所描述的基线之外,我们还实施和训练了一个具有监督学习的指针网络,类似于 (Vinyals et al., 2015b)。虽然我们的监督数据包含 100 万次最佳游览,但我们发现我们的监督学习结果不如 (Vinyals et al., 2015b) 报告的那样好。我们怀疑,由于模型无法仅通过查看给定的监督目标来找出细微的特征,因此对于监督指针网络来说,从最佳游览中学习更加困难。因此,我们参考了 (Vinyals et al., 2015b) 中关于 TSP20 和 TSP50 的结果,并报告了我们在 TSP100 上的结果,与其他方法相比,所有这些结果都不是最优的。
**RL 预训练。**对于 RL 实验,我们动态生成训练小批量输入并使用 Actor Critic 算法 1 更新模型参数。我们使用 10, 000 个随机生成实例的验证集进行超参数调整。我们的评论家由一个编码器网络组成,该网络与策略网络具有相同的架构,但后面有 3 个处理步骤和 2 个完全连接的层。我们发现使用 tanh(·) 激活函数将 logits 裁剪为 [−10, 10],如附录 A.2 中所述,有助于探索并产生边际性能增益。使用 RL 预训练模型的最简单搜索策略是贪婪解码,即在每个解码步骤中选择概率最大的城市。我们还尝试在推理时从一组 16 个预训练模型中贪婪地解码。对于每个图形,收集每个单独模型找到的游览并选择最短的游览。我们将这些方法称为 RL pretraining-greedy 和 RL pretraining-greedy@16。
RL 预训练-采样。对于每个测试实例,我们从预训练模型中抽取 1、280、000 个候选解决方案,并跟踪最短路径。对温度超参数的网格搜索发现各自的温度分别为 2.0、2.2 和 1.5,以产生 TSP20、TSP50 和 TSP100 的最佳结果。我们将调整后的温度超参数称为 T ∗ 。由于采样不需要参数更新并且完全可并行化,因此我们使用更大的批量大小来提高速度。
RL 预训练-主动搜索。对于每个测试实例,我们从预训练的 RL 模型初始化模型参数,并运行 Active Search 最多 10, 000 个训练步骤,批量大小为 128,共采样 1, 280, 000 个候选解决方案。我们将学习率设置为训练 TSP 代理的初始学习率的百分之一(即 10-5 TSP20/TSP50 和 TSP100 的 10-6)。
主动搜索。我们允许模型训练更长的时间来解释它从头开始的事实。对于每个测试图,我们在 TSP20/TSP50 上运行 100, 000 个训练步骤和在 TSP100 上运行 200, 000 个训练步骤的 Active Search。

5.2 实验和分析
我们将我们的方法与提高性能和复杂性的 3 个不同基线进行比较:1) Christofides,2) OR-Tools (Google, 2016) 中的车辆路径求解器和 3) 最优性。 Christofides 解是在多项式时间内获得的,并保证在 1.5 的最优比内。 OR-Tools 通过简单的本地搜索运算符改进了 Christofides 的解决方案,包括 2-opt (Johnson, 1990) 和 Lin-Kernighan 启发式 (Lin & Kernighan, 1973) 的一个版本,在达到局部最小值时停止。为了避免糟糕的局部最优,ORTools 的局部搜索还可以与不同的元启发式算法结合运行,例如模拟退火(Kirkpatrick 等,1983)、禁忌搜索(Glover & Laguna,2013)或引导式局部搜索(Voudouris) & 曾, 1999)。 OR-Tools 的车辆路径求解器可以处理 TSP 的超集,并且比高度特定于 TSP 的求解器具有更高的通用性。虽然不是 TSP 的最新技术,但它是一般路由问题的常见选择,并在最基本的局部搜索算子的简单性和最强求解器的复杂性之间提供了合理的基线。通过 Concorde(Applegate 等人,2006 年)和 LK-H 的本地搜索(Helsgaun,2012 年;2000 年)获得最佳解决方案。虽然只有协和飞机可以证明将实例求解为最优,但我们凭经验发现 LK-H 也能在我们所有的测试集上实现最优解。
我们在表 2 中报告了我们的方法在 TSP20、TSP50 和 TSP100 上的平均游览长度。值得注意的是,结果表明,使用 RL 进行训练比监督学习有显着改善(Vinyals 等人,2015b)。我们所有的方法都轻松地超越了 Christofides 的启发式方法,包括 RL 预训练-Greedy,它也不依赖于搜索。表 3 将我们的 greedy 方法的运行时间与上述基线进行了比较,我们的方法在单个 Nvidia Tesla K80 GPU、Concorde 和 LK-H 上运行在 Intel Xeon CPU E5-1650 v3 3.50GHz CPU 和 ORTool 上运行在 Intel哈斯韦尔CPU。我们发现这两种贪婪方法都具有时间效率,并且仅比最优性差几个百分点。
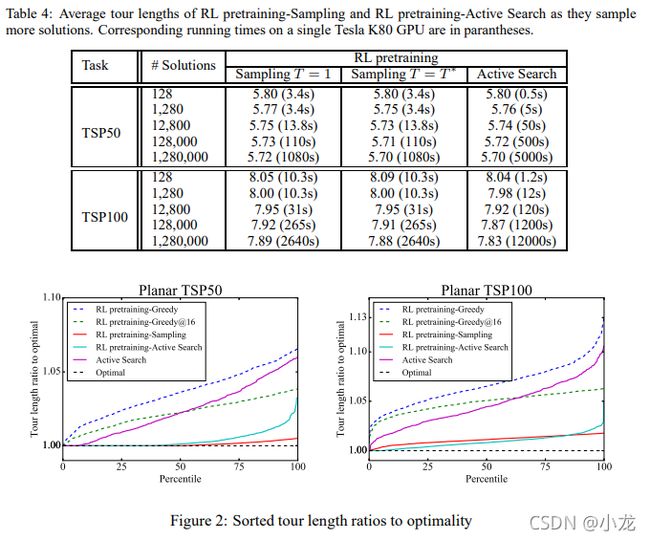
事实证明,在推理时间搜索对于接近最优性至关重要,但代价是运行时间更长。幸运的是,RL pretraining-Sampling 和 RL pretrainingActive Search 的搜索可以提前停止,并在最终目标方面进行小的性能权衡。这可以在表 4 中看到,我们将它们的性能和相应的运行时间显示为它们考虑的解决方案数量的函数。
我们还发现,我们的许多 RL 预训练方法优于 OR-Tools 的本地搜索,包括运行速度类似的 RL 预训练-Greedy@16。附录 A.3 中的表 6 展示了元启发式算法在考虑更多解决方案和相应运行时间时的性能。
与最优性的比率 在我们的实验中,神经组合证明优于模拟退火,但其竞争力略低于禁忌搜索,远不如引导局部搜索。我们在图 2 中对我们的方法进行了更详细的比较,其中我们对不同学习配置的最优性比率进行了排序。 RL pretraining-Sampling 和 RL pretrainingActive Search 是最具竞争力的神经组合优化方法,可以在我们的大量测试用例中恢复最佳解决方案。我们发现,对于小的解空间,RL 预训练-采样,具有微调的 softmax 温度,优于 RL 预训练-主动搜索,后者有时会将搜索定向到解空间的次优区域(参见表 4 和图 2 中的 TSP50 结果) .此外,RL 预训练-采样得益于完全可并行化,并且比 RL 预训练-主动搜索运行得更快。然而,对于更大的解决方案空间,RL 预训练 Active Search 在控制采样解决方案的数量或运行时间时都证明是优越的。有趣的是,从未经训练的模型开始的 Active Search 也能产生有竞争力的游览,但需要相当长的时间(每个 TSP50/TSP100 实例分别为 7 和 25 小时)。最后,我们展示了通过我们的方法找到的随机选择的示例游览,如图3.
6 泛化到其他问题
在本节中,我们将讨论如何将神经组合优化应用于除 TSP 之外的其他问题。在神经组合优化中,模型架构与给定的组合优化问题相关联。有用网络的示例包括指针网络,当输出是排列或截断排列或输入的子集时,以及用于其他类型结构化输出的经典 seq2seq 模型。对于需要为输入元素分配标签的组合问题,例如图着色,还可以组合一个指针模块和一个 softmax 模块,在解码时同时指向和分配。给定一个模型,该模型对给定组合优化任务的实例进行编码并重复分支到子树中以构建解决方案,然后可以通过根据所考虑的优化问题调整奖励函数来应用第 4 节中描述的训练过程。
此外,还需要确保获得的解决方案的可行性。对于某些组合问题,很容易准确地知道哪些分支在解码时不会导致任何可行的解决方案。然后我们可以在解码时简单地手动为它们分配零概率,类似于我们如何在我们的指向机制中强制我们的模型不两次指向同一个城市(参见附录 A.1)。然而,对于许多组合问题,想出一个可行的解决方案本身就是一个挑战。例如,考虑具有时间窗口的旅行商问题,其中旅行商有在特定时间窗口访问每个城市的额外限制。可能是在巡回赛早期考虑的大多数分支都不会导致任何解决方案尊重所有时间窗口。在这种情况下,确切知道哪些分支是可行的需要搜索它们的子树,这是一个耗时的过程,除非使用特定于问题的启发式方法,否则并不比直接搜索最佳解决方案容易多少。
与其明确地将模型约束为仅对可行解进行采样,还可以让模型学会尊重问题的约束。一种将在未来工作中通过实验验证的简单方法包括使用一项惩罚违反问题约束的解决方案的项来增加目标函数,类似于约束优化中的惩罚方法。虽然这并不能保证模型在推理时始终对可行解进行采样,但这不一定有问题,因为我们可以简单地忽略不可行解并从模型中重新采样(对于 RL 预训练采样和 RL 预训练主动搜索)。也可以通过将零概率分配给易于识别为不可行的分支,同时在完全构建后仍然惩罚不可行的解决方案来组合这两种方法。
6.1 背包问题
作为神经组合优化灵活性的一个例子,我们考虑 KnapSack 问题,这是计算机科学中另一个深入研究的问题。给定一组 n 个物品 i = 1…n,每个物品都有重量 wi 和价值 vi 以及最大重量容量 W,0-1 KnapSack 问题在于最大化背包中物品的价值总和,所以重量之和小于或等于背包容量:

由于 wi 、vi 和 W 采用实数值,问题是 NP-hard (Kellerer et al., 2004)。一个简单而强大的启发式方法是采用按重量价值比排序的物品,直到它们填满重量容量。我们应用指针网络并将每个背包实例编码为二维向量序列(wi,vi)。在解码时,指针网络指向要包含在背包中的物品,当到目前为止收集的物品的总重量超过重量容量时停止。
我们生成了三个数据集 KNAP50、KNAP100 和 KNAP200,包含一千个实例,项目的权重和值在 [0, 1] 中随机均匀绘制。不失一般性(因为我们可以缩放物品的重量),我们将 KNAP50 的容量设置为 12.5,KNAP100 和 KNAP200 的容量设置为 25。我们在表 5 中展示了 RL 预训练贪婪和主动搜索(我们运行了 5, 000 个训练步骤)的性能,并将它们与两个简单的基线进行了比较:第一个基线是贪婪的权重值比启发式;第二个基线是随机搜索,我们对 Active Search 所看到的尽可能多的可行解决方案进行采样。 RL pretraining-Greedy 产生的解决方案平均仅比最优方案少 1%,而 Active Search 将所有实例求解为最优方案。

7 总结
本文介绍了神经组合优化,这是一个使用强化学习和神经网络解决组合优化的框架。我们专注于旅行商问题 (TSP),并为框架的每个变体提供了一组结果。实验表明,神经组合优化在具有多达 100 个节点的 2D 欧几里得图上实现了接近最佳的结果。
致谢
作者要感谢 Vincent Furnon、Oriol Vinyals、Barret Zoph、Lukasz Kaiser、Mustafa Ispir 和 Google Brain 团队富有洞察力的评论和讨论。
参考文献
请参考原论文,不做为翻译内容。