MySql之数据库性能优化策略
文章目录
- 0.数据库重启
- 1.连接配置优化
-
- 1.1.服务端
-
- 1.1.1.修改增加服务端的连接数量
- 1.1.2.适当设置连接的超时时间
- 1.2.客户端---->连接池的使用
-
- 1.2.1.连接池的使用
- 1.2.2.目前支持连接池的工具和Orm框架等
- 1.2.3.连接池是否越大越好?
- 2.缓存
- 3.主从复制
- 4.分库分表
-
- 4.1.垂直分表
- 4.2.水平分表
- 5.高可用方案
-
- 5.1.主从复制
- 5.2.NDB Cluster
-
- 5.2.1.概念
- 5.3.Galera
-
- 5.3.1.官网
- 5.3.2.概念
- 5.4. MHA/MMM
-
-
- 5.4.1.MMM
- 5.4.2.MHA
-
- 5.5.MGR
-
- 5.5.1.概念
- 5.6.高可用方案总结
- 6.优化器——SQL 语句分析与优化
-
- 6.1.慢查询日志 slow query log
-
- 6.1.1.官网
- 6.1.2.打开慢日志开关
- 6.1.3.默认时间 10s
- 6.1.4.样例
-
- 6.1.4.1.开启慢日志开关
- 6.1.4.2.设置慢SQL时间为3秒
- 6.1.4.2.执行select SLEEP(10)
- 6.1.5.慢日志分析
-
- 6.1.5.2.查询用时最多的 5 条慢 SQL
- 6.2.SHOW PROFILE
-
- 6.2.1.概念
- 6.2.2.查看是否开启
- 6.2.3.查看 profile 统计
- 6.3.其他系统命令
-
- 6.3.1.show processlist 运行线程
-
- 6.3.1.1.概述
- 6.3.1.2.通过查询表查询线程状态
- 6.3.2.show status 服务器运行状态
-
- 6.3.2.1.概述
- 6.3.3.show engine 存储引擎运行信息
- 6.3.3.show engines 显示所有的存储引擎
- 6.4. Explain
-
- 6.4.1.官网
- 6.4.2.
这一章节,主要是解释的是数据库调优,我们从哪几方面对mysql的性能进行调优?
1.所谓的数据库性能调优,主要是指的我们如何让我们的SQL执行更快,比如查询更快;
那么我们在进行数据库性能调优的时候,需要从SQL的整个执行的流程上去调整和优化;
分析每个环节的消耗时间,去进行优化;
下面是一个执行的整体流程,我们根据这个流程去分析优化的方面
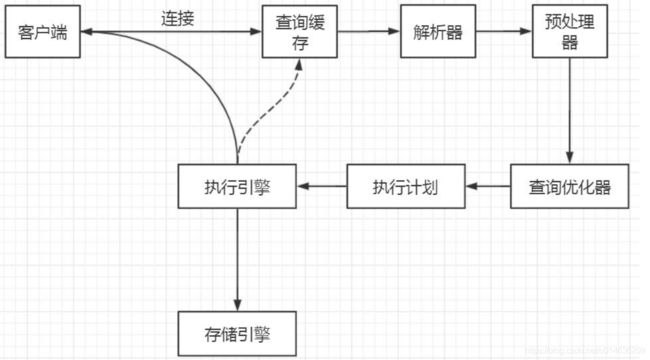
关于SQL的执行的整体流程,大家可以参考下面的地址学些
https://blog.csdn.net/u014636209/article/details/103989376
0.数据库重启
1.一般不建议,除非长时间没有重启过服务,比如几年
1.连接配置优化
1.这里的连接问题,主要是连接可用的线程数量;
2.这个连接的配置,两个方面,考虑:服务端和客户端
1.1.服务端
1.服务端的连接数,通俗的理解实际上就是:我这台mysql服务器最多同时支持多少个连接的请求并发;
1.1.1.修改增加服务端的连接数量
show variables like 'max_connections'; # 默认151个连接
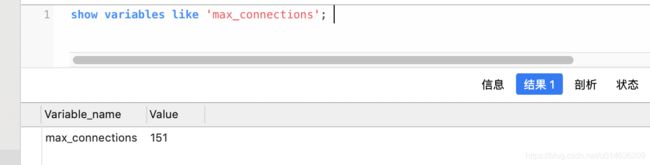
1.并不是连接数量越多越好,这个跟服务器的性能以及服务器CPU核心数量有关系,
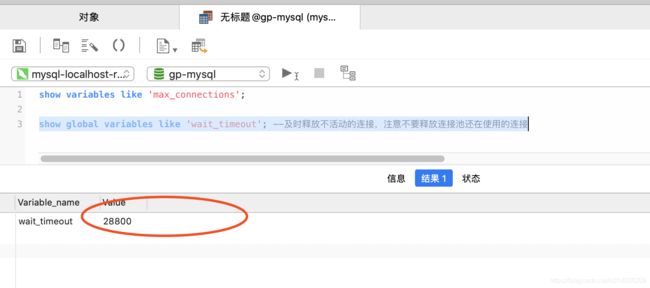
1.1.2.适当设置连接的超时时间
1.及时释放不活动的连接。交互式和非交互式的客户端的默认超时时间都是 28800秒,8小时(8*3600=28800秒),我们可以把这个值调小。
show global variables like 'wait_timeout'; --及时释放不活动的连接,注意不要释放连接池还在使用的连接
1.2.客户端---->连接池的使用
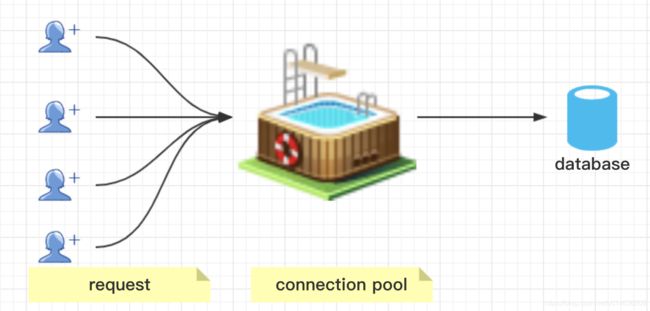
1.2.1.连接池的使用
1.所谓的连接池,就是我们在应用服务器在启动的时候,会初始化多少个连接到数据库(当然这里有好多配置:比如最多连接多少,最少连接数等等)
形成一个池子,一旦外部请求应用,应用可以直接使用连接池中的连接,然后与数据库进行交互,较少连接数据库的时间,实现连接的重用;
1.2.2.目前支持连接池的工具和Orm框架等
1.ORM:MyBatis自带了一个连接池
2.连接池的工具:
Druid(阿里巴巴)
Hikari(Spring Boot 2.x 版本默认的连接池)
DBCP (以前比较经典的)
C3P0 (以前比较经典的)
1.2.3.连接池是否越大越好?
Druid 的默认最大连接池大小是 8。Hikari 的默认最大连接池大小是 10。
为什么有的情况下,减少连接数反而会提升吞吐量呢?为什么建议设置的连接池大小要跟CPU的核数相关呢?
每一个连接,服务端都需要创建一个线程去处理它。连接数越多,服务端创建的线程数就会越多;
问题:CPU 是怎么同时执行远远超过它的核数大小的任务的?
时间片。上下文切换。 而 CPU 的核数是有限的,频繁的上下文切换会造成比较大的性能开销。
2.缓存
1.这里我们说的数据库优化中的缓存,主要是指:可以引入第三方的缓存服务,来缓解数据库的压力,变相的提升数据库的性能;
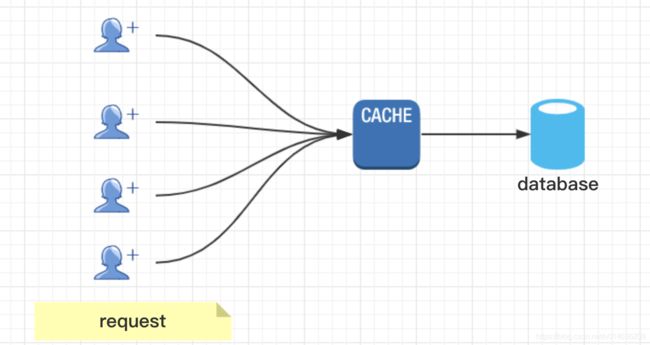
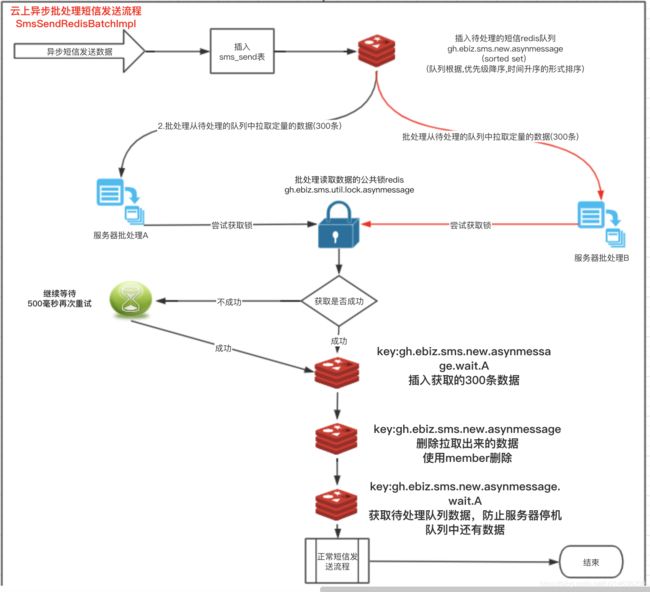
1.下面例子:在我们曾经做过的一个短信应用服务当中,由于短信的数量特别多,每天几万的短信发送量,
我们的短信有一些是异步发送的(也就是有些短信实时性要求不是特别高,比如生日提醒短信等等)
2.业务流程:
2.1.我们先接受业务方发送短信请求MQ,我们保存数据库SMS_SEND表,然后将sms_send表记录的主键保存到redis当中
2.2.后面我们启动定时任务,去扫描redis当中的数据(我们2.1当中保存的主键),然后通过主键再去查询sms_send表的具体短信内容,
这样我们通过redis这一层的缓存操作,可以有效地减少数据库的压力;
3.主从复制
1.我们这里之所以提起主从复制的策略,主要是基于可能单台的mysql的数据库已经无法满足应用的请求,我们通过数据库负载集群的方式
来减少单台服务器的压力,从而有效地提升数据库的性能;
2.关于主从复制的一些原理,可以参考下面的地址学些了解
https://blog.csdn.net/u014636209/article/details/83041341
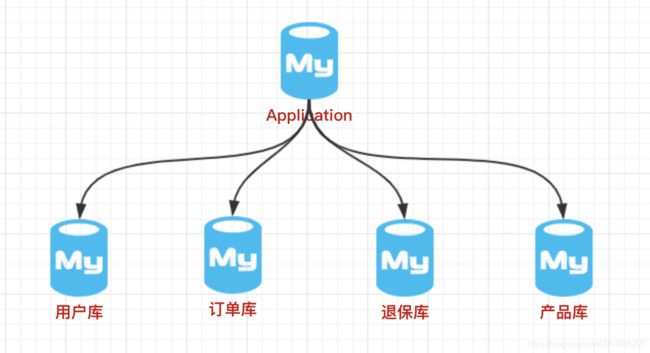
4.分库分表
4.1.垂直分表
垂直分库的做法,把一个数据库按照业务拆分成不同的数据库:
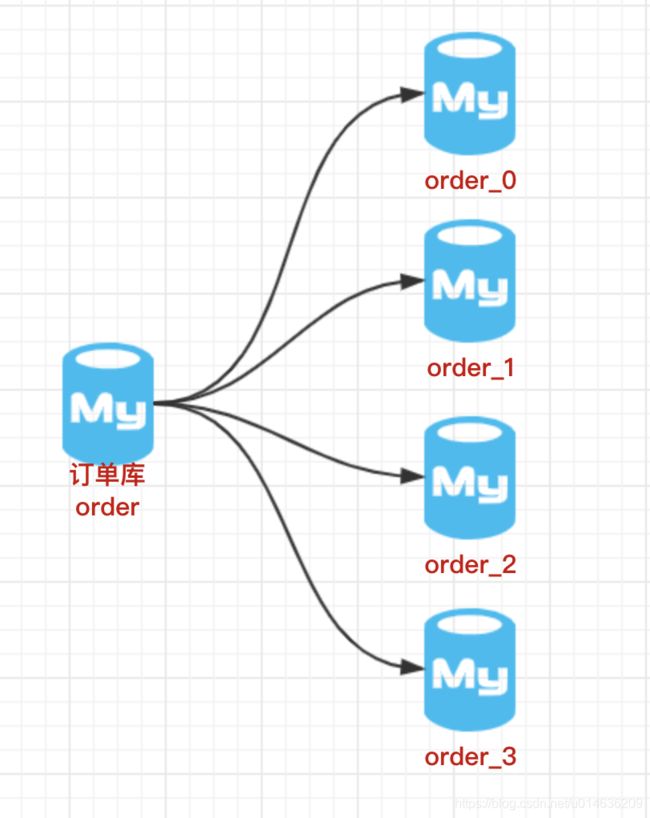
4.2.水平分表
水平分库分表的做法,把单张表的数据按照一定的规则分布到多个数据表。
5.高可用方案
5.1.主从复制
传统的 HAProxy + keepalived 的方案,基于主从复制。
5.2.NDB Cluster
https://dev.mysql.com/doc/mysql-cluster-excerpt/5.7/en/mysql-cluster-overview.html
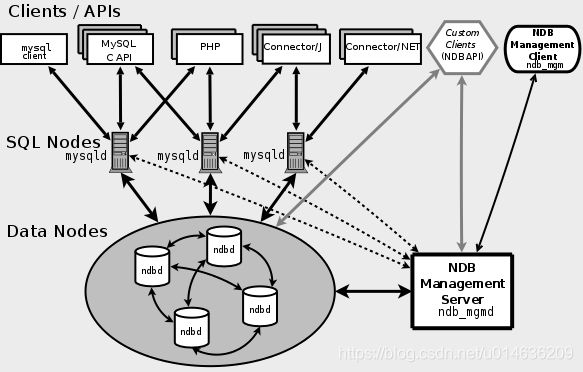
5.2.1.概念
1.NDB Cluster 是一种数据库集群负载的存储引擎
5.3.Galera
5.3.1.官网
https://galeracluster.com/
5.3.2.概念
1.Galera 是针对MySql提供的一种多主同步复制的集群方案的插件;
2.Galera Cluster for MySQL is a true Multi-Master Cluster based on synchronous replication.
It’s an easy-to-use, high-availability solution, which provides high system up-time,
no data loss and scalability for future growth.
Galera Cluster for MySQL是基于同步复制的真正的多主群集。 这是一种易于使用的高可用性解决方案,可提供高系统正常运行时间,
无数据丢失和可扩展性,以适应未来的增长。
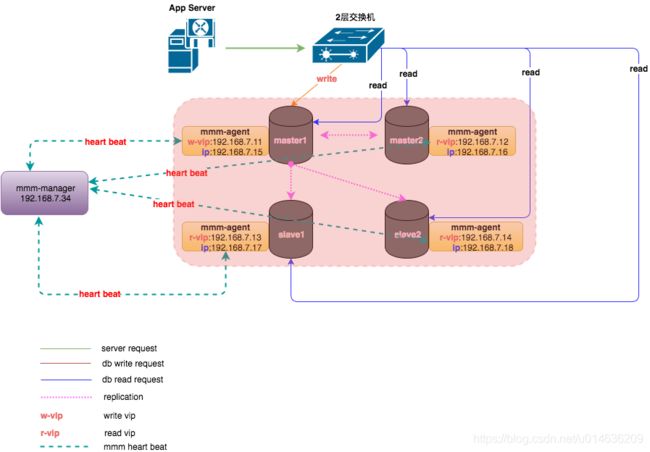
5.4. MHA/MMM
MMM 和 MHA 都是对外提供一个虚拟 IP,并且监控主节点和从节点,当主节点发 生故障的时候,需要把一个从节点提升为主节点,
并且把从节点里面比主节点缺少的数 据补上,把 VIP 指向新的主节点。
5.4.1.MMM
https://tech.meituan.com/2017/06/29/database-availability-architecture.html
5.4.2.MHA
参考地址
https://www.cnblogs.com/keerya/p/7883766.html#_label0

MHA(Master HA)是一款开源的 MySQL 的高可用程序,它为 MySQL 主从复制架构提供了 automating master failover 功能。MHA 在监控到 master 节点故障时,会提升其中拥有最新数据的 slave 节点成为新的master 节点,在此期间,MHA 会通过于其它从节点获取额外信息来避免一致性方面的问题。MHA 还提供了 master 节点的在线切换功能,即按需切换 master/slave 节点。
MHA 是由日本人 yoshinorim(原就职于DeNA现就职于FaceBook)开发的比较成熟的 MySQL 高可用方案。MHA 能够在30秒内实现故障切换,并能在故障切换中,最大可能的保证数据一致性。目前淘宝也正在开发相似产品 TMHA, 目前已支持一主一从。
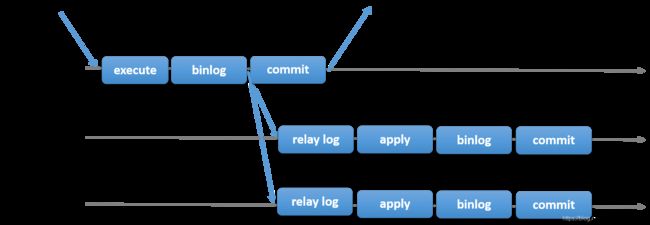
5.5.MGR
https://dev.mysql.com/doc/refman/5.7/en/group-replication-background.html
5.5.1.概念
1.MySQL 5.7.17 版本推出的 InnoDB Cluster,也叫 MySQL Group Replicatioin (MGR),这个套件里面包括了mysql shell和mysql-route。
https://dev.mysql.com/doc/refman/5.7/en/group-replication-primary-secondary-replication.html
5.6.高可用方案总结
1.高可用 HA 方案需要解决的问题都是当一个master节点宕机的时候,如何提升一个数据最新的slave成为master。
如果同时运行多个 master,又必须要解决 master之间数据复制,以及对于客户端来说连接路由的问题。
2.不同的方案,实施难度不一样,运维管理的成本也不一样。
6.优化器——SQL 语句分析与优化
1.优化器就是对我们的 SQL 语句进行分析,生成执行计划。 问题:在我们做项目的时候,有时会收到 DBA 的邮件,
里面列出了我们项目上几个耗时比较长的查询语句,让我们去优化,这些语句是从哪里来的呢?
2.我们的服务层每天执行了这么多 SQL 语句,它怎么知道哪些 SQL 语句比较慢呢? 第一步,我们要把SQL执行情况记录下来。
6.1.慢查询日志 slow query log
6.1.1.官网
https://dev.mysql.com/doc/refman/5.7/en/slow-query-log.html
6.1.2.打开慢日志开关
因为开启慢查询日志是有代价的(跟 bin log、optimizer-trace 一样),所以它默 认是关闭的:
show variables like 'slow_query%';
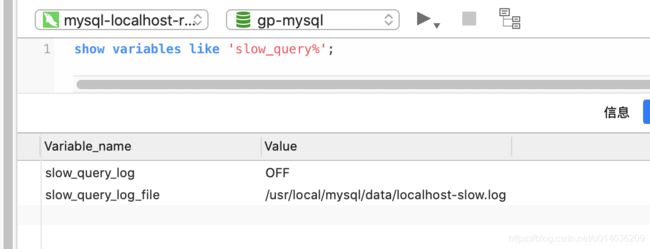
打开开关
set @@global.slow_query_log=1; -- 1 开启,0 关闭,重启后失效
6.1.3.默认时间 10s
show variables like '%long_query%';
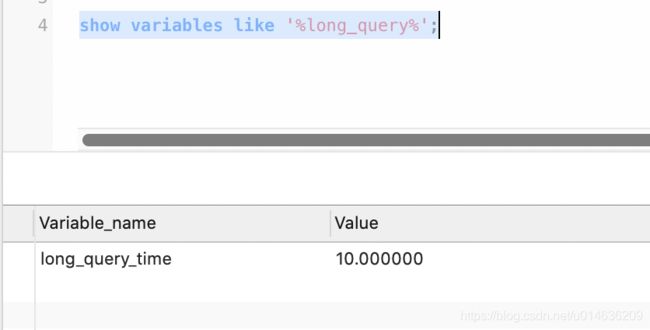
时间
-- mysql默认的慢查询时间是10秒,另开一个窗口后才会查到最新值
set @@global.long_query_time=3;
6.1.4.样例
6.1.4.1.开启慢日志开关
set @@global.slow_query_log=1; -- 1 开启,0 关闭,重启后失效
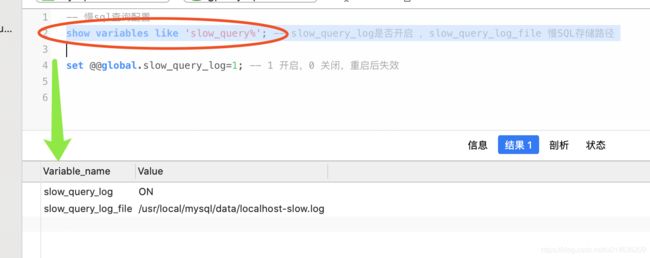
6.1.4.2.设置慢SQL时间为3秒
set @@global.long_query_time=3; -- 设置超过3秒 我们认为是慢SQL
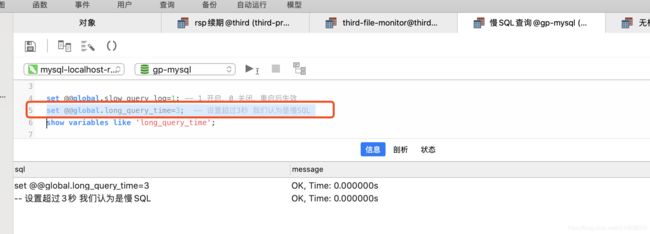
我们现在重新打开一个SQL客户端去查询已经生效,不能再上面的那个客户端去查询
备注:上面的两个配置我们也可以直接在my.conf文件设置
slow_query_log = ON
long_query_time=2
slow_query_log_file =/var/lib/mysql/localhost-slow.log
6.1.4.2.执行select SLEEP(10)
客户端去执行下面的SQL
select SLEEP(10)
这个时候我们去查看localhost-slow.log日志实时输出
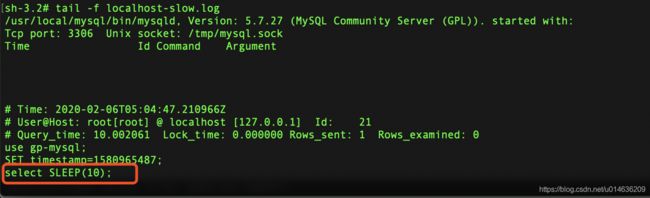
sh-3.2# tail -f localhost-slow.log
/usr/local/mysql/bin/mysqld, Version: 5.7.27 (MySQL Community Server (GPL)). started with:
Tcp port: 3306 Unix socket: /tmp/mysql.sock
Time Id Command Argument
# Time: 2020-02-06T05:04:47.210966Z
# User@Host: root[root] @ localhost [127.0.0.1] Id: 21
# Query_time: 10.002061 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0
use gp-mysql;
SET timestamp=1580965487;
select SLEEP(10);
6.1.5.慢日志分析
https://dev.mysql.com/doc/refman/5.7/en/mysqldumpslow.html
1.MySQL提供了mysqldumpslow的工具,在MySQL的bin目录下。我们可以使用这个工具去统计mysql的慢SQL,进行分析
6.1.5.2.查询用时最多的 5 条慢 SQL
mysqldumpslow -s t -t 5 -g 'select' /usr/local/mysql/data/localhost-slow.log # 后面是你的日志文件目录
sh-3.2#
sh-3.2# mysqldumpslow -s t -t 5 -g 'select' /usr/local/mysql/data/localhost-slow.log
Reading mysql slow query log from /usr/local/mysql/data/localhost-slow.log
Count: 1 Time=10.00s (10s) Lock=0.00s (0s) Rows=1.0 (1), root[root]@localhost
use gp-mysql;
SET timestamp=N;
select SLEEP(N)
Died at /usr/local/mysql/bin/mysqldumpslow line 161, <> chunk 1.
sh-3.2#
6.2.SHOW PROFILE
6.2.1.概念
https://dev.mysql.com/doc/refman/5.7/en/show-profile.html
SHOW PROFILE 是谷歌高级架构师 Jeremy Cole 贡献给 MySQL 社区的,可以查看SQL 语句执行的时候使用的资源,比如 CPU、IO 的消耗情况。
在SQL中输入help profile 可以得到详细的帮助信息。
6.2.2.查看是否开启
select @@profiling; #1 标示开启
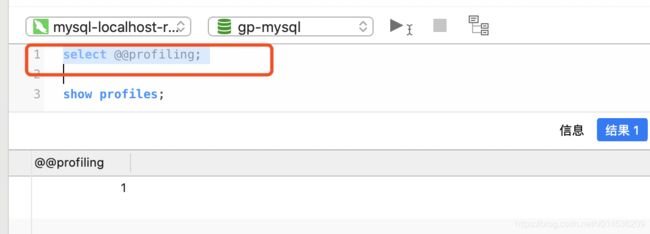
set @@profiling=1;# 如果需要设置,可以使用这个命令
6.2.3.查看 profile 统计
show profiles;
查看最后一个 SQL 的执行详细信息,从中找出耗时较多的环节(没有 s)。
show profile
也可以根据 ID 查看执行详细信息,在后面带上 for query + ID
show profile for query 1;
6.3.其他系统命令
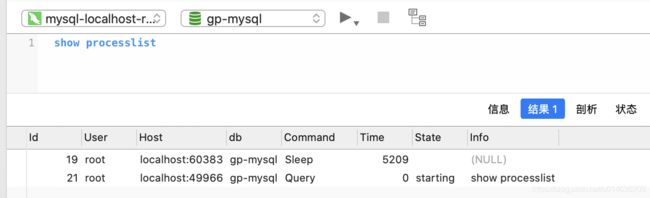
6.3.1.show processlist 运行线程
6.3.1.1.概述
https://dev.mysql.com/doc/refman/5.7/en/show-processlist.html
show processlist
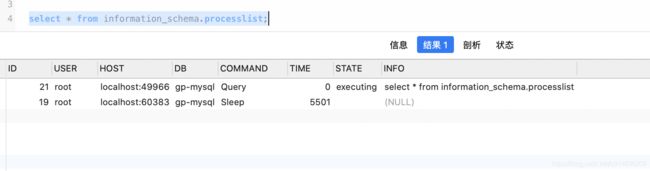
6.3.1.2.通过查询表查询线程状态
select * from information_schema.processlist;


6.3.2.show status 服务器运行状态
6.3.2.1.概述
https://dev.mysql.com/doc/refman/5.7/en/show-status.html
SHOW STATUS 用于查看 MySQL 服务器运行状态(重启后会清空),有session和global 两种作用域,
格式:参数-值。
可以用 like 带通配符过滤。
比如:
SHOW GLOBAL STATUS LIKE 'com_select'; -- 查看 select 次数
6.3.3.show engine 存储引擎运行信息
show engine 用来显示存储引擎的当前运行信息,
包括事务持有的表锁、行锁信息;
事务的锁等待情况;
线程信号量等待;
文件IO请求;
buffer pool统计信息。
show engine innodb status;
6.3.3.show engines 显示所有的存储引擎
show engines;
6.4. Explain
6.4.1.官网
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
查看数据库版本,以及存储引擎
select version();
show variables like '%engine%';
数据准备
DROP TABLE IF EXISTS course;
CREATE TABLE `course` (
`cid` INT(3) DEFAULT NULL,
`cname` VARCHAR(20) DEFAULT NULL,
`tid` INT(3) DEFAULT NULL
) ENGINE = INNODB CHARSET = utf8mb4;
DROP TABLE IF EXISTS teacher;
CREATE TABLE `teacher` (
`tid` INT(3) DEFAULT NULL,
`tname` VARCHAR(20) DEFAULT NULL,
`tcid` INT(3) DEFAULT NULL
) ENGINE = INNODB CHARSET = utf8mb4;
DROP TABLE IF EXISTS teacher_contact;
CREATE TABLE `teacher_contact` (
`tcid` INT(3) DEFAULT NULL,
`phone` VARCHAR(200) DEFAULT NULL
) ENGINE = INNODB CHARSET = utf8mb4;
INSERT INTO `course`
VALUES ('1', 'mysql', '1');
INSERT INTO `course`
VALUES ('2', 'jvm', '1');
INSERT INTO `course`
VALUES ('3', 'juc', '2');
INSERT INTO `course`
VALUES ('4', 'spring', '3');
INSERT INTO `teacher`
VALUES ('1', 'qingshan', '1');
INSERT INTO `teacher`
VALUES ('2', 'jack', '2');
INSERT INTO `teacher`
VALUES ('3', 'mic', '3');
INSERT INTO `teacher_contact`
VALUES ('1', '13688888888');
INSERT INTO `teacher_contact`
VALUES ('2', '18166669999');
INSERT INTO `teacher_contact`
VALUES ('3', '17722225555');
6.4.2.
EXPLAIN SELECT tc.phone
FROM teacher_contact tc
WHERE tcid = (
SELECT tcid
FROM teacher t
WHERE t.tid = (
SELECT c.tid
FROM course c
WHERE c.cname = 'mysql'
)
);