论文阅读【CenterNet】
代码:https://github.com/xingyizhou/CenterNet
论文地址: https://arxiv.org/abs/1904.08189
还有一篇 重名?https://arxiv.org/pdf/1904.08189.pdf https://github.com/Duankaiwen/CenterNet


文章要点:
针对基于anchor的检测方法(yolo v2-yolo v3,SSD ,faster-rcnn)在特征图中产生大量的bounding box 用于分类和位置修正,要求大量的计算资源消耗,额外的后处理,Loss复杂等。
文章就提出anchor-free的方式,通过Keypoint(中心点)和距离中心点的box的w,h回归box大小,外加offset偏移,这就节省了NMS操作。本文也是对CornerNet的改进。
实验结果:COCO数据上表现出:
| AP | FPS |
|---|---|
| 28.1% | 142FPS |
| 37.4% | 52FPS |
| 45.1% | 1.4FPS |
LOSS定义:
一:中心关键点Y的Loss
LOSS分为3个部分,首先,为中心关键点Y的Loss:
对于一幅输入(W, H)图像, 经过CNN产生一个heatMap = W R × H R × C \frac{W}{R}\times \frac{H}{R}\times C RW×RH×C,用 Y ~ \widetilde{Y} Y 代表, Y ~ \widetilde{Y} Y ϵ \epsilon ϵ[0,1], C表示关键点的类型数(维度?),例如,人体姿态估计C=17个关节点,C=80个目标检测物体类别,R表示特征图相比输入图缩放倍数,一般默认R=4,即heatmap缩小为原图的1/4.
首先groundtruth生成的关键点为 P P P(具体先不解释这个,把BOX的坐标转换来的吧,),显示在预测低分辨率heatmap上为 P ^ \widehat{P} P = P / R P/R P/R, 作者把CNN会生成heatmap 坐标 与GroudTruth关键点使用高斯核函数标准化, σ p 2 \sigma _{p}^{2} σp2表示自适应的标准方差。
![]()
Y ^ x , y , c \widehat{Y}_{x,y,c} Y x,y,c=1, 表示检测到一个关键点,
Y ^ x , y , c \widehat{Y}_{x,y,c} Y x,y,c=0,表示为背景
定义使用focal Loss: α \alpha α =2 , β \beta β=4 设为常数

二:offset Loss
缩小的 输出heatmap 恢复到原图,中心点可能差生误差,需要添加一个位移偏置损失,先在处采集局步关键点(?没看懂):
![]()
作者后面说O等于这个,后面看懂博主补充下:

然后算偏移量

三、box 大小损失(这里没有IOU哦)
Groudtruth 坐标为( X m i n X_{min} Xmin, Y m i n Y_{min} Ymin, X m a x X_{max} Xmax, Y m a x Y_{max} Ymax), 中心点为 P k P_{k} Pk为:
![]()
S k S_{k} Sk表示box的W,H:
![]()
坐标损失用预测的(w,h)集合 S ^ p k \widehat{S}_{pk} S pk与每个关键点P的GroundTruth标记的(w,h)相减求平均值
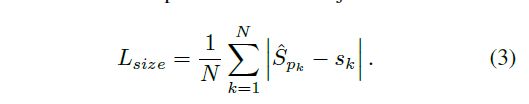
总的Loss定义为: 中心点损失+偏移损失+box大小损失, λ s i z e \lambda_{size} λsize=0.1 , λ o f f \lambda_{off} λoff=1 ,用于权衡各项损失的比重
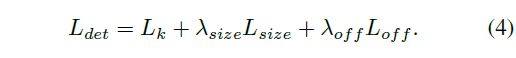
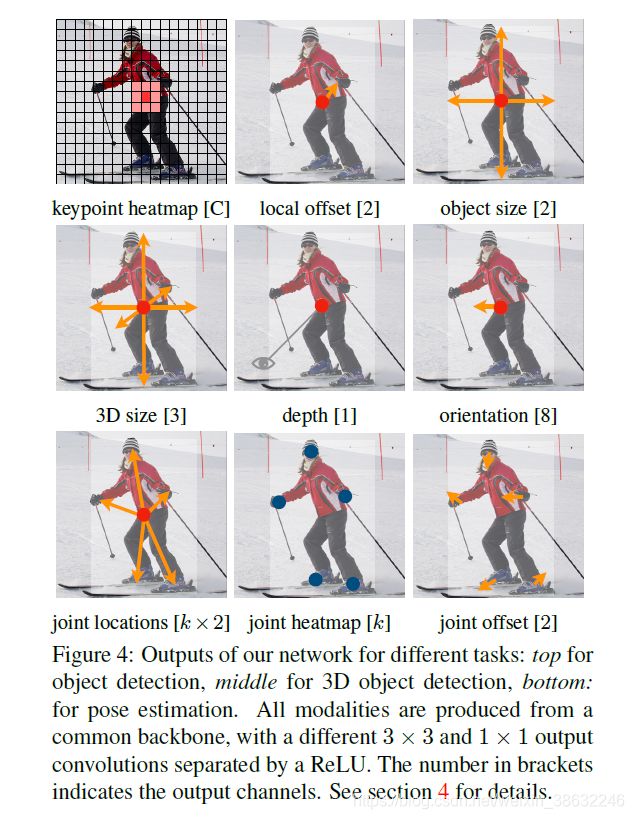
放张图,缓解一下硬核理论:
文章中给的实验对比图,可以稍作参考, 具体表现还真不能拿这个定,亲测。。。。
