Datawhale组队学习NLP_情感分析baseline updated学习笔记
本文为学习Datawhale 2021.9组队学习情感分析笔记
原学习文档地址:https://github.com/datawhalechina/team-learning-nlp/tree/master/EmotionalAnalysis
baseline笔记见https://blog.csdn.net/weixin_43634785/article/details/120289701?spm=1001.2014.3001.5502
baseline存在很多可以优化的地方,比如
- 使用预训练词向量
- 把RNN网络换成双向LSTM网络
- 由于参数量的提升加入正则项
- 尝试不同的优化器
接下来就从上述几个方面对baseline进行修改
1 RNN网络换成LSTM网络
实例化模型
"""5.Model"""
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
HIDDEN_DIM = 256
OUTPUT_DIM = 1
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.5
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
# UNK_IDX 不用传进去,因为PAD不需要计算而UNK需要计算
model = RNN(INPUT_DIM,
EMBEDDING_DIM,
HIDDEN_DIM,
OUTPUT_DIM,
N_LAYERS,
BIDIRECTIONAL,
DROPOUT,
PAD_IDX)
模型定义
class RNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers,
bidirectional, dropout, pad_idx):
super().__init__()
# embedding嵌入层(词向量)
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)
# RNN变体————双向LSTM
self.rnn = nn.LSTM(embedding_dim, # input_size
hidden_dim, #output_size
num_layers=n_layers, # 层数
bidirectional=bidirectional, #是否双向
dropout=dropout) #随机去除神经元
# 线性连接层
self.fc = nn.Linear(hidden_dim * 2, output_dim)
# 前向传播+后向传播两个hidden_state,且合并在一起,所以×2
# 随机去除神经元
self.dropout = nn.Dropout(dropout)
def forward(self, text, text_lengths):
# text的形状 [sent len, batch size]
embedded = self.dropout(self.embedding(text))
# embedded的形状 [sent len, batch size, emb dim]
# pack sequence
# lengths need to be on CPU!
# 把embedded包进来,避免了后面还计算pad部分
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths.to('cpu'))
packed_output, (hidden, cell) = self.rnn(packed_embedded)
# unpacked sequence
output, output_lengths = nn.utils.rnn.pad_packed_sequence(packed_output)
# output的形状[sent len, batch size, hid dim * num directions]
# output 中的 padding tokens 是数值为0的张量
# hidden 的形状 [num layers * num directions, batch size, hid dim]
# cell 的形状 [num layers * num directions, batch size, hid dim]
# concat the final forward (hidden[-2,:,:]) and backward (hidden[-1,:,:]) hidden layers
# and apply dropout
hidden = self.dropout(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim = 1))
return self.fc(hidden)
-
注意此处forward过程与baseline中RNN的区别,这里除了传入text外,还传入了text_length,在forward过程中需要使用到,效果就是模型算到这个位置的时候就停止计算。否则输出的大部分都是在pad位置的输出。那么问题是感觉baseline中的RNN效果不好的一部分原因是不是没有进行这个操作呢?
-
对forward过程举个例子进行说明
前向的输入:
text, text_lengths = batch.text # batch.text返回的是一个元组(数字化的张量,每个句子的长度)
model(text, text_lengths)
text的形状:[sent len, batch size]
实例: text=[745, 64] 一个batch64个句子,句子长度最长是745
text 输入到 embedding [vocab_size, embedding dim] 得到embedded [sent len, batch size, emb dim]
实例:embedding=[25002, 100] embedded=[745, 64, 100]
embedded 输入到 pack_padded_sequence 里 得到 packed_embedded
这一步主要是为了让pad token不参与参数的更新 ,注意 lengths need to be on CPU!
packed_embedded 输入到 RNN 中 会判断是否为PackedSequence 最后输出得到 packed_output, (hidden, cell)
如果要使用输出需要对packed_output解压
output和hidden, cell
output的维度是[745, 64, 512],这里745是句子长度,64个句子,512是因为hidden size=256, 两层lstm拼接起来就是512
ouput_length:
tensor([745, 745, 744, 744, 743, 743, 742, 738, 738, 738, 738, 736, 734, 734,
734, 734, 733, 732, 731, 731, 730, 730, 729, 728, 727, 727, 726, 726,
725, 723, 723, 723, 722, 722, 721, 721, 720, 720, 719, 716, 716, 715,
715, 715, 713, 712, 712, 711, 707, 707, 707, 706, 705, 704, 703, 702,
702, 701, 701, 700, 699, 699, 699, 698])
记录了每个句子的长度,可以看到这个迭代器是会自动排序的,把长度相似的句子都放在一起,减少padding 的数量
output[0]
tensor([[-0.0019, 0.0004, -0.0030, ..., -0.0097, 0.0420, 0.0041],
[ 0.0034, 0.0361, -0.0009, ..., -0.0292, 0.0479, 0.0052],
[ 0.0123, 0.0347, 0.0076, ..., -0.0316, -0.0182, -0.0500],
...,
[-0.0454, 0.0027, -0.0149, ..., -0.1120, 0.0238, -0.0076],
[-0.0103, 0.0637, 0.0412, ..., -0.0712, 0.0208, -0.0349],
[-0.0093, 0.0435, 0.0166, ..., -0.0712, 0.0133, -0.0321]],
grad_fn=<SelectBackward>)
ouput[744]:
tensor([[ 0.0110, 0.0757, -0.0370, ..., 0.0177, -0.0130, -0.0178],
[-0.0145, 0.0666, -0.0171, ..., -0.0171, 0.0181, 0.0005],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
...,
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]],
grad_fn=<SelectBackward>)
从这两个的输出可以明显看到,句子长度不够的输出就是0
- 接下来看看hidden是什么样子的
hidden和cell的维度 [4, 64, 255]
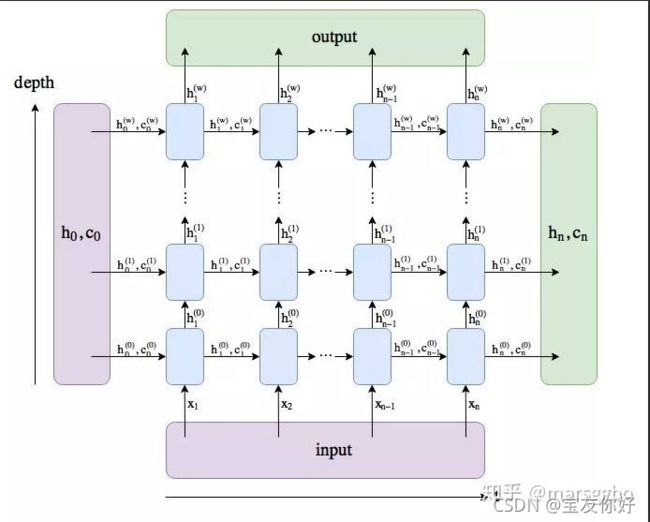
hidden是各层向右输出,output是模型向上的输出
hidden 的形状 [num layers * num directions, batch size, hid dim]
cell 的形状 [num layers * num directions, batch size, hid dim]
因为超参N_LAYERS = 2 又bidirectional=True双向两层lstm,num directions=2, 所以拼接起来就是4层的hidden output
- 参考:https://zhuanlan.zhihu.com/p/79064602
bi-lstm的模型其实就是两个分开lstm模型,只是使用的时候把他们各自的输出和hidden拼接起来。
这篇文章里提到了为什么很多数据里都有T转置这个矩阵的量,应该是与batch_first有关
还提到了为什么lstm要进行pack操作,与RNN不同,对lstm一直输入pad(0)也会对输出有影响,所以要记录pad前的那个位置,计算到此处后面就都不管了,具体细节可以看上面那篇文章。之前的baseline使用的普通RNN没有进行pack操作,如果使用了pack,会提点见6
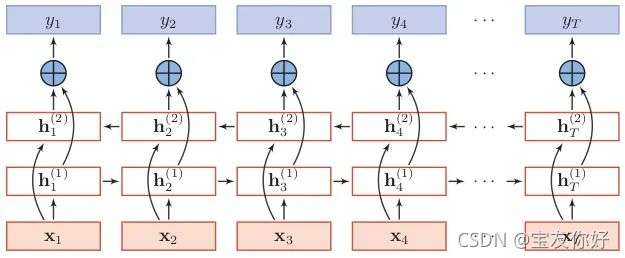
- 为什么最后concat取的是
hidden[-2,:,:], hidden[-1,:,:]
下图是一个双向lstm的结构
而这个图是一个w+1层的也就是num_layers=2的lstm的结构
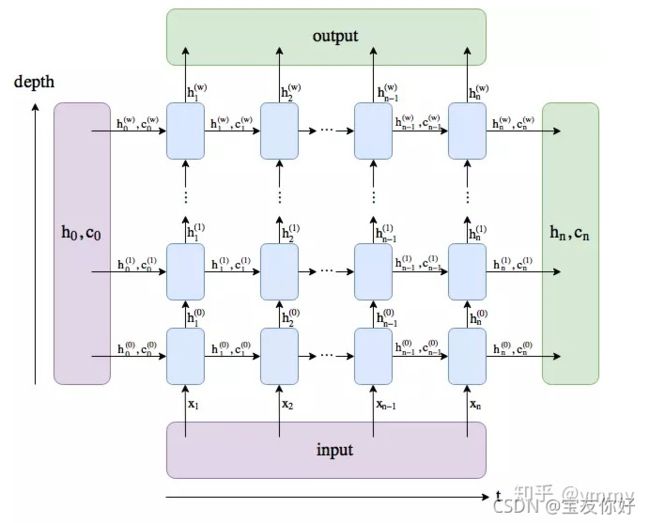
参考 https://zhuanlan.zhihu.com/p/39191116
举个例子,我们定义一个num_layers=3的双向LSTM,h_n第一个维度的大小就等于 6 (2*3),h_n[0]表示第一层前向传播最后一个time step的输出,h_n[1]表示第一层后向传播最后一个time step的输出,h_n[2]表示第二层前向传播最后一个time step的输出,h_n[3]表示第二层后向传播最后一个time step的输出,h_n[4]和h_n[5]分别表示第三层前向和后向传播时最后一个time step的输出。
所以模型的每一层都是一个双向lstm,而不是向左三层加向右三层的堆叠。取-2,-1就是最后一层的前向和后向的输出。
注意:
在将embeddings(词向量)输入RNN前,我们需要借助nn.utils.rnn.packed_padded_sequence将它们‘打包’,以此来保证RNN只会处理不是pad的token。我们得到的输出包括packed_output (a packed sequence)以及hidden sate 和 cell state。如果没有进行‘打包’操作,那么输出的hidden state和cell state大概率是来自句子的pad token。如果使用packed padded sentences,输出的就会是最后一个非padded元素的hidden state 和 cell state。
之后我们借助nn.utils.rnn.pad_packed_sequence 将输出的句子‘解压’转换成一个tensor张量。需要注意的是来自padding tokens的输出是零张量,通常情况下,我们只有在后续的模型中使用输出时才需要‘解压’。虽然在本案例中下不需要,这里只是为展示其步骤。
2 使用预训练词向量
选取GloVe词向量,GloVe的全称是:Global Vectors for Word Representation。此处有关于其有详细的介绍和大量资源。本教程将不介绍该词向量是如何具体得到的,仅简单描述下如何使用此词向量,这里我们使用的是 “glove.6B.100d” ,其中,6B表示词向量是在60亿规模的tokens上训练得到的,100d表示词向量是100维的(注意,这个词向量有800多兆)
TEXT.build_vocab表示从预训练的词向量中,将当前训练数据中的词汇的词向量抽取出来,构成当前训练集的 Vocab(词汇表)。对于当前词向量语料库中没有出现的单词(记为UNK,unknown),通过高斯分布随机初始化(unk_init = torch.Tensor.normal_)。
MAX_VOCAB_SIZE = 25_000
TEXT.build_vocab(train_data,
max_size = MAX_VOCAB_SIZE,
vectors = "glove.6B.100d",
unk_init = torch.Tensor.normal_)
LABEL.build_vocab(train_data)
pretrained_embeddings = TEXT.vocab.vectors
# 检查词向量形状 [vocab size, embedding dim]
print(pretrained_embeddings.shape)
# 用预训练的embedding词向量替换原始模型初始化的权重参数
model.embedding.weight.data.copy_(pretrained_embeddings)
#将unknown 和padding token设置为0 它们与情感无关。
UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token]
model.embedding.weight.data[UNK_IDX] = torch.zeros(EMBEDDING_DIM)
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM)
输入是一个单位矩阵 embedding是一个[25002, 100]的矩阵,每一行就代表一个单词的向量
这样输入乘embedding就得到了[25002, 100] 相当于输入就是一个用于索引的矩阵
需要注意的是,pad token的词向量在模型训练过程中始终不会被学习。而unknown token的词向量是会被学习的。
可以看到在模型初始化的时候,unknown token就没有传入,只有pad token传入了。也有把unk词向量设置为所有词的均值
class RNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers,
bidirectional, dropout, pad_idx):
3 使用Adam优化器
import torch.optim as optim
optimizer = optim.Adam(model.parameters())
4 模型验证
"""9.Test"""
# 由于上面只保存了模型的state_dict,没有保存模型的定义,所以如果要分开运行的话这里要重新定义模型
model.load_state_dict(torch.load('tut2-model.pt'))
test_loss, test_acc = evaluate(model, test_iterator, criterion)
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')
保存state_dict和model的区别
对于仅保存state_dict()的方式,那保存和加载模型的方式为:
保存:torch.save(model.state_dict(), PATH)
加载:model.laod_state_dict(torch.load(PATH))
一般加载模型是在训练完成后用模型做测试,这时候加载模型记得要加上model.eval(),把模型切换到evaluation模式,这时候会调整dropout和bactch的模式。
对于保存和加载整个模型的情况:
torch.save(model, PATH)
model = torch.load(PATH)
可以看到,前面的model.load_state_dict()和这里的不同,前面的情况需要你先定义一个模型,然后再load_state_dict()
但是这里load整个模型,会把模型的定义一起load进来。完成了模型的定义和加载参数的两个过程。
import spacy
nlp = spacy.load('en_core_web_sm')
def predict_sentiment(model, sentence):
model.eval() # 模型切换为evaluate模式
tokenized = [tok.text for tok in nlp.tokenizer(sentence)] # 对句子进行分词操作
indexed = [TEXT.vocab.stoi[t] for t in tokenized] # 将分词后的每个词,对应着词汇表,转换成对应的index索引
length = [len(indexed)] # 获取句子的长度
tensor = torch.LongTensor(indexed).to(device) # 将indexes,从list转化成tensor
tensor = tensor.unsqueeze(1) # 将length转化成张量tensor
length_tensor = torch.LongTensor(length) # 用sigmoid将预测值压缩到0~1之间
prediction = torch.sigmoid(model(tensor, length_tensor))
return prediction.item() # 用item()方法,将只有一个值的张量tensor转化成整数0
所以如果想要单独运行模型验证部分,最好在保存模型的时候使用torch.save(model, PATH),这样就不需要再定义模型了。
5 一些重要的点
1.针对模型训练过程中的一点补充:在模型训练过程中,对于每个样本中补齐后加上的pad token,模型是不应该对其进行训练的,也就是并不会学习“
2.因为实验中使用的双向LSTM的包含了前向传播和后向传播过程,所以最后的隐藏状态向量包含了前向和后向的隐藏状态,所以在下一层nn.Linear层中的输入的形状就是隐藏层维度形状的两倍。
3.在将embeddings(词向量)输入RNN前,我们需要借助nn.utils.rnn.packed_padded_sequence将它们‘打包’,以此来保证RNN只会处理不是pad的token。我们得到的输出包括packed_output (a packed sequence)以及hidden sate 和 cell state。如果没有进行‘打包’操作,那么输出的hidden state和cell state大概率是来自句子的pad token。如果使用packed padded sentences,输出的就会是最后一个非padded元素的hidden state 和 cell state。
4.之后我们借助nn.utils.rnn.pad_packed_sequence 将输出的句子‘解压’转换成一个tensor张量。需要注意的是来自padding tokens的输出是零张量,通常情况下,我们只有在后续的模型中使用输出时才需要‘解压’。虽然在本案例中下不需要,这里只是为展示其步骤。
5.final hidden sate:也就是hidden,其形状是[num layers * num directions, batch size, hid dim]。因为我们只要最后的前向和后向传播的hidden states,我们只要最后2个hidden layers就行hidden[-2,:,:] 和hidden[-1,:,:],然后将他们合并在一起,再传入线性层linear layer。
#####这里不知道怎么解释会比较好,还需调整。
对于第5点,hidden的索引是怎么排的?
参考 https://pytorch.org/docs/1.7.1/generated/torch.nn.LSTM.html?highlight=lstm#torch.nn.LSTM
If the LSTM is bidirectional, num_directions should be 2, else it should be 1.
所以num directions的1,2索引应该是指的方向,num layers都是-1就指的是取最后一层。
6 对baseline中的普通RNN进行了pack操作
使用pack操作要注意几点
- 创建BucketIterator迭代器时设置sort_within_batch=True,
- RNN的输出只有两项即output和hidden,
packed_output, hidden = self.rnn(packed_embedded)
baseline:
Epoch: 01 | Epoch Time: 0m 13s
Train Loss: 0.694 | Train Acc: 49.89%
Val. Loss: 0.694 | Val. Acc:49.49%
Epoch: 02 | Epoch Time: 0m 13s
Train Loss: 0.693 | Train Acc: 50.31%
Val. Loss: 0.695 | Val. Acc:50.63%
Epoch: 03 | Epoch Time: 0m 13s
Train Loss: 0.693 | Train Acc: 50.26%
Val. Loss: 0.694 | Val. Acc:49.66%
Epoch: 04 | Epoch Time: 0m 13s
Train Loss: 0.693 | Train Acc: 49.77%
Val. Loss: 0.694 | Val. Acc:49.41%
Epoch: 05 | Epoch Time: 0m 13s
Train Loss: 0.693 | Train Acc: 50.05%
Val. Loss: 0.694 | Val. Acc:49.39%
Test Loss: 0.708 | Test Acc:47.74%
baseline+pad:
Epoch: 01 | Epoch Time: 0m 5s
Train Loss: 0.693 | Train Acc: 50.88%
Val. Loss: 0.692 | Val. Acc:52.20%
Epoch: 02 | Epoch Time: 0m 5s
Train Loss: 0.692 | Train Acc: 51.98%
Val. Loss: 0.691 | Val. Acc:53.03%
Epoch: 03 | Epoch Time: 0m 5s
Train Loss: 0.691 | Train Acc: 52.65%
Val. Loss: 0.690 | Val. Acc:53.72%
Epoch: 04 | Epoch Time: 0m 5s
Train Loss: 0.690 | Train Acc: 53.42%
Val. Loss: 0.689 | Val. Acc:53.50%
Epoch: 05 | Epoch Time: 0m 5s
Train Loss: 0.689 | Train Acc: 53.91%
Val. Loss: 0.688 | Val. Acc:53.64%
Test Loss: 0.689 | Test Acc:53.78%
明显有提升
7 遇到的环境问题
7.1 torchtext版本问题
安装torchtext时,当前的torch版本为1.8.1,无法兼容最新版本的torchtext,百度后安装了版本要求为1.8.0的torchtext==0.9,
安装torchtext的过程中还是给安装了1.8.0版本的torch,输入condal ist显示有两个版本的torch,
这时环境不再支持gpu训练,所以卸载了新安装的1.8.0版本torch,
import torch后显示ModuleNotFoundError: No module named 'torch',之后安装了原来1.8.1版本的torch,gpu还是无法使用。
没办法只能重新装了环境。torchtext只支持大版本的torch吗?
7.2 gpu
原来的cuda设置
# 根据当前环境选择是否调用GPU进行训练
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
只占用了显存,但gpu的利用率是0%,没有设置用哪块显卡?改成以下可以正常运行
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
参考:
https://zhuanlan.zhihu.com/p/79064602
https://zhuanlan.zhihu.com/p/100360301
https://zhuanlan.zhihu.com/p/39191116