2020 ACL《CoGAN》- Aspect Sentiment Classification with Document-level Sentiment Preference Modeling
2020 ACL 《CoGAN》-Aspect Sentiment Classification with Document-level Sentiment Preference Modeling
- Abstract
- 1 Introduction
- 3 Cooperative Graph Attention Networks (CoGAN)
-
- 3.1 Basic Graph Attention Network
- 3.2 Encoding Block
- 3.3 Intra-Aspect Consistency Modeling Block
- 3.4 Inter-Aspect Tendency Modeling Block
- 3.5 Interaction Block
- 3.6 Softmax Decoding Block
- 3.7 Model Training
- 4 Experimentation
-
- 4.1 Experimental Settings
-
- 4.1.1 Dataset
- 4.1.2 Implementation Details
- 4.2 Experimental Results
- 消融试验
- 5 Analysis and Discussion
-
- 5.1 Case Study
- 5.2 Effectiveness Study (还要再看看,没看懂那个比率啥意思)
- 5.3 Error Analysis
- 6 Conclusion
ACL 2020的文章:文章地址
每个datasets 由不同的 reviews 文件(document)表示
Abstract
在文献中,现有的研究总是将方面情感分类作为一个独立的句子层面的分类问题,在很大程度上忽略了文档层面的情感偏好信息,但显然这种信息对于缓解方面情感分类中的信息不足问题至关重要。本文探讨了文档内部的两种情感偏好信息,即同一方面的上下文情感一致性(即方面内情感一致性)和所有相关方面的上下文情感倾向(即方面间情感倾向)。在此基础上,我们提出了一种合作图注意网络(Cooperative Graph Attention Networks (Co-GAN))方法,用于合作学习aspect-related sentence representation。具体来说,利用两个GAT(图注意力网络,Graph Attention Network,GAT)分别对上述两种文档级情感偏好信息进行建模,并通过交互机制整合这两种偏好。详细的评估表明,与最先进的基线相比,所提出的ASC方法具有很大的优势。这证明了文档级别的情感偏好信息对自动服务中心的重要性,以及我们获取此类信息的方法的有效性。
1 Introduction
-
在文献中,给定ASC数据集,其中 aspect (即实体和属性)被逐句人工注释,先前的研究逐句独立地对方面情感建模,其忽略了文档级情感偏好信息。在本文中,我们认为这种文档级的情感偏好信息对于弥补ASC中的信息缺失问题起到重要作用。特别地,我们探索了文档中的两种情感偏好信息。
- 我们假设文档中涉及相同方面的句子在这个方面倾向于具有相同的情感极性。即,方面内情感一致性。

例如,在Document1中,S1和S2中都含有 AMBIENCE#GENERAL。但是,利用 S1 中的 “interior could use some help” 显然比 S2 中的 clause “without it trying to be that” 容易判断 AMBIENCE#GENERAL 是 negative。由于同一document 方面内情感一致性,所以可以利用S1辅助判断S2 AMBIENCE#GENERAL 的情感极性。
疑问:那这样整个文件所有同一 aspect 岂不是都是同一个情感极性了?
- 我们假设文档(document)中的句子在所有相关方面都有相同的情感极性。即,方面间情感倾向。
- 我们假设文档中涉及相同方面的句子在这个方面倾向于具有相同的情感极性。即,方面内情感一致性。

例如,Document2中的S2包含多个aspect,很难准确地为每个aspect预测情感极性。(我觉得人看的话,还是很好预测的啊。不知道机器可能识别不了?搞不懂…)当考虑句子的上下文时,由于S2相邻句子S1、S3中的aspect的情感记性都是positive,所以S2中的每个aspect很大可能也都是positive。即,方面间情感倾向。
以上数据集文件获取地址: SemEval-2016 ABSA Restaurant Reviews-English: Test Data-Phase B (Subtask 2)
为了很好地适应上述两种文档级情感偏好信息,本文提出了 GoGAN 模型。具体地说, CoGAN 构建了两个 GAT 来建模以上两种文档级的情感偏好。其中,用 attention weight来衡量 偏好度preference-degree。此外,考虑到这两种情感偏好可以共同影响方面的情感极性,我们提出了一种交互机制来共同建模两种情感偏好,以获得更好的方面相关句子表示(aspect-related sentence representation)。
3 Cooperative Graph Attention Networks (CoGAN)
符号定义:
- document D = s 1 , s 2 , . . . , s I D = {s_1, s_2, ..., s_I} D=s1,s2,...,sI,D 中含有 I I I 个句子;
- document D 中含有 K K K 个aspect, 其中 aspect a k a_k ak,k ∈ {1,2, …, K};
- ASC 任务:根据 the aspect-related sentence representation r i r_i ri of sentence s i s_i si 预测 a k a_k ak 的情感极性。
其中,document 中的 每个句子:Like Pontiki et al. (2015), all aspects of every sentence are unrolled in a document. For instance, a sentence with two aspects occurs twice in succession, once with each aspect.
本文提出了 GoGAN 模型,它利用两个 GAT 分别学习两种文档级的情感偏好。GoGAN 模型架构图如图2所示,其主要包含一下五个部分:
- Encoding Block;
- Intra-Aspect Consistency Modeling Block;
- Inter-Aspect Tendency Modeling Block;
- Interaction Block;
- Softmax Decoding Block.

3.1 Basic Graph Attention Network
GAT 能为不同顶点指定不同的attention权重。原则上,GAT可以聚合相邻节点的特征,也可以将一个顶点的信息传播到其最近的邻居。从这一点来看,GAT 能够充分地模拟局部上下文信息,用于学习每个顶点的表示。

其中,符号定义如下:

3.2 Encoding Block
BERT(Devlin et al,2019)可以背微调用于多个 NLP 任务中,例如,text classification and natural language inference。
本文使用 BERT-base 来 encode aspect and the sentence。
-
Aspect Encoding
由于 aspect a k a_k ak 包含entity e e n t i t y e_{entity} eentity 和 attribute e a t t r i b u t e e_{attribute} eattribute,所以在 BERT 中使用下图来表示 entity-attribute pair : ( e e n t i t y , e a t t r i b u t e ) (e_{entity}, e_{attribute}) (eentity,eattribute)

其中,我们将 entity-attribute pair 喂给 BERT,然后将 “[CLS]” 作为 aspect a k a_k ak 的 aspect vector e k e_k ek。其中, e k ∈ R d e_k \in R^d ek∈Rd。 -
Sentence Encoding
本文引用 Sun et al.(2019) 的方法来生成 aspect related sentence representation。其做法如下:- 首先,将 sentence s i s_i si 以及它包含的 aspect a k a_k ak转化为如下 BERT 的 input pair 形式:
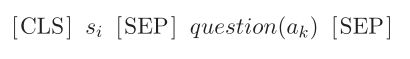
其中, q u e s t i o n ( ⋅ ) question(·) question(⋅) 表示 Sun et al(2019) 中提出的创建 aspect a k a_k ak 对应的辅助疑问句。例如,FOOD#PRICE 的辅助疑问句可以付创建为:“what do you think of the food and price?” - 然后,将以上 input pair 喂给 BERT 来获得句子 s i s_i si 的 aspect-related sentence vector v i ∈ R d v_i \in R^d vi∈Rd;
- 此外,此外,我们微调BERT,并根据 公式(8) 更新 aspect vector e k e_k ek 和 sentence vector v i v_i vi。
- 首先,将 sentence s i s_i si 以及它包含的 aspect a k a_k ak转化为如下 BERT 的 input pair 形式:
3.3 Intra-Aspect Consistency Modeling Block
本文提出一种一致性感知的图注意力网络(a consistency-aware GAT)来建模方面内情感一致性(intra-aspect consistency)。
符号定义:
- 给定一个含有 I I I 个句子的 document D = s 1 , s 2 , . . . , s I D = {s_1, s_2, ..., s_I} D=s1,s2,...,sI,;
- 一致性感知的图注意力网络(a consistency-aware GAT)可以别表示为一个二分图(bipartite graph) : G ( S ∪ A , E s a ) G(S\cup A, E_{sa}) G(S∪A,Esa)。
其中,S 和 A 为两个不相交的集合,分别表示 sentence vertices 和 aspect vertices。 E s a E_{sa} Esa 表示 sentence s i ∈ S s_i \in S si∈S 和 document D中 s i s_i si对应的 aspect a k ∈ A a_k \in A ak∈A 顶点之间边的集合。 - sentence s i s_i si 对应的 sentence vector v i ∈ R d v_i \in R^d vi∈Rd
- aspect a k a_k ak 对应的 aspect vector e k ∈ R d e_k \in R^d ek∈Rd
- intra-aspect consistency 被表述为: 同一 document 中同一 aspect 顶点 a k a_k ak的 句子顶点 { s i } i = 1 I ′ \{{s_i}\}_{i=1}^{I'} {si}i=1I′ 在 a k a_k ak 上具有相同的情感极性。其中, I ′ I' I′表示含有同一 aspect 顶点 a k a_k ak的句子数量。然而,仍然可能存在一些情感不一致的情况。
本文使用 GAT 来计算 preference-degree,其中attention weight (preference-degree) 根据 GAT 计算 sentence vertex s i s_i si 和 aspect vertex a k a_k ak 之间的 edge weight 作为 preference-degree。公式如下:


作为 G ( S ∪ A , E s a ) G(S\cup A, E_{sa}) G(S∪A,Esa) 中一个顶点,sentence s i s_i si 被encode为aspect-related sentence representation ![]() ,公式如下:
,公式如下:
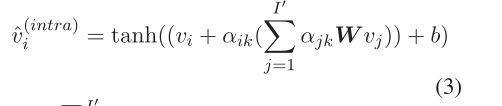

3.4 Inter-Aspect Tendency Modeling Block
我们使用一种我们利用一个趋势感知的GAT(tendency-aware)来建模方面间的趋势(inter-aspect tendency)。
符号定义:
- 给定一个含有 I I I 个句子的 document D = s 1 , s 2 , . . . , s I D = {s_1, s_2, ..., s_I} D=s1,s2,...,sI,;
- 趋势感知的GAT(tendency-aware GAT)可以别表示为一个有向图: G ( S , E s s ) G(S, E_{ss}) G(S,Ess)
其中,S 为句子顶点集合。 E s s E_{ss} Ess表示边的集合,每条边表示 document D中两个句子顶点 s i s_i si 和 s j s_j sj之间的边。 - inter-aspect tendency 假设:在同一document D 中,句子顶点 s i s_i si 与其邻居节点 { s j } j = 1 I \{{s_j}\}_{j=1}^I {sj}j=1I 具有相同情感极性。
疑问:这里文中好像没有提到使用语法信息(比如,依赖树),那么这里的 GAT 是怎么判断两个 顶点 是相邻的?仅仅是物理位置上相邻?
与 intra-aspect consistency modeling block 类似,根据公式(1)[GAT] 计算同一 document 中两个句子顶点 s i s_i si 和 s j s_j sj 之间的 attention 权重 α i j \alpha_{ij} αij。公式如下:

根据公式(1), G ( S , E s s ) G(S, E_{ss}) G(S,Ess) 中的 sentence顶点 s i s_i si 可以被encode为以下 sentence representation ![]()
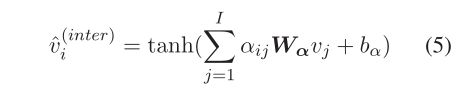
3.5 Interaction Block
将以上两个 block 学到的 ![]() 做一个 interactive mechanism 来学习最终的 sentence representation。其中, interactive mechanism 主要分为以下两个部分:
做一个 interactive mechanism 来学习最终的 sentence representation。其中, interactive mechanism 主要分为以下两个部分:
-
Pyramid Layers
- 受He, 2016 《ResNet》启发,本文添加 pyramid hidden layers(如图2)。
- pyramid hidden layers 的输入为
 的拼接。
的拼接。 - bottom layer 最宽(金字塔底层,神经元多),随着层数增加每层的隐藏神经元越来越少(金字塔从底向顶)。
- 金字塔 第 l 层的 sentence vector
 根据如下公式计算:
根据如下公式计算:
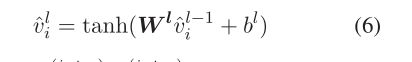
- 其中,金字塔的输入为上两个 block 的输出的拼接,并且添加一层使得sentence vector维度减半。

-
Adaptive Layer-Fusion
adaptive fusion mechanism 被提出用来融合 金字塔 不同层的 abstractive features ,用来计算句子顶点 s i s_i si 最终的 sentence representation r i r_i ri。 r i ∈ R d r_i \in R^d ri∈Rd,计算公式如下:

其中, ∏ \prod ∏ 表示将多个向量拼接(concatenation)在一起。 L L L 表示金字塔的层数,根据 dev set 确定最优为 4。 α i \alpha_i αi 为 金字塔层 每层的正则化权重,其在 train 的过程中被学得。

3.6 Softmax Decoding Block
获得 sentence s i s_i si 的 final sentence vector r i r_i ri之后,将其喂入一个 Softmax 层作分类预测。
3.7 Model Training
4 Experimentation
4.1 Experimental Settings
4.1.1 Dataset
![]()
-
每个数据集平均由大约442个文档(document)组成,一个文档平均包含4.9个句子。
Restaurant 15 及其简介
- SemEval-2015任务12的数据集 Restaurant 15 它包括 254 个英文评论(review document,即 document)文件(共 1315 个 sentences)
-
从 train set 中划分 10% 作为 dev set 来调参。
数据集获取地址 : metashare 官网 (搜索 ABSA,即可找到)
4.1.2 Implementation Details
1. BERT
- Adam optimizer
- β 1 = 0.9 \beta_1 = 0.9 β1=0.9
- initial learning rate is1e−4
- Other parameters of BERT 不变
2. CoGAN:
- Adam optimizer
- learning rate 10−3
- β1= 0.95
- cross-entropy training
- regularization weight of parameters is 10−5
- dropout rate is 0.25
- 所有的 matrix 和 vectors 初始化: Glorot uniform
4.2 Experimental Results

消融试验


分别说明了,CoGAN 模型中 加入 两种情感偏好、以及 交互机制 的有效性。
5 Analysis and Discussion
5.1 Case Study

5.2 Effectiveness Study (还要再看看,没看懂那个比率啥意思)
- 为了更好地说明本文建模的方面内一致性(intra-aspect consistency)和方面间趋势(inter-aspect tendency)信息的有效性,我们分别系统地研究了所有四个 datasets 中的两种情感偏好。
- 具体做法为,我们在每个数据集中采样(sampling)200个句子对(sentence pairs),并计算该句子对中两个句子在其对应方面具有相同情感的比率。 -> 啥玩意比率,没看懂。。。
Sentences are repeated in a document according to the
unrolled aspects. For instance, a sentence with two aspects
will be repeated twice, each sentence with only one aspect
句子根据展开的方面在文档中重复。例如,一个有两个方面的句子将被重复两次,每个句子只有一个方面。
- 本文采用以下三种采样策略(sampling strategies):
- Randomly Sampling : 在每个dataset中随机挑选 sentence pairs
- Inter-Aspect Tendency Sampling : 在两个sentence都位于同一个document中的前提下,随机挑选 sentence pairs
句子在同一document
- Intra-Aspect Consistency Sampling: 在两个sentence都位于同一个document中 并且 这两个sentence具有相同的 aspect 的前提下,随机挑选 sentence pairs
句子在同一document + sentence具有相同aspect

5.3 Error Analysis
本文随机挑选了 100 个被错误分类的案例,并将错误原因大致分为以下五类:
-
29% 的错误由于否定词
e.g., “Nothing really came across as outstanding.”.
上周看的论文里面好像可以使用 卷积 操作提取局部信息,是否可以考虑借其改善这个问题。
-
27%是由于错误地识别中性(neural)实例.
-
24%是由于含蓄的情感表达
e.g., “There is definitely more to say…”.
-
12%是由于句子太短(例如少于5个单词)
这启发我们结合外部概念网知识库( ConceptNet knowledgebase)来增强语义表示
-
8% are due to comparative opinions,
e.g., “I’ve had better frozen pizza”
这启发我们去研究整合句法信息是否能解决这个问题
6 Conclusion
- 本文提出了一种合作图注意力网络(CoGan)用来进行 ASC。
- 该方法的主要思想是融合考虑 文档(document)中的 两种情感偏好信息(即方面内一致性(intra-aspect consistency)和方面间倾向性(inter-aspect tendency)),以弥补 ASC 中的信息缺失问题。
- 在SemEval-2015和2016的四个数据集上的实验结果表明,本文的方法明显优于许多基线,包括SemEval-2015和2016的共享任务中所有三个表现最佳的系统。
- 未来工作:
- 在我们未来的工作中,我们希望通过使用未标记的数据来提高ASC任务的性能,因为我们基于图的神经网络方法(GAT)易于添加未标记的数据。
- 此外,我们希望将我们的方法应用于其他情感分析任务,例如,基于方面的意见总结 和 多标签情感检测。