目标检测 | RetinaNet:Focal Loss for Dense Object Detection
论文分析了one-stage网络训练存在的类别不平衡问题,提出能根据loss大小自动调节权重的focal loss,使得模型的训练更专注于困难样本。同时,基于FPN设计了RetinaNet,在精度和速度上都有不俗的表现
论文:Focal Loss for Dense Object Detection

- 论文地址:https://arxiv.org/abs/1708.02002
- 论文代码:https://github.com/facebookresearch/Detectron
Introduction
目前state-of-the-art的目标检测算法大都是two-stage、proposal-driven的网络,如R-CNN架构。而one-stage检测器一直以速度为特色,在精度上始终不及two-stage检测器。因此,论文希望研究出一个精度能与two-stage检测器媲美的one-stage检测器
通过分析,论文认为阻碍one-stage精度主要障碍是类别不平衡问题(class imbalance):
- 在R-CNN架构检测器中,通过two-stage级联和抽样探索法(sampling heuristics)来解决类别不平衡问题。proposal阶段能迅速地将bndbox的数量缩小到很小的范围(1-2k),过滤了大部分背景。而第二阶段,则通过抽样探索法来保持正负样本的平衡,如固定的正负样本比例(1:3)和OHEM
- one-stage检测器通常需要处理大量的bndbox(~100k),密集地覆盖着各位置、尺度和长宽比。然而大部分bndbox都是不含目标的,即easy background。尽管可以使用类似的抽样探索法(如hard example mining)来补救,但这样的效率不高,因为训练过程仍然被简单的背景样本主导,导致模型更多地学习了背景而没有很好地学习检测的目标
在解决以上问题的同时,论文产出了两个成果:
- 新的损失函数focal loss,该函数能够动态地调整交叉熵大小。当类别的置信度越大,权重就逐渐减少,最后变为0。反之,置信度低的类别则得到大的权重
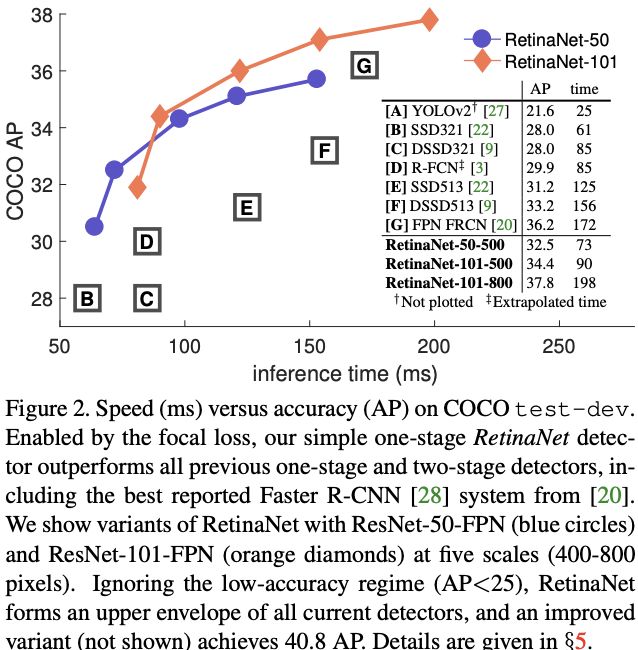
- 设计了一个简单的one-stage检测器RetinaNet来演示focal loss的有效性。该网络包含高效的特征金字塔和特别的anchor设定,结合一些多种近期的one-stage detectgor的trick(DNN/FPN/YOLO/SSD),达到39.1的AP精度和5fps的速度,超越了所有的单模型,如图2所示
FocalLoss
Balanced Cross Entropy
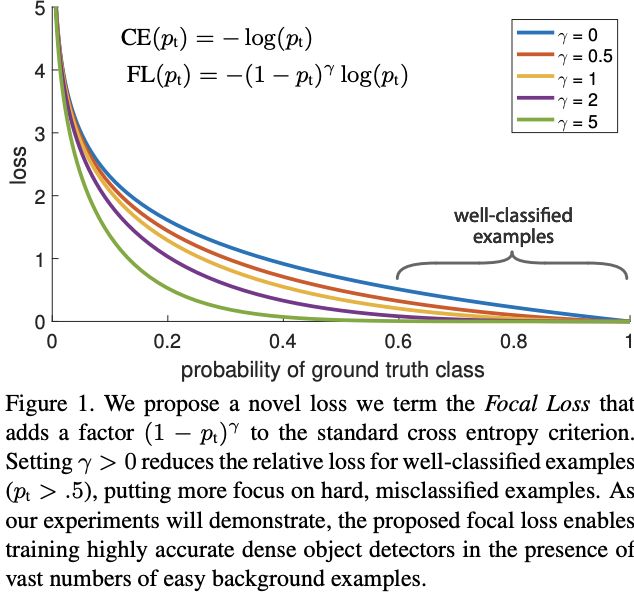
交叉熵损失函数如图1最上曲线,当置信度大于0.5时,loss的值也不小。若存在很多简单样本时,这些不小的loss堆积起来会对少样本的类别训练造成影响

一种简单的做法是赋予不同的类不同的权重 α \alpha α,即 α \alpha α-balanced 交叉熵。在实际操作中, α \alpha α属于一个预设的超参,类别的样本数越多, α \alpha α则设置越小
Focal Loss Definition
α \alpha α-balanced 交叉熵仅根据正负样本的数量进行权重的平衡,没有考虑样本的难易程度。因此,focal loss降低了容易样本的损失,从而让模型更专注于难的负样本

focal loss在交叉熵的基础上添加了调节因子 ( 1 − p t ) γ (1-p_t)^{\gamma} (1−pt)γ,其中 γ ≥ 0 \gamma\ge0 γ≥0是超参数。 γ ∈ [ 0 , 5 ] \gamma\in[0,5] γ∈[0,5]的loss曲线如图1所示,focal loss有两个特性:
- 当一个样本被误分且置信度很低时,调节因子会接近1,整体的loss都很小。当置信度接近1的时候,调节因子会接近于0,整体的loss也被降权了
- 超参数 γ \gamma γ平滑地调整了简单样本的降权比例。当 γ = 0 \gamma=0 γ=0,Focal loss与交叉熵一致,随着 γ \gamma γ增加,调节因子的影响也相应增加。当 γ = 2 \gamma=2 γ=2时,置信度为0.9的样本的loss将有100倍下降,而0.968的则有1000倍下降,这变相地增加了误分样本的权重
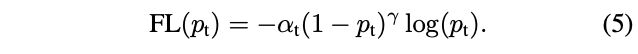
实际使用时中,focal loss会添加 α \alpha α-balanced,这是从后面的实验中总结出来的
Class Imbalance and Model Initialization
二分类模型初始化时对于正负样本预测是均等的,而在训练时,样本数多的类别会主导网络的学习,导致训练初期不稳定。为了解决这问题,论文在模型初始化的时候设置先验值 π \pi π(如0.01),使模型初始输出 π \pi π偏向于低置信度来加大少数(正)样本的学习。在样本不平衡情况下,这种方法对于提高focal loss和 cross entropy训练稳定性有很大帮助
RetinaNet Detector
Architecture

RetinaNet是one-stage架构,由主干网络和两个task-specific子网组成。主干网络用于提取特征,第一个子网用于类别分类,第二个子网用于bndbox回归
- Feature Pyramid Network Backbone
RetinaNet采用FPN作为主干,FPN通过自上而下的路径以及横行连接来增强卷积网络的特征提取能力,能够从一张图片中构造出丰富的以及多尺度特征金字塔,结构如图3(a)-(b)。
FPN构建在ResNet架构上,分别在level p 3 p_3 p3- p 7 p_7 p7,每个level l意味着 2 l 2^l 2l的尺度缩放,且每个level包含256通道
- Anchors
level p 3 p_3 p3到 p 7 p_7 p7对应的anchor尺寸为 3 2 2 32^2 322到 51 2 2 512^2 5122,每个金字塔层级的的长宽比均为 { 1 : 2 , 1 : 1 , 2 : 1 } \{1:2, 1:1, 2:1 \} {1:2,1:1,2:1},为了能够预测出更密集的目标,每个长宽比的anchor添加原设定尺寸的 { 2 0 , 2 1 / 3 , 2 2 / 3 } \{2^0, 2^{1/3}, 2^{2/3} \} {20,21/3,22/3}大小的尺寸,每个level总共有9个anchor
每个anchor赋予长度为K的one-hot向量和长度为4的向量,K为类别数,4为box的坐标,与RPN类似。IoU大于0.5的anchor视为正样本,设定其one-host向量的对应值为1, [ 0 , 0.4 ) [0, 0.4) [0,0.4)的anchor视为背景, [ 0.4 , 0.5 ) [0.4, 0.5) [0.4,0.5)的anchor不参与训练
- Classification Subnet
分类子网是一个FCN连接FPN的每一level,分类子网是权值共享的,即共用一个FPN。子网由4xCx(3x3卷积+ReLU激活层)+KxA(3x3卷积)构成,如图3©,C=256,A=9
- Box Regression Subnet
定位子网结构与分类子网类似,只是将最后的卷积大小改为4xAx3x3,如图3(d所示)。每个anchor学习4个参数,代表当前bndbox与GT间的偏移量,这个与R-CNN类似。这里的定位子网是类不可知的(class-agnostic),这样能大幅减少参数量
Inference and Training
- Inference
由于RetinaNet结构简单,在推理的时候只需要直接前向推算即可以得到结果。为了加速预测,每一个FPN level只取置信度top-1k bndbox( ≥ 0.05 \ge0.05 ≥0.05),之后再对所有的结果进行NMS( ≥ 0.5 \ge0.5 ≥0.5)
- Focal Loss
训练时,focal loss直接应用到所有~100k anchor中,最后将所有的loss相加再除以正样本的数量。这里不除以achor数,是由于大部分的bndbox都是easy样本,在focal loss下仅会产生很少loss。权值 α \alpha α的设定与 λ \lambda λ存在一定的关系,当 λ \lambda λ增加时, α \alpha α则需要减少,( α = 0.25 , λ = 2 \alpha=0.25, \lambda=2 α=0.25,λ=2表现最好)
- Initialization
Backbone是在ImageNet 1k上预训练的模型,FPN的新层则是根据论文进行初始化,其余的新的卷积层(除了最后一层)则偏置 b = 0 b=0 b=0,权重为 σ = 0.01 \sigma=0.01 σ=0.01的高斯分布
π = 1 1 + e − b \pi=\frac{1}{1+e^{-b}} π=1+e−b1
最后一层卷积的权重为 σ = 0.01 \sigma=0.01 σ=0.01的高斯分布,偏置 b = − l o g ( 1 − π ) / π b=-log(1-\pi)/\pi b=−log(1−π)/π(偏置值的计算是配合最后的激活函数来推),使得训练初期的前景置信度输出为 π = 0.01 \pi=0.01 π=0.01,即认为大概率都是背景。这样背景就会输出很小的loss,前景会输出很大的loss,从而阻止背景在训练前期产生巨大的干扰loss
- Optimization
RetinaNet使用SGD作为优化算法,8卡,每卡batchSize=2。learning rate=0.01,60k和80k轮下降10倍,共进行90k迭代,Weight decay=0.0001,momentum=0.9,
training loss为focal loss与bndbox的smooth L1 loss
Experiments

Training Dense Detection
- Network Initialization
论文首先尝试直接用标准交叉熵进行RetinaNet的训练,不添加任何修改和特殊初始化,结果在训练时模型不收敛。接着论文使用先验概率 π = 0.01 \pi=0.01 π=0.01对模型进行初始化,模型开始正常训练,并且最终达到30.2AP,训练对 π \pi π的值不敏感
- Balanced Cross Entropy
接着论文进行平衡交叉熵的实验,结果如Table1a,当 α = 0.75 \alpha=0.75 α=0.75时,模型获得0.9的AP收益
- Focal Loss
接着论文进行了focal loss实验,结果如Table 1b,当 γ = 2 \gamma=2 γ=2时,模型在 α \alpha α-balanced交叉熵上获得2.9AP收益
论文观察到, γ \gamma γ与 α \alpha α成反向关。整体而言, γ \gamma γ带来的收益更大,此外, α \alpha α的值一般为 [ 0.25 , 0.75 ] [0.25, 0.75] [0.25,0.75](从 α ∈ [ 0.01 , 0.999 ] \alpha\in[0.01, 0.999] α∈[0.01,0.999]中实验得出)
- Analysis of the Focal Loss
为了进一步了解focal loss,论文分析了一个收敛模型( γ = 2 \gamma=2 γ=2,ResNet-101)的loss经验分布。首先在测试集的预测结果中随机取 1 0 5 ~10^5 105个正样本和 1 0 7 ~10^7 107个负样本,计算其FL值,再对其进行归一化令他们的和为1,最后根据归一化后的loss进行排序,画出正负样本的累积分布函数(CDF),如图4

不同的 γ \gamma γ值下,正样本的CDF曲线大致相同,大约20%的难样本占据了大概一半的loss,随着 γ \gamma γ的增大,更多的loss集中中在top20%中,但变化比较小
不同的 γ \gamma γ值下,负样本的CDF曲线截然不同。当 γ = 0 \gamma=0 γ=0时,正负样本的CDF曲线大致相同。当 γ \gamma γ增大时,更大的loss集中在难样本中。当 γ = 2 \gamma=2 γ=2时,很大一部分的loss集中在很小比例的负样本中。可以看出,focal loss可以很有效的减少容易样本的影响,让模型更专注于难样本
- Online Hard Example Mining (OHEM)
OHEM用于优化two-stage检测器的训练,首先根据loss对样本进行NMS,再挑选hightest-loss样本组成minibatches,其中NMS的阈值和batch size都是可调的。与FL不同,OHEM直接去除了简单样本,论文也对比了OHEM的变种,在NMS后,构建minibatch时保持1:3的正负样本比。实验结果如Table 1d,无论是原始的OHEM还是变种的OHEM,实验结果都没有FL的性能好,大约有3.2的AP差异。因此,FL更适用于dense detector的训练
Model Architecture Design
- Anchor Density
one-stage检测器使用固定的网格进行预测,一个提高预测性能的方法是使用多尺度/多长宽比的anchro进行。实验结果如Table 1c,单anchor能达到30.3AP,而使用9 anchors能收获4AP的性能提升。最后,当增加到9anchors时,性能法儿下降了,这说明,当anchor密度已经饱和了
- Speed versus Accuracy
更大Backbone和input size意味着更高准确率和更慢的推理速度,Table 1e展示了这两者的影响,图2展示了RetinaNet与其它主流检测器的性能和速度对比。大尺寸的RetinaNet比大部分的two-stage性能要好,而且速度也更快
- Comparison to State of the Art

与当前的主流one-stage算法对比,RetinaNet大概有5.9的AP提升,而与当前经典的two-stage算法对比,大约有2.3的AP提升,而使用ResNeXt32x8d-101-FPN作为backbone则能进一步提升1.7AP
Conclusion
论文认为类别不平衡问题是阻碍one-stage检测器性能提升的主要问题,为了解决这个问题,提出了focal loss,在交叉熵的基础上添加了调节因子,让模型更集中于难样本的训练。另外,论文设计了one-stage检测器RetinaNet并给出了相当充足的实验结果
创作不易,未经允许不得转载~
更多内容请关注个人微信公众号【晓飞的算法工程笔记】
