CycleGAN及非监督条件图像生成技术简介
**CycleGAN及非监督条件图像生成技术简介**
- 图像风格迁移技术
-
- 逐层图像特征提取
- 保证内容一致性
- 保证风格一致性
- 惩罚因子
- 非监督条件图像生成
- CycleGAN框架理解
- StarGAN框架理解
-
- StarGAN应用实例
- 公共映射空间
-
- 映射训练
-
- 共享编码器与解码器
- 加入领域判别器
- ComboGAN
- XGAN
- 非监督条件图像生成技术
- 复现CycleGAN论文
-
- 人脸——动漫脸转换
-
- 代码编写
- 二次元发色转换
- 总结
- 参考文献
图像风格迁移技术
图像风格迁移:输入正常图像,输出风格化后的图像。
原始图像作为输入到深度学习模型生成期望的风格图像,在深度学习模型中已经学习了期望风格的特征等。
对于生成图像需要思考两个问题:
1.如何保证生成图像内容与原图一致?
2.如何保证生成图像风格与目标图一致?
逐层图像特征提取

保证内容一致性
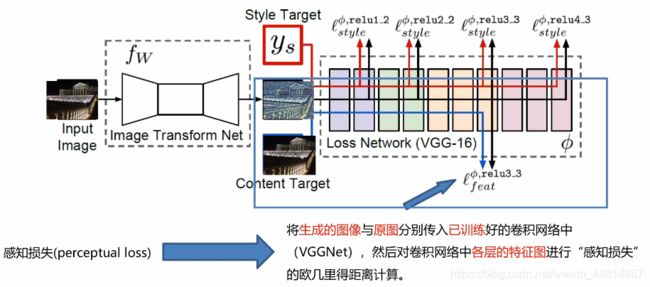
将原图传入一个没有训练的神经网络之中,生成出一张带有原图内同的图像,那么如何保证内容的一致性呢?于是将生成的图片放入已经训练好的神经网络中进行传播,再将原始的图像放入神经网络中,对每一层都进行一个比较损失(感知损失)按照相关公式进行距离计算。
保证风格一致性
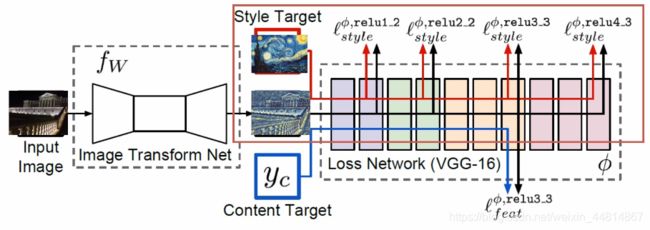
风格损失一致性:
将生成的图像与目标风格图分别传入已训练号的卷积网络中,然后对卷积网络中各层的特征图进行“风格损失”的欧几里得距离计算。
惩罚因子
总的损失函数如下:

如何调整图像画风?

目标:最小化总损失函数
非监督条件图像生成
方法一:直接转换

对于生成器生成Y领域的图片,然后将真实的Y领域的图片跟伪造的图片送入判别器去判别生成图片是不是Y领域的真实图片。
存在的问题:
Y领域例如梵高的画作本身就很稀少,训练它的话,判别器很好的去识别,但是对于生成器直接可能就记住了特征,因此可以顺利的欺骗过判别器,这样生成器就几乎没有任何学习。
解决办法
循环一致性:

上述生成器生成X-Y领域的图片后,然后再将Y领域的图片经过生成器重构到X领域的图片,这部分就是我们可作是我们所熟知的自动编码器。则这样就可以保证生成器记住的不只是梵高的画作,而是要生成出根据输入生成相应的图像。因此相应的提出了Cycle网络。
方法二:先映射到公共空间

这种的方法内容风格变化大,但是语义特征保留。
CycleGAN框架理解
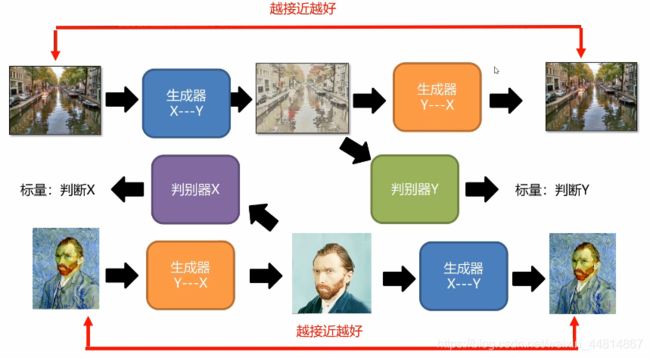
对于这样一个循环结构,上面的循环是两个生成器生成的图片尽可能越接近越好,另外一个循环就是对于梵高画作,使用一个生成器生成一个普通的真实的图片,然后再由一个生成器生成回Y的这样一个过程,两者也是越接近越好,同样也可以将其送给判别器去判别是否像真实的x或者y,综上,此网络结构就是两组对抗网络组合在一起的网络结构。
StarGAN框架理解
多个领域互转:

StarGAN完成的任务就是对于不同领域互转,使用一个生成器去完成n个领域完成的任务。
网络结构:

判别器多了一项任务就是除了判别数据是否真实之外,还在判断数据属于哪一个领域(分类任务)。生成器的输入也分为两部分,输入数据和生成目标域的编码,两者合在一起送给生成器生成伪造的数据,然后放入生成器种进行重构,然后与原数据进行比对,越接近你越好。
StarGAN应用实例
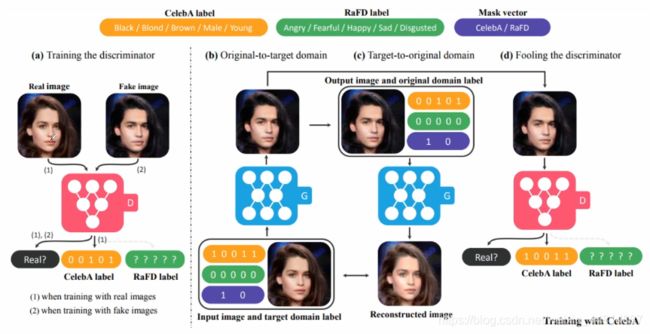
上图对具体的标签进行编码从而生成不不同风格的图片,下图以表情标签进行编码进行学习从而可生成不同的表情的人脸。

公共映射空间
对于第二种方法我们提出公共映射空间这个概念

将数据映射到公共空间然后再解码到另外一个域的图像,核心就是去除图像内容风格,但是语义特征保留
语义特征:深度学习网络的后几层,为更抽象高级的特征
映射训练
那么如何进行训练呢?
训练自动编码器:

对于输入的人脸通过编码器映射到脸部特征这样一个公共映射空间,然后通过解码器重构成一个真实的图片,然后最小化重构损失进行一个反向传播进而训练编码器和解码器,对于输入的二次元图像同理。
训练判别器:

判别器去帮助解码器构造出更真实的图像,所以需要两个判别器分别去判断重构的图像是否真实。
但是存在一个问题就是:
图片相同的特征可能没有映射到隐空间的同一位置
举例说明:
“1010"在X种表示"黑眼睛”,但是"1010"“红头发”
因此解决上述问题提出一个叫共享编码器与解码器
共享编码器与解码器
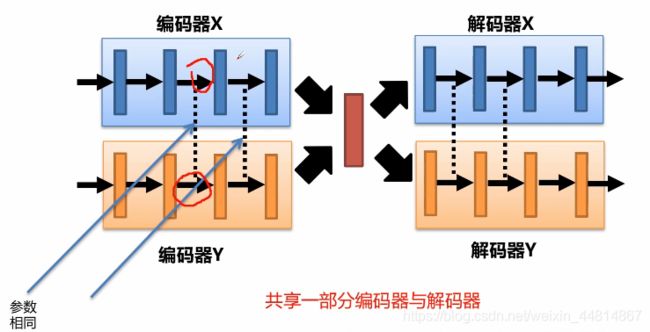
对于编码和解码对应的两个神经网络,所谓共享就是强制几组参数相同或接近。
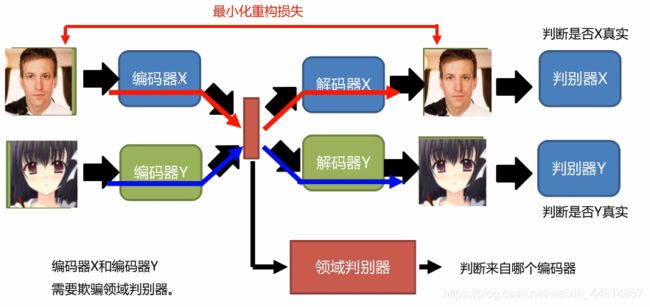
加入领域判别器
我们可以在隐变量层接入一个领域判别器,它是用来判断数据来自哪个编码器,当然这个网络也是一个对抗网络,编码器X和编码器Y需要欺骗领域判别器。对抗的结果就是编码器X与编码器Y输出相同的分布,即:同样的编码表示同样的特征.
具体图解表示方法如下:
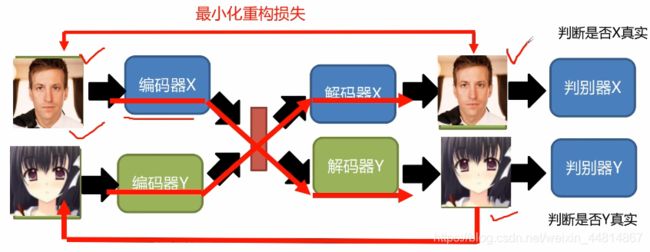
ComboGAN
ComboGAN:核心就是加入循环一致性
XGAN
XGAN:加入语义一致性
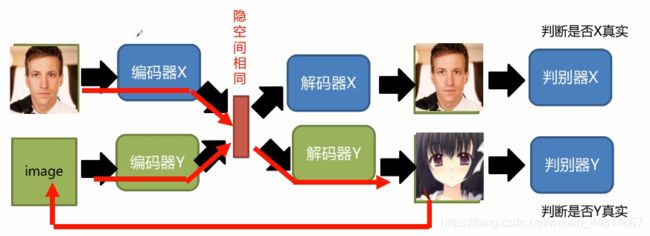
对于输入图像经过编码器X生成出一组空间(向量)经过解码器Y然后返回编码器Y中进行一个生成,此时不再需要经过解码器X了,只需要生成另外一组的向量,这与前面的向量应该尽可能的相似。
非监督条件图像生成技术
1.融合自动编码器和对坑网络
2.使用训练后的网络中间层度量内容一致性与纹理一致性
3.循环一致性:a生成b,b重构a‘,a’生成b‘,b’重构a‘
4.语义一般指的是深度学习的最后几层的一些特征
复现CycleGAN论文
人脸——动漫脸转换
代码编写
初始化CycleGAN对象
// An highlighted block
def __init__(self, img_h=64, img_w=64, lr=0.0004):
"""
初始化CycleGAN对象
:param img_h: 图像高度
:param img_w: 图像宽度
:param lr: 学习率
"""
self.img_h = img_h
self.img_w = img_w
self.lr = lr
self.d_dim = 1
self.isTrain = tf.placeholder(dtype=tf.bool)
self.img_c = 3
# A--->B--->A'
self.input_A = tf.placeholder(dtype=tf.float32, shape=[None, self.img_w, self.img_h, self.img_c])
self.fake_B = self._init_generator(input=self.input_A, scope_name="generatorA2B", isTrain=self.isTrain)
self.fake_rec_A = self._init_generator(input=self.fake_B, scope_name="generatorB2A", isTrain=self.isTrain)
# B--->A---->B'
self.input_B = tf.placeholder(dtype=tf.float32, shape=[None, self.img_w, self.img_h, self.img_c])
self.fake_A = self._init_generator(input=self.input_B, scope_name="generatorB2A", isTrain=self.isTrain,
reuse=True)
self.fake_rec_B = self._init_generator(input=self.fake_A, scope_name="generatorA2B", isTrain=self.isTrain,
reuse=True)
# 判断真假A
self.dis_fake_A = self._init_discriminator(input=self.fake_A, scope_name="discriminatorA", isTrain=self.isTrain)
self.dis_real_A = self._init_discriminator(input=self.input_A, scope_name="discriminatorA",
isTrain=self.isTrain, reuse=True)
# 判断真假B
self.dis_fake_B = self._init_discriminator(input=self.fake_B, scope_name="discriminatorB", isTrain=self.isTrain)
self.dis_real_B = self._init_discriminator(input=self.input_B, scope_name="discriminatorB",
isTrain=self.isTrain, reuse=True)
# 初始化伪造数据A,B判断
self.input_fake_A = tf.placeholder(dtype=tf.float32, shape=[None, self.img_w, self.img_h, self.img_c],
name="fake_A_data")
self.input_fake_B = tf.placeholder(dtype=tf.float32, shape=[None, self.img_w, self.img_h, self.img_c],
name="fake_B_data")
self.dis_fake_A_input = self._init_discriminator(self.input_fake_A, scope_name="discriminatorA",
isTrain=self.isTrain, reuse=True)
self.dis_fake_B_input = self._init_discriminator(self.input_fake_B, scope_name="discriminatorB",
isTrain=self.isTrain, reuse=True)
self._init_train_methods()
初始化判别器
// An highlighted block
def _init_discriminator(self, input, scope_name="discriminator", isTrain=True, reuse=False):
"""
初始化判别器op
:param input: 输入数据op
:param scope_name: 判别器变量命名空间
:param isTrain: 是否处于训练状态
:param reuse: 是否复用内部参数
:return: 判断结果
"""
with tf.variable_scope(scope_name,reuse=reuse):
# input [none,64,64,3]
conv1 = tf.layers.conv2d(input,32,[4,4],strides=(2,2),padding="same") #[none,32,32,32]
bn1 = tf.layers.batch_normalization(conv1,training=isTrain)
active1 = tf.nn.leaky_relu(bn1) #[none,32,32,32]
#layer 2
conv2 = tf.layers.conv2d(active1,64,[4,4],strides=(2,2),padding="same") #[none,16,16,64]
bn2 = tf.layers.batch_normalization(conv2,training=isTrain)
active2 = tf.nn.leaky_relu(bn2) #[none,16,16,64]
# layer 3
conv3 = tf.layers.conv2d(active2,128,[4,4],strides=(2,2),padding='same') #[none,8,8,128]
bn3 = tf.layers.batch_normalization(conv3,training=isTrain)
active3 = tf.nn.leaky_relu(bn3) #[none,8,8,128]
#layer 4
conv4 = tf.layers.conv2d(active3,256,[4,4],strides=(2,2),padding="same") #[none,4,4,256]
bn4 = tf.layers.batch_normalization(conv4,training=isTrain)
active4 = tf.nn.leaky_relu(bn4) #[none,4,4,256]
# out layer
out_logis = tf.layers.conv2d(active4,1,[4,4],strides=(1,1),padding="valid") #[none,1,1,1]
return out_logis
初始化生成器
// An highlighted block
def _init_generator(self, input, scope_name='generator', isTrain=True, reuse=False):
"""
初始化生成器op
:param input: 输入数据op
:param scope_name: 生成器变量命名空间
:param isTrain: 是否处于训练状态
:param reuse: 是否复用内部参数
:return: 生成数据op
"""
with tf.variable_scope(scope_name,reuse=reuse):
#input[none,64,64,3]
conv1 = tf.layers.conv2d(input,64,[4,4],strides=(2,2),padding="same")# [none,32,32,64]
bn1 = tf.layers.batch_normalization(conv1,training=isTrain)
active1 = tf.nn.leaky_relu(bn1) #[none,32,32,64]
#layer 2
conv2 = tf.layers.conv2d(active1,128,[4,4],strides=(2,2),padding="same") #[none,16,16,128]
bn2 = tf.layers.batch_normalization(conv2,training=isTrain)
active2 = tf.nn.leaky_relu(bn2) #[none,16,15,128]
# layer3
conv3 = tf.layers.conv2d(active2,256,[4,4],strides=(2,2),padding="same") #[none,8,8,256]
bn3 = tf.layers.batch_normalization(conv3,training=isTrain)
active3 = tf.nn.leaky_relu(bn3) #[none,8,8,256]
# deconv layer 1
de_conv1 = tf.layers.conv2d_transpose(active3,128,[4,4],strides=(2,2),padding="same") #[none,16,16,128]
de_bn1=tf.layers.batch_normalization(de_conv1,training=isTrain)
de_active1 = tf.nn.leaky_relu(de_bn1) #[none,16,16,128]
# deconv layer 2
de_conv2 = tf.layers.conv2d_transpose(de_active1,64,[4,4],strides=(2,2),padding="same") #[none,32,32,64]
de_bn2 = tf.layers.batch_normalization(de_conv2,training=isTrain)
de_active2 = tf.nn.leaky_relu(de_bn2) #[none,32,32,64]
# deconv layer 3
de_conv3 = tf.layers.conv2d_transpose(de_active2,3,[4,4],strides=(2,2),padding="same") #[none,64,64,3]
out = tf.nn.tanh(de_conv3)
return out;
训练模型
// An highlighted block
def train(self, data_path_A="data/Train_A/", data_path_B="data/faces/", batch_size=64, itrs=100000, save_time=500):
"""
训练模型
:param data_path_A: 数据A路径
:param data_path_B: 数据B路径
:param batch_size: 采样数据量
:param itrs: 迭代训练次数
:param save_time: 保存周期
:return: None
"""
start_time = time.time()
test_A = dh.read_img2numpy(batch_size=18,img_h=64,img_w=64,path=data_path_A)
test_B = dh.read_img2numpy(batch_size=18,img_w=64,img_h=64,path=data_path_B)
for i in range(itrs):
#读取训练图片
batch_A = dh.read_img2numpy(batch_size=batch_size,img_h=64,img_w=64,path=data_path_A)
batch_B = dh.read_img2numpy(batch_size=batch_size,img_w=64,img_h=64,path=data_path_B)
batch_fake_A,batch_fake_B,g_loss_curr,_=self.sess.run([self.fake_A,self.fake_B,self.g_loss,self.G_trainer],feed_dict={
self.input_A:batch_A,self.input_B:batch_B,self.isTrain:True
})
#训练判别器
d_loss_curr,_ = self.sess.run([self.d_loss,self.D_trainer],
feed_dict={self.input_A:batch_A,self.input_B:batch_B,self.input_fake_A:batch_fake_A,
self.input_fake_B:batch_fake_B,self.isTrain:True})
if i %save_time ==0:
#生成数据
self.gen_data(data=test_A,a2b=True,save_path="out/CycleGAN/A2B/",name=str(i).zfill(6)+".png")
self.gen_data(data=test_B,a2b=False,save_path="out/CycleGAN/B2A/",name=str(i).zfill(6)+".png")
print("i:",i," D_loss",d_loss_curr," G_loss",g_loss_curr)
self.save()
end_time = time.time()
time_loss =end_time-start_time
print("时间消耗:",int(time_loss),"秒")
start_time = time.time()
self.sess.close()
训练
// An highlighted block
if __name__ == '__main__':
gan = CycleGAN()
gan.train(data_path_A="data/train_A/",data_path_B="data/faces/");
二次元发色转换
代码结构及代码编写方式基本上一样,只需更换数据集即可

总结
CycleGAN的核心在于充分理解循环一致性,公共映射空间等方法。
对于GAN的大部分变形及应用已经介绍完毕,具体的联系如下:
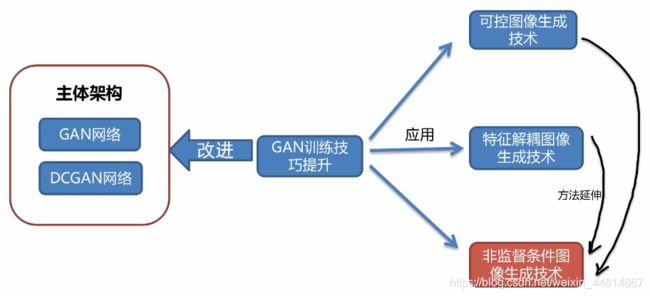
针对于不同的需求可选择不同的GAN的类型进行仿真应用
参考文献
[1] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley,
S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in Neural Information Processing Systems (NIPS), pp. 2672–2680,2014.
[2] T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford, X. Chen,
and X. Chen, “Improved techniques for training gans,” in Advances in
Neural Information Processing Systems (NIPS), pp. 2226–2234, 2016.
[3]M. Arjovsky, S. Chintala, and L. Bottou, “Wasserstein gan,”
arXiv:1701.07875, 2017.