YOLOv8来啦!YOLO内卷期模型怎么选?9+款AI硬件如何快速部署?深度解析
在这新春佳节到来之际,回顾整个虎年,堪称YOLO内卷元年,各路YOLO系列神仙打架,各显神通。一开始大部分用户做项目做实验还是使用的YOLOv5,然后YOLOv6、YOLOv7、PP-YOLOE+、DAMO-YOLO、RTMDet就接踵而至,于是就在自己的数据集逐一尝试,好不容易把这些下饺子式的YOLO模型训练完测试完,忙完工作准备回家过年时,YOLOv8又闪电发布,YOLOv6又更新了3.0版本...用户还得跟进继续训练测试,其实很多时候就是重复工作。
此外换模型训练调参也会引入更多的不确定性,而且往往业务数据集大则几十万张图片,重训成本很高,但训完了新的精度不一定更高,速度指标在特定机器环境上也未必可观,参数量、计算量的变化尤其在边缘设备上也不能忽视。
所以在这样的内卷期,作为开发者的我们应该怎么选择一个适合自己的模型呢?
接下来,我们将就YOLOv8的升级点、YOLO系列模型选型指南、YOLO系列模型多硬件快速部署几个方面展开讨论。

YOLO历史回顾
几天前,目标检测经典模型YOLO系列再添一个新成员YOLOv8,这是Ultralytics公司继YOLOv5之后的又一次重大更新。YOLOv8一经发布就受到了业界的广泛关注,成为了这几天业界的流量担当。
首先带大家快速了解下YOLO的发展历史。YOLO(You Only Look Once,你只看一次)是单阶段实时目标检测算法的开山之作,力求做到“又快又准”。
2016年,Joseph Redmon发布了第一版YOLO(代码库叫做darknet),但他本人只更新到YOLOv3,随后就将darknet库交给了Alexey Bochkovskiy、Chien-Yao Wang 等人,即YOLOv4和YOLOv7作者团队负责。
2020年,Ultralytics公司发布了YOLOv5代码库,同年百度发布了PP-YOLO,2021年旷视发布了YOLOX,2022年百度又发布了PP-YOLOE及PP-YOLOE+,随后又有美团、OpenMMLab、阿里达摩院等相继推出了各自的YOLO模型版本,就在前几天Ultralytics公司又发布了YOLOv8。同时这些系列模型也在不断更新迭代。
由此可见YOLO系列模型算法始终保持着极高的迭代更新率,并且每一次更新都会掀起业界的关注热潮。


YOLOv8升级解读
此次Ultralytics从YOLOv5到YOLOv8的升级,主要包括结构算法、命令行界面、Python API等,精度上YOLOv8相比YOLOv5高出一大截,但速度略有下降。
仅看检测方向的话,简单总结下YOLOv8在结构算法上相比YOLOv5的升级:
-
骨干网络部分
选用梯度流更丰富的C2f结构替换了YOLOv5中的C3结构,为了轻量化也缩减了骨干网络中最大stage的blocks数,同时不同缩放因子N/S/M/L/X的模型不再是共用一套模型参数,M/L/X大模型还缩减了最后一个stage的输出通道数,进一步减少参数量和计算量。
-
Neck部分
同样是C2f模块替换C3模块,为了轻量化删除了Neck结构中top-down阶段的两个上采样卷积。
-
Head部分
换成了目前主流的Decoupled-Head解耦头结构,将分类分支和定位分支分离,缓解了分类和回归任务的内在冲突。
-
标签分配和Loss部分
从Anchor-Based换成了Anchor-Free,采用了TAL(Task Alignment Learning)动态匹配,并引入了DFL(Distribution Focal Loss)结合CIoU Loss做回归分支的损失函数,使得分类和回归任务之间具有较高的一致性。
-
训练策略
训练的数据增强部分最后10 epoch关闭Mosaic增强更有利于模型收敛的稳定,同时训练epoch数从300增大到500使得模型训练更充分。
从上面可以看出,YOLOv8集合了之前提出的诸如YOLOX、YOLOv6、YOLOv7和PPYOLOE等算法的相关设计,尤其是Head标签分配和Loss部分以及PP-YOLOE非常相似。YOLOv8集百家所长达到了实时检测界的一个新高度。
就在YOLOv8发布的当晚,飞桨PaddleDetection团队就支持了YOLOv8的推理部署,并正在研发可训练版本中。
-
完整教程文档及模型下载链接
https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.5/docs/feature_models/PaddleYOLO_MODEL.md
-
YOLO系列多硬件部署示例下载链接
https://github.com/PaddlePaddle/FastDeploy/blob/develop/examples/vision/detection/paddledetection

YOLO系列模型选型指南
为了方便统一YOLO系列模型的开发测试基准,以及模型选型,百度飞桨推出了PaddleYOLO开源模型库,支持YOLO系列模型一键快速切换,并提供对应ONNX模型文件,充分满足各类部署需求。
此外YOLOv5、YOLOv6、YOLOv7和YOLOv8在评估和部署过程中使用了不同的后处理配置,因而可能造成评估结果虚高,而这些模型在PaddleYOLO中实现了统一,保证实际部署效果和模型评估指标的一致性,并对这几类模型的代码进行了重构,统一了代码风格,提高了代码易读性。下面的讲解内容也将围绕PaddleYOLO相关测试数据进行分析。
总体来说,选择合适的模型,要明确自己项目的要求和标准,精度和速度一般是最重要的两个指标,但还有模型参数量、FLOPs计算量等也需要考虑。接下来就具体讲一讲这几个关键点。
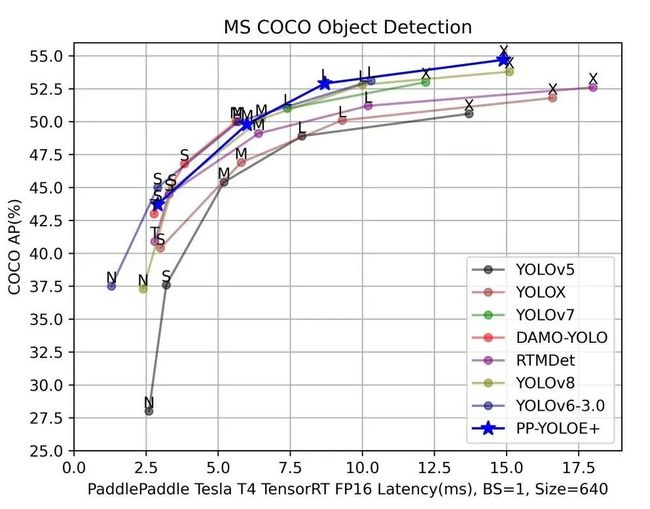

注:以上DAMO-YOLO、YOLOv6-3.0均使用官方数据,其余模型均为Paddle复现版本测试数据。

看精度
首先是精度,从上图YOLO系列Benchmark图可以看出,几乎每个模型的目标都是希望自己的模型折线在坐标轴上是最高的,这也是各个模型的主要竞争点。各家都会训练业界权威的COCO数据集去刷高精度,但是迁移到实际业务数据集上时,效果哪个高并不一定,各个模型的泛化能力并不和COCO数据集上的精度正相关。COCO数据集精度差距在1.0以内的模型,其实业务数据集上差别不会很大,而且实际业务项目一般也不会只看mAP这一个指标,也可能需要关注AP50、AP75、Recall等指标。
要想在业务数据集达到较高精度,最重要是一点其实是加载一个较强的预训练(pre-trained)权重。COCO预训练权重可以极快收敛,精度也会远高于用ImageNet预训练权重训的。一个较强的预训练在下游任务中的效果会优于绝大多数的调参和算法优化。
在2022年9月份,飞桨官方将PP-YOLOE模型升级为PP-YOLOE+,最重要的一点就是提供了Objects365大规模数据集的预训练权重,Objects365数据集含有的数据量可达百万级,在大数据量下的训练可以使模型获得更强大的特征提取能力、更好的泛化能力,在下游任务上的训练可以达到更好的效果。
基于Objects365的PP-YOLOE+预训练模型,将学习率调整为原始的十分之一,在COCO数据集上训练的epoch数从300减少到了只需80,大大缩短了训练时间的同时,获得了精度上的显著提升。实际业务场景中,在遇到比COCO更大规模数据集的情况下,传统的基于COCO预训练的模型就显得杯水车薪了,无论训练200 epoch还是80 epoch,模型收敛都会非常慢,而使用Objects365预训练模型可以在较少的训练轮次epoch数如只30个epoch,就实现快速收敛并且最终精度更高。
此外还有一些自监督或半监督策略可以继续提升检测精度,但是对于开发者来讲,时间资源、硬件资源消耗极大,以及目前的开发体验还不是很友好,需要持续优化。

看速度
速度不像精度很快就能复现证明的,鉴于各大YOLO模型发布的测速环境也不同,还是得统一测试环境进行实测。上图是飞桨团队在飞桨框架对齐各大模型精度的基础上,统一在Tesla T4上开启TensorRT以FP16进行的测试。
另外需要注意的是,各大YOLO模型发布的速度只是纯模型速度,是去除NMS(非极大值抑制)的后处理和图片前处理的,实际应用端到端的耗时还是要加上NMS后处理和图片前处理的时间,以及将数据从CPU拷贝到GPU/XPU等加速卡上和将数据从加速卡拷贝到CPU的时间。通常NMS的参数对速度影响极大,尤其是score threshold(置信度阈值) 、NMS的IoU阈值、top-k框数(参与NMS的最多框数)以及max_dets(每张图保留的最多框数) 等参数。
比如最常用的是调score threshold,一般为了提高 Recall(召回率) 都会设置成0.001、0.01之类的,但其实这种置信度范围的低分框对实际应用来说意义不大;如果设置成0.1、0.2则会提前过滤掉众多的低分框,这样NMS速度和整个端到端部署的速度就会显著上升,代价是掉一些mAP,但对于结果可视化在视觉效果上其实影响很小。
总之实际应用中都需要自己实践,加上NMS等前后处理,不能只看论文中提供的纯模型速度。(具体可见下图"Part4. YOLO系列模型多硬件快速部署”实测数据)
针对YOLO系列模型实际部署过程中遇到的前后处理优化问题、以及不同硬件模型的适配优化加速问题,飞桨团队同样提供了全场景高性能AI部署产品FastDeploy,可以快速在NVIDIA GPU、Intel CPU、ARM CPU、Jetson、昇腾、昆仑芯、算能、瑞芯微等硬件上实现优化部署,这部分将在下一章节具体介绍。
 看参数量、计算量
看参数量、计算量
这方面在学术研究场景中一般不会着重考虑,但是在产业应用场景中就非常重要,需要注意设备的硬件限制。例如堆叠一些模块结构来改造原模型,增加了2~3倍参数量提高了一点点mAP,这是AI竞赛常用的“套路”,精度虽然有少许提升,但速度变慢了很多,参数量和FLOPs也都变大了很多,对于产业应用来说意义不大,又如一些特殊模块,例如ConvNeXt,参数量极大但是FLOPs很小,虽然可以提升精度,但也会降低速度,参数量也可能受设备容量限制。
在对资源、显存及其敏感的场景,除了选择参数量较小的模型,也需要考虑和压缩工具联合使用。如下图所示,在YOLO系列模型上,使用PaddleSlim自动压缩工具(ACT)压缩后,可以在尽量保证精度的同时,降低模型大小和显存占用,并且该能力已经在飞桨全场景高性能AI部署工具FastDeploy中集成,实现一键压缩。

总之,在这YOLO“内卷时期”要保持平常心,无论新出来什么模型,都需要大致了解下改进点和优劣势后再谨慎选择,针对自己的需求选适合自己的模型。
 YOLO系列模型多硬件快速部署
YOLO系列模型多硬件快速部署
STEP3中提到的速度,不仅有AI模型端到端的推理速度,也需要考虑到AI模型快速产业落地的速度。在真实产业部署落地场景,架构各异的AI硬件、不同场景的部署需求、不同操作系统和开发语言,通常使部署落地过程踩坑不断。
基于产业落地部署需求,全场景高性能AI部署工具FastDeploy统一了飞桨的推理引擎和生态推理引擎(包括Paddle Inference、Paddle Lite、TensorRT、OpenVINO、ONNX Runtime等多推理后端),并融合高性能的NLP、CV加速库,实现了AI模型端到端的推理性能优化,并涵盖了包括YOLOv5、YOLOv8、PP-YOLOE等在内的160多个产业级特色模型。YOLO系列在FastDeploy中的部署全景能力如下表展示:
-
各硬件部署示例下载链接
https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/vision/detection/paddledetection

注:*表示:FD目前在该型号硬件上测试。通常同类型硬件上使用的是相同的软件栈,该部署能力可以延伸到同软件架栈的硬件。譬如RK3588与RK3566、RK3568相同的软件栈。
同时,考虑到产业应用实际更关心整体性能,FastDeploy对YOLOv8测试了模型端到端的性能数据。(当然每类硬件都有多款型号,且在具体部署落地中,通常是多batch、动态shape的使用,以下数据仅用于展示端到端推理与AI模型推理的区别。)

注:「FD Runtime」包括模型推理、NMS、HostToDevice(H2D)、DeviceToHost(D2H)5个部分。H2D是将数据从cpu拷贝到GPU/XPU等所需要的时间,发生在将预处理数据喂给推理引擎时,D2H是将数据从GPU/XPU等拷贝到CPU的时间。「端到端推理速度」在FD Runtime的时间上增加的算法前后预处理。
以上就是本次技术解读,最后想给大家留个共同的思考题:在YOLO如此“内卷”的时代,目标检测是否有新的、更高效的模型结构以及开发范式呢?
最后,飞桨团队提前祝大家春节快乐!来年目标检测精度、速度“兔”飞猛进!也欢迎大家Star支持我们的工作!