(Python可视化课程复习)练习1:超市营业额分析(附处理数据)Part1
import pandas as pd
import matplotlib.pyplot as plt首先,引入pandas库,matplotlib库,代码如上
虽然使用Jupyter代码块处理数据很方便,随时用哪些代码,可以直接在代码块之间插入,或者不许要某些部分可以选择不运行,但还是建议把import全放在前面,比较好找到都用了什么。(虽然建议都放在前面,但是不建议都放在同一个代码块中,运行起来有可能非常慢)
那么什么是Pandas呢
Pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
Pandas纳入了大量库和一些标准的数据模型,提供了大量能使我们快速便捷地处理数据的函数和方法。
主要包含两种数据类型:Series和DataFrame
-
Series可以理解为dict的升级版本,主数组存放numpy数据类型,index数据存放索引
-
DataFrame相当于多维的Series,有两个索引数组,分别是行索引和列索引,可以理解成Series组成的字典
那么什么是matplotlib呢
Matplotlib 是 Python 中最受欢迎的数据可视化软件包之一,支持跨平台运行,它是 Python 常用的 2D 绘图库,同时它也提供了一部分 3D 绘图接口。Matplotlib 通常与 NumPy、Pandas 一起使用,是数据分析中不可或缺的重要工具之一。
Matplotlib 是 Python 中类似 MATLAB 的绘图工具,如果您熟悉 MATLAB,那么可以很快的熟悉它。Matplotlib 提供了一套面向对象绘图的 API,它可以轻松地配合 Python GUI 工具包(比如 PyQt,WxPython、Tkinter)在应用程序中嵌入图形。与此同时,它也支持以脚本的形式在 Python、IPython Shell、Jupyter Notebook 以及 Web 应用的服务器中使用。
可以简单理解为,好用的画图工具
Pandas 的set_option 函数
设置输出结果列对齐
# 设置输出结果列对齐
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)这里使用的是Pandas的set_option函数,其中的其他功能如下
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True)#设置列名对齐
pd.set_option('display.unicode.east_asian_width', True)#设置列名对齐
pd.set_option('display.max_rows',None) #显示所有行
pd.set_option('display.max_columns',None)#显示所有列
pd.set_option('expand_frame_repr', False)#设置不换行
pd.set_option('precision',1)#显示小数点后的位数
pd.set_option('display.max_rows',3)#最多显示的行数
pd.set_option('display.max_columns',3)#最多显示的列数
pd.set_option('colwidth',1)#设置列长度
pf = pd.read_excel('0000001.xlsx')
print(pf)最后的pd.read_excel('0000001.xlsx')指的是读取文件名为0000001.xlsx的表格,并赋给pf。
预备工作做好后正式处理数据
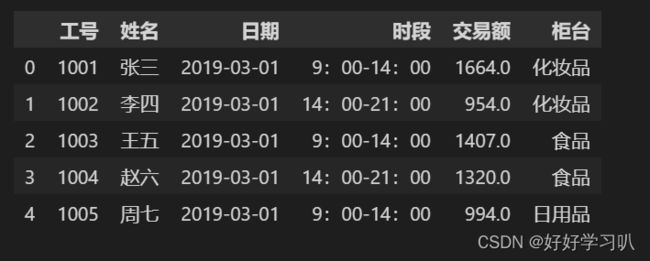
1.读取excle文件中的数据
df = pd.read_excel(r'超市营业额2.xlsx') #读取全部数据,使用默认索引
df.head(5)注:df.head(5)指展示前5行
效果如下:
2.筛选符合特定条件的数据
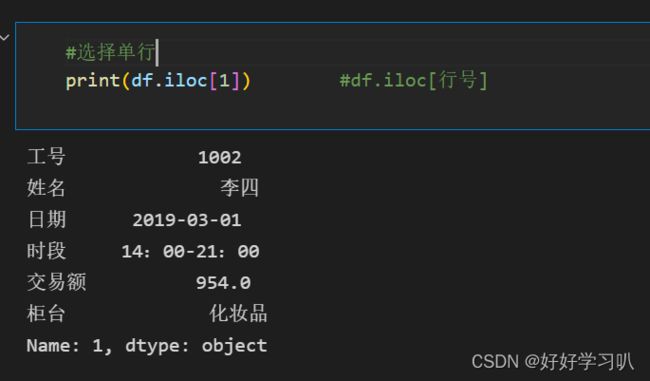
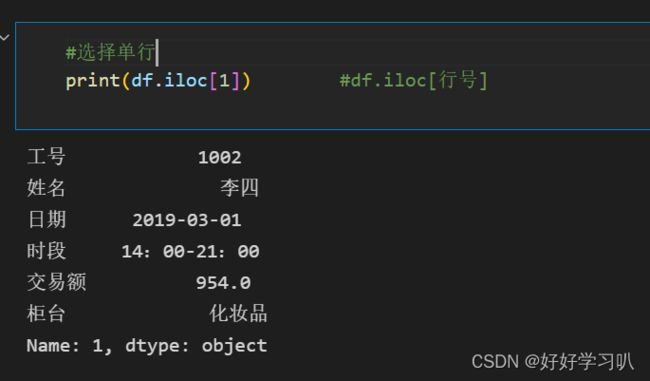
选择某一行
#选择某一行
print(df.iloc[1]) #df.iloc[行号] 效果如下
查询列名
df.columns效果如下

以某列为行索引
df1 = df.set_index('工号')
df1.head(5)效果如下
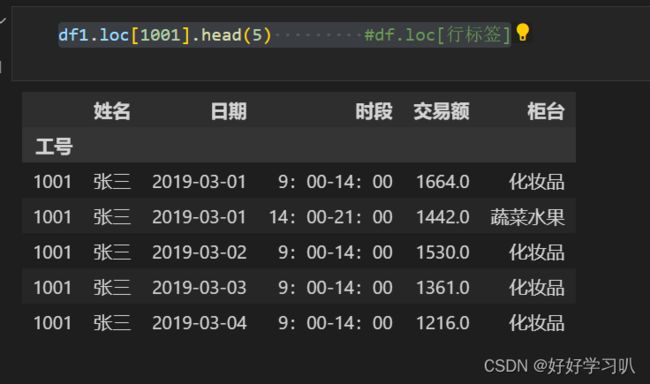
查找某索引下的行
df1.loc[1001].head(5) #df.loc[行标签]查找索引为1001的数据,并展示前5行
效果如下
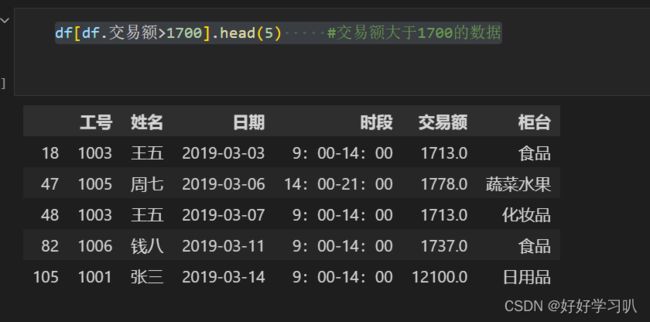
在某范围内,筛选某列值
如,在此例子中,筛选在“交易额”列下,值大于1700的行
df[df.交易额>1700].head(5) #交易额大于1700的数据效果如下
如,在此例子中,按列“时段”中等于9:00-14:00筛选行
df[df.时段=='9:00-14:00'] #上午班交易的数据效果如下

如,选取通知满足“时段”为9:00-14:00,“姓名”为张三的
df[(df.时段=='9:00-14:00') & (df.姓名=='张三')]效果如下
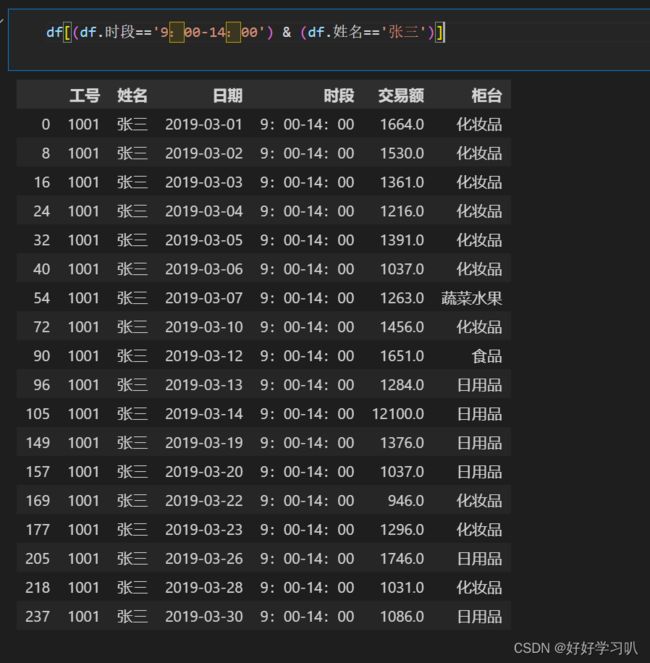
3.查看数据特征和统计信息
查看统计信息
df.交易额.describe() #查看交易额的统计信息效果如下:
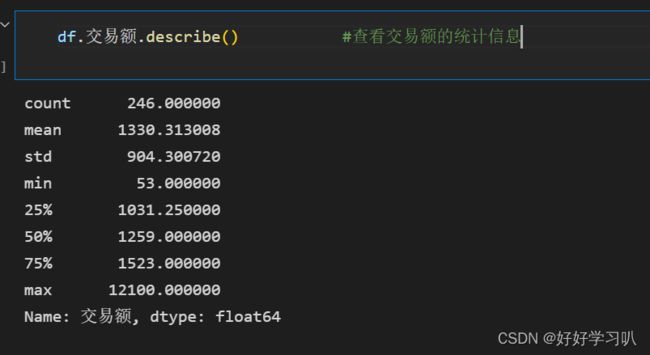
注:count为行数,mean为平均数,std为标准差,min为最小值,25%、50%、75%分别为4等分的三个值,max为最大值
求某列总和
如,求交易额总和
df.交易额.sum()效果如下

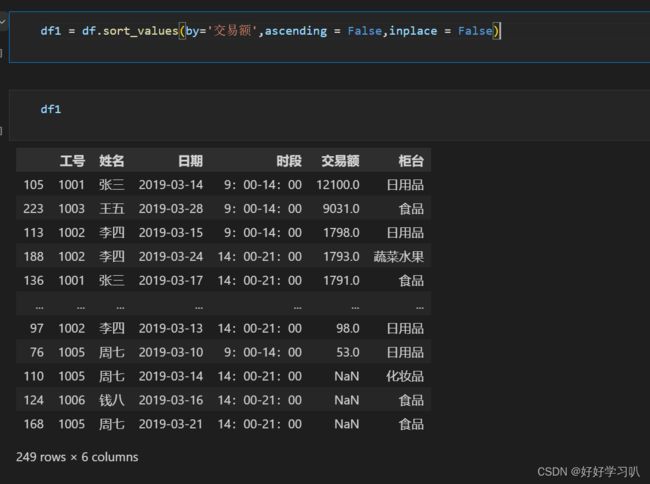
按某列正序或倒序排列
df1 = df.sort_values(by='交易额',ascending = False,inplace = False) 参数说明
by 指定列名(axis=0或’index’)或索引值(axis=1或’columns’)
axis 若axis=0或’index’,则按照指定列中数据大小排序;若axis=1或’columns’,则按照指定索引中数据大小排序,默认axis=0
ascending 是否按指定列的数组升序排列,默认为True,即升序排列
inplace 是否用排序后的数据集替换原来的数据,默认为False,即不替换
na_position {‘first’,‘last’},设定缺失值的显示位置
此例中,按交易额值,正序排列
效果如下