plotnine数据可视化手册
介绍
R语言数据可视化的强大之处在于ggplot2,而plotnine相当于是python版的ggplot2,语法与R语言的ggplot2基本一致,无论是从语法简洁性、作图灵活性、美观度等方面,相对于传统可视化模块,plotnine均有不错的表现。
作为数据分析工作者,出图的速度直接影响数据挖掘的效率,所以撰此文目的在于加强自己对可视化模块plotnine的学习巩固,同时也可以分享给正在学习可视化的同学。
本文持续更新五个系列图表绘制案例及多个实际应用场景:
五个系列图表:趋势型图表、分布型图表、类别比较型图表、数据关系型图表、局部整体型图表
准备
模块安装、导入
pip install plotnine
from plotnine import *汉字乱码问题解决
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False一、趋势型图表系列
场景case:
某互联网公司为了提高裂变类活动的转化率,分别设计并同时上线了两种活动形式(A活动、B活动),通过对比AB两种活动的累计转化率,取较优者决策。
样本示例:
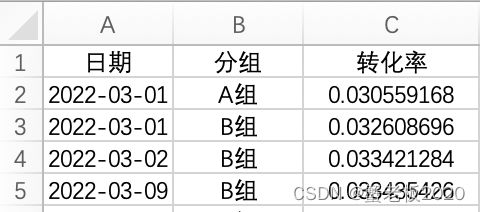
1.1折线图

def plot_a_1(df):
base_plot = (
ggplot(df, aes(x='日期', y='转化率', group='分组', color='分组'))
+geom_line(size=1)
+scale_x_date(name='日期', breaks='2 weeks') #解决x轴标签覆盖问题
+scale_fill_hue(s=0.90, l=0.65, h=0.0417, color_space='husl') #自动配色
#若自定义线条颜色可将上一行代码替换为:
#+scale_color_manual(values=('#084081', '#7bccc4'))
#若在折线图上添加值标签可用下行代码(此图不建议添加值标签,不美观)
#+geom_text(aes(x='日期',y='转化率',label='转化率'),color='black')
+xlab('时间') #重命名x轴名称
+ylab('CVR') #重命名y轴名称
+ggtitle('AB组活动转化率趋势图')
+theme_matplotlib()
)
print(base_plot)
base_plot.save('page/趋势图/图a_1.jpeg', dpi=1000)1.2面积图
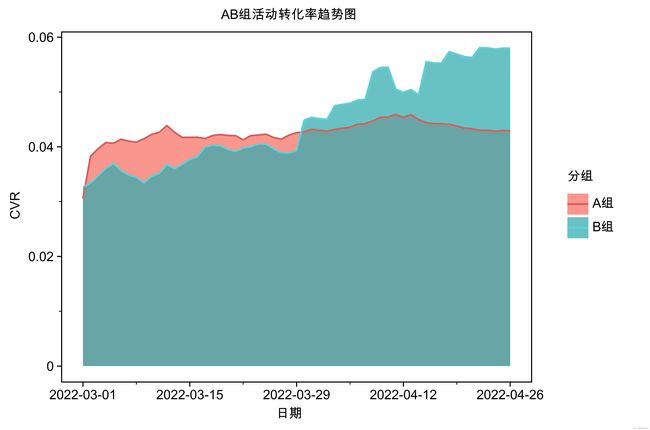
def plot_a_2(df):
base_plot = (
ggplot(df, aes(x='日期', y='转化率', group='分组'))
+geom_area(aes(fill='分组'), alpha=0.75, position='identity')
+geom_line(aes(color='分组'), size=0.75)
+scale_x_date(name='日期', breaks='2 weeks') #解决x轴日期标签间隔、覆盖问题
+scale_fill_hue(s=0.90, l=0.65, h=0.0417, color_space='husl')
+xlab('时间')
+ylab('CVR')
+ggtitle('AB组活动转化率趋势图')
+theme_matplotlib()
)
print(base_plot)
base_plot.save('page/趋势图/图a_2.jpeg', dpi=1000)1.3夹层填充面积图
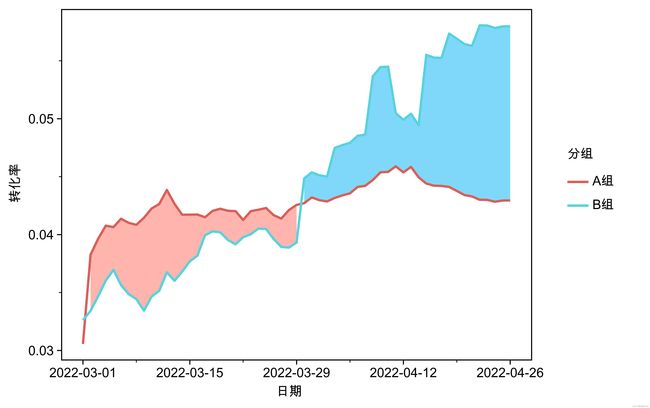
绘图前需要先对样本数据做一下处理,处理代码及处理后的dataframe如下:
def plot_a_3(df):
df_A = df[df['分组'] == 'A组']
df_B = df[df['分组'] == 'B组']
df_new = pd.merge(df_A, df_B, how='left', on='日期', suffixes=('A组', 'B组'))
df_new['最小值'] = df_new.apply(lambda x: x[['转化率A组', '转化率B组']].min(), axis=1)
df_new['最大值'] = df_new.apply(lambda x: x[['转化率A组', '转化率B组']].max(), axis=1)
#df_new['比较'] = df_new.apply(lambda x: 'A组高' if x['转化率A组'] - x['转化率B组'] > 0 else 'B组高', axis=1)
df_new['ymin1'] = df_new['最小值']
df_new.loc[(df_new['转化率A组']-df_new['转化率B组']) > 0, 'ymin1'] = np.nan
df_new['ymin2'] = df_new['最小值']
df_new.loc[(df_new['转化率A组']-df_new['转化率B组']) <= 0, 'ymin2'] = np.nan
df_new['ymax1'] = df_new['最大值']
df_new.loc[(df_new['转化率A组']-df_new['转化率B组']) > 0, 'ymax1'] = np.nan
df_new['ymax2'] = df_new['最大值']
df_new.loc[(df_new['转化率A组']-df_new['转化率B组']) <= 0, 'ymax2'] = np.nan
base_plot=(
ggplot()
+geom_ribbon(df_new, aes(x='日期', ymin='ymin1', ymax='ymax1', group=1), alpha=0.5, fill='#00B2F6', color='none')
+geom_ribbon(df_new, aes(x='日期', ymin='ymin2', ymax='ymax2', group=1), alpha=0.5, fill='#FF6B5E', color='none')
+geom_line(df, aes(x='日期', y='转化率', group='分组', color='分组'), size=1)
+scale_x_date(name='日期', breaks='2 weeks')
+theme_matplotlib()
)
print(base_plot) 
做以上处理的目的是为作图做准备:
①最大值、最小值:用于绘制夹层的填充线;
②之所以ymin1/ymax1 与 ymin2/ymax2 区分开,是为了区分填充线颜色
③之所以绘制两次ribbon除了原因②之外,也是为了避免出现多余的填充
1.4百分比堆积面积图
场景case:
某互联网公司在全国城市推广了一种引流活动,并将城市划分了7个等级(一线、新一线、二线....其他),因为来自不同城市等级的用户质量不同,所以需要关注每个活动期次中用户来源的城市等级构成变化。
样本示例:
同一‘活动期次’中,‘同期占比’之和为1,虽然样本中有这一数据,但我们在绘图时不会用到"同期占比",所以在实际绘图导入数据时无需计算该值。


def plot_a_4(df):
base_plot = (
ggplot(df, aes(x='活动期次', y='参与人数', fill='城市等级', group='城市等级'))
+geom_area(position='fill', alpha=1)
+geom_line(position='fill', size=0.25, color='black')
+scale_fill_hue(s=0.99, l=0.65, h=0.0417, color_space='husl')
+xlab('活动期次')
+ylab('同期占比')
+theme_matplotlib()
)
print(base_plot)
base_plot.save('page/趋势图/图a_4.jpeg', dpi=1000)补充:与1.2面积图不同的是position参数的设置,‘identity’表示不改变位置,而‘fill’则表示在多数据系列时以百分比的形式堆叠(数量会自动转为占比后在y轴显示),另外比较常用的还有position='stack',意思是堆积,假如仅把上图position参数fill换成stack,那么输出如下:
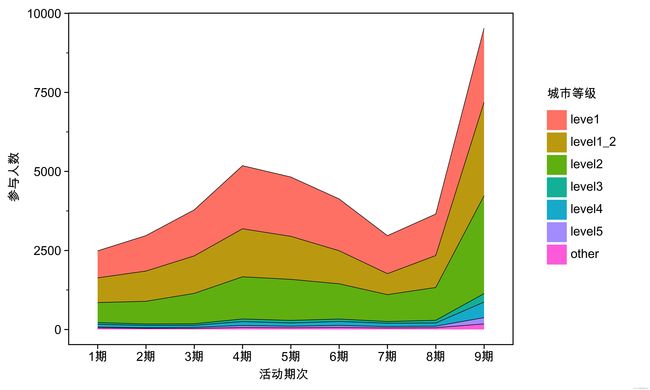
图解:例如第"1期"的y轴值约2500,该值表示所有城市等级用户数量之和。
也就是说:每个系列的开始点是前一个数据系列的结束点,y轴的值表示多个系列的数值之和。
而假如,仅把上述代码中position参数换成identity,则输出如下:
此时y轴的值仅表示某一单个系列的数值。

二、类别比较型图表系列
2.1单数据系列柱形图
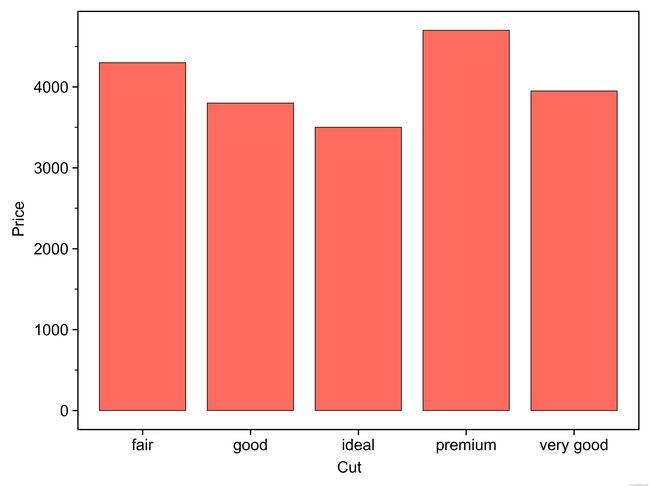
def plot_b_1():
df = pd.DataFrame({'Cut': ['fair', 'good', 'very good', 'premium', 'ideal'], 'Price': [4300, 3800, 3950, 4700, 3500]})
base_plot = (
ggplot(df, aes(x='Cut', y='Price'))
+geom_bar(stat='identity', width=0.8, colour='black', size=0.25, fill='#FF6B5E', alpha=1)
+theme_matplotlib()
)
print(base_plot)
base_plot.save('page/类别比较/图b_1_1.jpeg', dpi=1000)补充:类别排序问题
绘制柱形图、条形图系列的最大潜在问题就是排序,
plotnine绘制柱形图时,X轴变量默认会按照输入的数据顺序绘制,若要调整顺序,需对dataframe的类别顺序进行调整(pandas.Categorical方法的使用),
假如要将上图的绘制顺序改为按"Price"的值降序排列,则代码为:
def plot_b_1():
df = pd.DataFrame({'Cut': ['fair', 'good', 'very good', 'premium', 'ideal'], 'Price': [4300, 3800, 3950, 4700, 3500]})
sort_df = df.sort_values(by='Price', ascending=False)
sort_df['Cut'] = pd.Categorical(sort_df['Cut'], categories=sort_df['Cut'], ordered=True)
base_plot = (
ggplot(sort_df, aes(x='Cut', y='Price'))
+geom_bar(stat='identity', width=0.8, colour='black', size=0.25, fill='#FF6B5E', alpha=1)
+theme_matplotlib()
)
print(base_plot)
base_plot.save('page/类别比较/图b_1_2.jpeg', dpi=1000)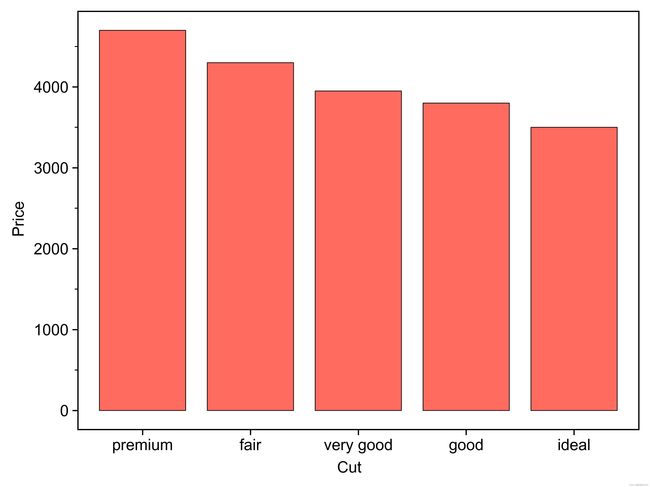
若要自定义类别顺序,可以修改如下代码:
例如将顺序修改为 fair→premium→very good→ideal→good
df = pd.DataFrame({'Cut': ['fair', 'good', 'very good', 'premium', 'ideal'], 'Price': [4300, 3800, 3950, 4700, 3500]})
df['Cut'] = pd.Categorical(sort_df['Cut'], categories=['fair','premium','very good','ideal','good'], ordered=True)2.2多数据系列柱形图

def plot_b_2():
df = pd.DataFrame({'Cut': ['fair', 'good', 'very good', 'premium', 'ideal'],
'Price_A': [4300, 3800, 3950, 4700, 3500],
'Price_B': [4000, 3200, 4300, 3700, 3000]})
#做数据处理,目的是以Price_A的值降序绘制
df = df.sort_values(by='Price_A', ascending=False)
#原始数据是二维表,需要将其转化成一维表
df_new = pd.melt(df, id_vars='Cut')
df_new['Cut'] = pd.Categorical(df_new['Cut'], categories=df['Cut'])
base_plot = (
ggplot(df_new, aes(x='Cut', y='value', fill='variable'))
+geom_bar(stat='identity', color='black', position='dodge', width=0.7, size=0.25)
#dodge水平抖动放置、stack垂直堆叠放置、identity不做调整(多系列情况下会存在覆盖问题)、fill百分比堆叠
+scale_fill_hue(s=0.90, l=0.65, h=0.0417, color_space='husl')
#若自定义填充色
#+scale_fill_manual(values=['#FF6B5E','#00B2F6'])
+theme_matplotlib()
)
print(base_plot)
base_plot.save('page/类别比较/图b_2.jpeg', dpi=1000)补充:表降维处理
pandas.melt()方法
案例中原始及降维后的数据框如下:
原始:
Cut Price_A Price_B
0 fair 4300 4000
1 good 3800 3200
2 very good 3950 4300
3 premium 4700 3700
4 ideal 3500 3000
降维处理后:
Cut variable value
0 premium Price_A 4700
1 fair Price_A 4300
2 very good Price_A 3950
3 good Price_A 3800
4 ideal Price_A 3500
5 premium Price_B 3700
6 fair Price_B 4000
7 very good Price_B 4300
8 good Price_B 3200
9 ideal Price_B 30002.3堆积柱形图

def plot_b_3():
#数据示例:分活动类型、城市等级对比参与活动的用户数量
#说明:例如,活动A中一线城市的参与用户数为150人,二线1200人,...
df = pd.DataFrame({'城市等级': ['一线', '二线', '三线', '四线', '五线'],
'活动A': [150, 1200, 1300, 2800, 2000],
'活动B': [400, 1100, 2300, 2900, 2700],
'活动C': [390, 1700, 3300, 3500, 4200],
'活动D': [300, 900, 1900, 2800, 3300],
'活动E': [130, 790, 1800, 3000, 4200]})
#降维处理
df_new = pd.melt(df, id_vars='城市等级')
# 按活动类型求和并按求和结果降序排列
sum_df = df.iloc[:, 1:].apply(lambda x: x.sum(), axis=0).sort_values(ascending=False)
# 调整X轴类别排序:类别(活动类型)按总数量降序排列
df_new['variable'] = pd.Categorical(df_new['variable'], categories=sum_df.index)
# 调整图例排序:按城市线级有序排列(自定义顺序)
df_new['城市等级'] = pd.Categorical(df_new['城市等级'], categories=['一线', '二线', '三线', '四线', '五线'])
base_plot = (
ggplot(df_new, aes(x='variable', y='value', fill='城市等级'))
+geom_bar(stat='identity', color='black', position='stack', width=0.7, size=0.25)
#自定义配色,更多配色方案可参考网址:colorbrewer2.org
+scale_fill_manual(values=('#084081', '#2b8cba', '#7bccc4', '#e0f3db', '#ccebc5'))
+theme_matplotlib()
)
print(base_plot)
base_plot.save('page/类别比较/图b_3.jpeg', dpi=1000)2.4百分比堆积柱形图

只需将图2.3代码中的position参数改为:fill
def plot_b_4():
#数据示例:分活动类型、城市等级对比参与活动的用户数量
#说明:例如,活动A中一线城市的参与用户数为150人,二线1200人,...
df = pd.DataFrame({'城市等级': ['一线', '二线', '三线', '四线', '五线'],
'活动A': [150, 1200, 1300, 2800, 2000],
'活动B': [400, 1100, 2300, 2900, 2700],
'活动C': [390, 1700, 3300, 3500, 4200],
'活动D': [300, 900, 1900, 2800, 3300],
'活动E': [130, 790, 1800, 3000, 4200]})
#降维处理
df_new = pd.melt(df, id_vars='城市等级')
# 按活动类型求和并按求和结果降序排列
sum_df = df.iloc[:, 1:].apply(lambda x: x.sum(), axis=0).sort_values(ascending=False)
# 调整X轴类别排序:类别(活动类型)按总数量降序排列
df_new['variable'] = pd.Categorical(df_new['variable'], categories=sum_df.index)
# 调整图例排序:按城市线级有序排列(自定义顺序)
df_new['城市等级'] = pd.Categorical(df_new['城市等级'], categories=['一线', '二线', '三线', '四线', '五线'])
base_plot = (
ggplot(df_new, aes(x='variable', y='value', fill='城市等级'))
+geom_bar(stat='identity', color='black', position='fill', width=0.7, size=0.25)
#自定义配色,更多配色方案可参考网址:colorbrewer2.org
#+scale_fill_manual(values=('#084081', '#2b8cba', '#7bccc4', '#e0f3db', '#ccebc5'))
#自动配色
+scale_fill_brewer(palette='GnBu')
+theme_matplotlib()
)
print(base_plot)
base_plot.save('page/类别比较/图b_4.jpeg', dpi=1000)2.5条形图
只需要在柱形图plot内增加"+coord_flip()",将X-Y轴旋转
例如:图2.4百分比堆积柱形图 转换为 百分比堆积条形图

def plot_b_5():
df = pd.DataFrame({'城市等级': ['一线', '二线', '三线', '四线', '五线'],
'活动A': [150, 1200, 1300, 2800, 2000],
'活动B': [400, 1100, 2300, 2900, 2700],
'活动C': [390, 1700, 3300, 3500, 4200],
'活动D': [300, 900, 1900, 2800, 3300],
'活动E': [130, 790, 1800, 3000, 4200]})
df_new = pd.melt(df, id_vars='城市等级')
sum_df = df.iloc[:, 1:].apply(lambda x: x.sum(), axis=0).sort_values(ascending=False)
df_new['variable'] = pd.Categorical(df_new['variable'], categories=sum_df.index)
df_new['城市等级'] = pd.Categorical(df_new['城市等级'], categories=['一线', '二线', '三线', '四线', '五线'])
base_plot = (
ggplot(df_new, aes(x='variable', y='value', fill='城市等级'))
+geom_bar(stat='identity', color='black', position='fill', width=0.7, size=0.25)
+scale_fill_brewer(palette='GnBu')
#X-Y轴旋转
+coord_flip()
+theme_matplotlib()
)
print(base_plot)
base_plot.save('page/类别比较/图b_5.jpeg', dpi=1000)2.6哑铃图

def plot_b_6():
#数据示例:对比各营销活动在今年和去年的参与人数变化
df = pd.DataFrame({'活动类型': ['活动A', '活动B', '活动C', '活动D', '活动E', '活动F', '活动G'],
'去年': [1150, 1200, 1300, 2800, 2000, 3000, 4200],
'今年': [1400, 1100, 2300, 2900, 2700, 2800, 3000]})
#降维处理
df_new = pd.melt(df, id_vars='活动类型')
base_plot = (
ggplot(df_new, aes(x='value', y='活动类型', fill='variable'))
+geom_line(aes(group='活动类型'))
+geom_point(shape='o', size=3, colour='black')
+scale_fill_manual(values=('#00AFBB', '#FC4E07', '#36BED9'))
+theme_matplotlib()
)
print(base_plot)
base_plot.save('page/类别比较/图b_6.jpeg', dpi=1000)补充:哑铃图进阶
对比"今年"比"去年"的参与人数,如果升高则浅蓝色表示,降低则红色表示,在数据量较大时更容易区分升高或降低的趋势

def plot_b_6_2():
#数据示例:对比各营销活动在今年和去年的参与人数变化
df = pd.DataFrame({'活动类型': ['活动A', '活动B', '活动C', '活动D', '活动E', '活动F', '活动G'],
'去年': [1150, 1200, 1300, 2800, 2000, 3000, 4200],
'今年': [1400, 1100, 2300, 2900, 2700, 2800, 3000]})
df['对比'] = df.apply(lambda x: '升高' if x['今年']-x['去年'] >= 0 else '降低', axis=1)
#降维处理
df_new = pd.melt(df[['活动类型', '去年', '今年']], id_vars='活动类型')
#对比结果标记,用于画图时作颜色区分
df_new = pd.merge(df_new, df[['活动类型', '对比']], how='left', right_index=False)
base_plot = (
ggplot(df_new, aes(x='value', y='活动类型', fill='对比'))
+geom_line(aes(group='活动类型', color='对比'))
+geom_point(shape='o', size=3, colour='w')
+scale_fill_manual(values=('#00AFBB', '#FC4E07'))
+scale_color_manual(values=('#00AFBB', '#FC4E07'))
+theme_matplotlib()
)
print(base_plot)
base_plot.save('page/类别比较/图b_6_2.jpeg', dpi=1000)2.7 坡度图

def plot_b_7_1():
#场景:某班级学生今年考试分数与去年对比
df = pd.DataFrame({'姓名': ['张三', '李四', '王五', '赵六', '小明', '小红', '小刚'],
'去年': [79, 65, 89, 99, 85, 92, 77],
'今年': [81, 77, 95, 79, 92, 89, 85]})
#添加辅助列,分数下降的学生颜色突出
df['变化'] = df.apply(lambda x: 'red' if x['今年']-x['去年'] < 0 else 'green', axis=1)
base_plot = (
ggplot(df)
#画连接线
+geom_segment(aes(x=1, xend=2, y='去年', yend='今年', color='变化'), size=.75, show_legend=False)
#画垂直线
+geom_vline(xintercept=1, linetype='solid', size=.1)
+geom_vline(xintercept=2, linetype='solid', size=.1)
#画点
+geom_point(aes(x=1, y='去年'), size=3, shape='o', fill='grey', color='black')
+geom_point(aes(x=2, y='今年'), size=3, shape='o', fill='grey', color='black')
#自定义颜色
+scale_color_manual(labels=('Up', 'Down'), values=('#A6D854', '#FC4E07'))
)
#添加文本信息
df['左侧文本'] = df.apply(lambda x: x['姓名'] +','+ str(x['去年']), axis=1)
df['右侧文本'] = df.apply(lambda x: x['姓名'] +','+ str(x['今年']), axis=1)
print(df)
base_plot = (
base_plot
#文本位置:右对齐;左对齐
+geom_text(label=df['左侧文本'], y=df['去年'], x=0.95, size=10, ha='right')
+geom_text(label=df['右侧文本'], y=df['今年'],x=2.05, size=10, ha='left')
#垂直线标题及位置
+geom_text(label='去年', x=1, y=1.05 * (np.max(np.max(df[['去年', '今年']]))), size=12)
+geom_text(label='今年', x=2, y=1.05 * (np.max(np.max(df[['去年', '今年']]))), size=12)
+ xlim(.5, 2.5)
+ ylim(60, 105)
+theme_matplotlib()
#隐藏横纵轴标题、横轴文字
+theme(axis_text=element_blank(), axis_title=element_blank(), axis_ticks=element_blank())
)
print(base_plot)
base_plot.save('page/类别比较/图b_7_1.jpeg', dpi=1000)补充:主题系统的常用对象
| 对象 | 坐标轴 | 图例 | 函数及参数 |
| 文本:text | axis_title axis_title_x axis_title_y axis_text axis_text_x axis_text_y |
legend_text legent_text_align legent_text_title |
element_text() 参数:family,face,Colour,size,hjust, vjust,angle,lineheight element_blank() 隐藏 |
| 矩形:rect | legend_background legend_margin legend_spacing legend_spacing_x legend_spacing_y |
element_rect() 参数:colour,size,type element_blank() 隐藏 |
|
| 线条:line | axis_line axis_line_x axis_line_y axis_ticks axis_ticks_x axis_ticks_y axis_ticks_length axis_ticks_margin |
element_line() 参数:fill,colour,size,type element_blank() 隐藏 |
三、分布型图表
3.1统计直方图

案例:某平台用户年龄、性别分布
数据概览:
age gender
0 15 男
1 18 男
2 17 男
3 18 男
4 17 男
... ... ...
12036 26 未填写
12037 37 未填写
12038 24 未填写
12039 15 未填写
12040 13 未填写
[12041 rows x 2 columns]def plot_c_1():
df = pd.read_csv('data/分布型图表/网站用户年龄性别.csv')
print(df)
base_plot = (
ggplot(df,aes(x='age',fill='gender'))
#binwidth-箱宽度、bins-箱总数量、size-箱边框宽度、colour-箱边框颜色
+geom_histogram(binwidth=1, alpha=0.55,colour='black',size=0.25)
+scale_fill_hue(s=0.90, i=0.65, h=0.0417, color_space='husl')
+theme_matplotlib()
)
print(base_plot)
base_plot.save('page/分布型/图c_1.jpeg', dpi=1000)
plot_c_1()3.2核密度估计图
案例数据同3.1

def plot_c_2():
df = pd.read_csv('data/分布型图表/网站用户年龄性别.csv')
print(df)
base_plot = (
ggplot(df,aes(x='age',fill='gender'))
#bw-带宽、kernel-核函数(默认高斯核函数gaussian)
+geom_density(bw=1, alpha=0.55, colour='black', size=0.25)
+scale_fill_hue(s=0.90, i=0.65, h=0.0417, color_space='husl')
+theme_matplotlib()
)
print(base_plot)
base_plot.save('page/分布型/图c_2.jpeg', dpi=1000)
plot_c_2()3.3抖动散点图
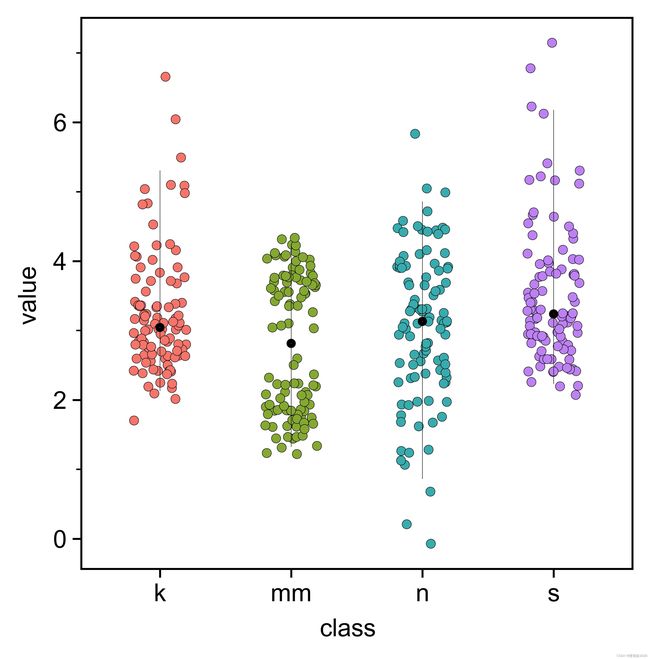
def plot_c_3():
df = pd.read_csv('data/分布型图表/抖动散点图.csv')
base_plot=(
ggplot(df,aes(x='class',y="value",fill="class"))
+geom_jitter(width=0.2,size=2,stroke=0.1,show_legend=False)
# 中位数+标准差误差线
+stat_summary(fun_data="median_hilow", fun_args={'confidence_interval': 0.95}, geom="pointrange",color="black", size=0.1, show_legend=False)
+stat_summary(fun_data="median_hilow", fun_args={'confidence_interval': 0.95}, geom="point", fill="w",color="black", size=0.1, stroke=1, show_legend=False)
# 平均值+标准差误差线
# +stat_summary(fun_data="mean_sdl", fun_args = {'mult':1},geom="pointrange", color = "black",size = 1,show_legend=False)
# +stat_summary(fun_data="mean_sdl", fun_args = {'mult':1},geom="point", fill="w",color = "black",size = 1,stroke=1,show_legend=False)
# +geom_point(stat="summary", fun_data="mean_sdl",fun_args = {'mult':1},fill="w",color = "black",size = 1,stroke=1,show_legend=False) # 另一种实现方式
+scale_fill_hue(s = 0.90, l = 0.65, h=0.0417,color_space='husl')
+theme_matplotlib()
+theme(aspect_ratio =1,dpi=100,figure_size=(4,4))
)
print(base_plot)补充:画布调整
theme(aspect_ratio=1.5,dpi=100,figure_size=(4,6))
aspect_ratio=1.5 即 高/宽=1.5;
figure_size=(4,6) 即 宽4、高6
画布比例以aspect_ratio优先
3.4箱型图

def plot_c_4():
df = pd.read_csv('data/分布型图表/抖动散点图.csv')
base_plot=(
ggplot(df,aes(x='class',y="value",fill="class"))
+geom_boxplot(show_legend=False)
+geom_jitter(fill='black',shape='.', width=0.2,size=3,stroke=0.1,show_legend=False)
+scale_fill_hue(s = 0.90, l = 0.65, h=0.0417,color_space='husl')
+theme_matplotlib()
)
print(base_plot)
base_plot.save('page/分布型/图c_4.jpeg', dpi=1000)3.5小提琴图

def plot_c_5_1():
df = pd.read_csv('data/分布型图表/抖动散点图.csv')
base_plot=(
ggplot(df,aes(x='class',y="value",fill="class"))
+geom_violin(show_legend=False)
+geom_jitter(fill='black',shape='.', width=0.2,size=3,stroke=0.1,show_legend=False)
+scale_fill_hue(s = 0.90, l = 0.65, h=0.0417,color_space='husl')
+theme_matplotlib()
)
print(base_plot)
base_plot.save('page/分布型/图c_5_1.jpeg', dpi=1000)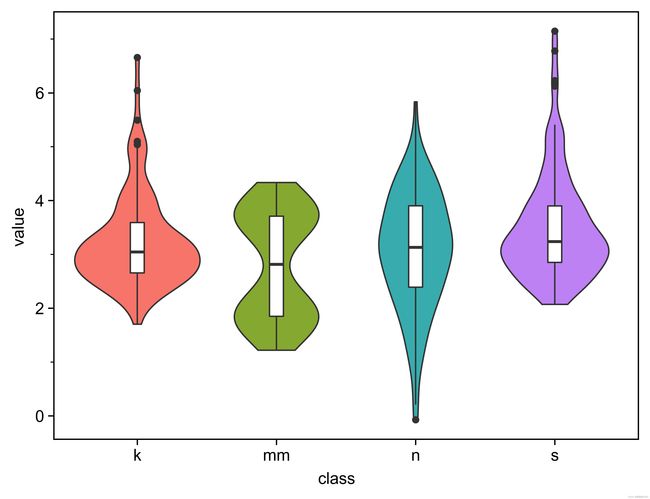
def plot_c_5_2():
df = pd.read_csv('data/分布型图表/抖动散点图.csv')
base_plot=(
ggplot(df,aes(x='class',y="value",fill="class"))
+geom_violin(show_legend=False)
+geom_boxplot(fill='white', width=0.1, show_legend=False)
+scale_fill_hue(s = 0.90, l = 0.65, h=0.0417,color_space='husl')
+theme_matplotlib()
)
print(base_plot)
base_plot.save('page/分布型/图c_5_2.jpeg', dpi=1000)