pandas预处理案例——数据分析师招聘数据清洗实战
数据分析师招聘数据清洗实战
-
- 数据导入并查看
- 重复数据处理
- 异常值处理
- 缺失值处理
数据是数据分析师的招聘薪资,主要内容是进行数据读取,数据概述,数据清洗和整理
数据获取:链接:https://pan.baidu.com/s/1sSmyiUfkDtVHuJEQP56h3w
提取码:okic
数据导入并查看
首先载入的数据在pandas中,常用的载入函数是read_csv。除此之外还有read_excel和read_table,table可以读取txt。若是服务器相关的部署,则还会用到read_sql,直接访问数据库,但它必须配合mysql相关包。
import pandas
df = pandas.read_csv('data/DataAnalyst.csv',encoding='gb2312')
#查看表数据
df.head(5)

查看表结构
df.info()
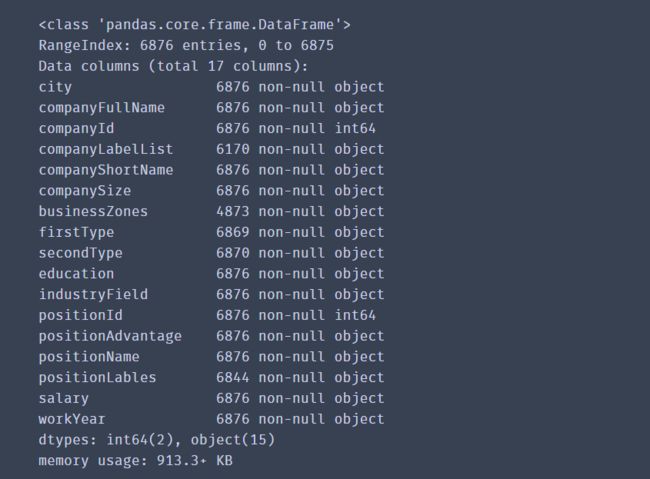
这里列举出了数据集拥有的各类字段,一共有6876个,公司id和职位id为数字,其他都是字符串。
重复数据处理
查看重复数据
print(len(df.positionId.unique()))

unique函数可以返回唯一值,数据集中positionId是职位ID,值唯一。原始值有6876,配合len函数计算出唯一值共有5031个,说明有多出来的重复值。
处理重复数据
df_duplicates=df.drop_duplicates(subset='positionId',keep='first')
df_duplicates.info()
drop_duplicates函数通过subset参数选择以哪个列为去重基准。keep参数则是保留方式,first是保留第一个,删除后余重复值,last还是删除前面,保留最后一个。duplicated函数功能类似,但它返回的是布尔值。

异常值处理
接下来加工salary薪资字段。目的是计算出薪资下限以及薪资上限。薪资内容没有特殊的规律,既有小写k,也有大小K。这里需要用到pandas中的apply。它可以针对DataFrame中的一行或者一行数据进行操作,允许使用自定义函数。
def cut_word(word):
position = word.find ("-")
bottomSalary = word[:position-1]
return bottomSalary
df_duplicates.salary.apply(cut_word)

定义word_cut函数,它查找「-」符号所在的位置,并且截取薪资范围开头至K之间的数字,也就是想要的薪资上限。apply将word_cut函数应用在salary列的所有行。「k以上」这类脏数据怎么办呢?find函数会返回-1,如果按照原来的方式截取,是word[:-2],不是想要的结果,所以需要加一个if判断。
def cut_word(word):
position = word.find ("-")
if position != -1:
bottomSalary = word[:position-1]
else:
bottomSalary = word[:word.upper().find("K")]
return bottomSalary
df_duplicates["bottomSalary"] = df_duplicates.salary.apply(cut_word)

因为python大小写敏感,我们用upper函数将k都转换为K,然后以K作为截取。这里不建议用「以上」,因为有部分脏数据不包含这两字。
将bottomSalary转换为数字,如果转换成功,说明所有的薪资数字都成功截取了。
df_duplicates.bottomSalary.astype("int")

薪资上限topSalary的思路也相近,只是变成截取后半部分。
def cut_word(word,method):
position = word.find ("-")
if position != -1:
bottomSalary = word[:position-1]
topSalary = word[position+1:len(word)-1]
else:
bottomSalary = word[:word.upper().find("K")]
topSalary = bottomSalary
if method == "bottom":
return bottomSalary
else:
return topSalary
df_duplicates["topSalary"] = df_duplicates.salary.apply(cut_word,method = "top")

接下来求解平均薪资。
bottomSalary和topSalary数据类型转换为数字,并为数据集添加avgSalary列
df_duplicates.bottomSalary=df_duplicates.bottomSalary.astype("int")
df_duplicates.topSalary=df_duplicates.topSalary.astype("int")
df_duplicates['avgsalary'] = df_duplicates.apply(lambda x:(x.bottomSalary+x.topSalary)/2,axis=1)
数据类型转换为数字,这里引入新的知识点,匿名函数lamba。很多时候我们并不需要复杂地使用def定义函数,而用lamdba作为一次性函数。lambda x: ******* ,前面的lambda x:理解为输入,后面的星号区域则是针对输入的x进行运算。案例中,因为同时对top和bottom求平均值,所以需要加上x.bottomSalary和x.topSalary。word_cut的apply是针对Series,现在则是DataFrame。axis是apply中的参数,axis=1表示将函数用在行,axis=1则是列。这里的lambda可以用(df_duplicates.bottomSalary + df_duplicates.topSalary)/2替代。
缺失值处理
查看缺失数据存在的列
df_duplicates.isnull().any()
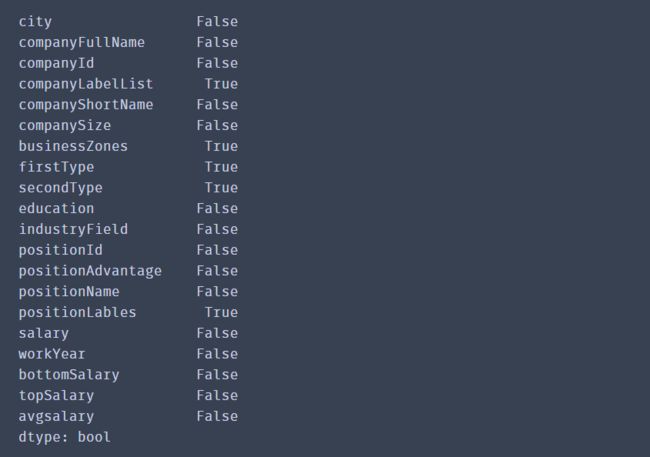
其中companyLabelList,businessZones,secondType,positionLables都存在为空的情况。由于这些字段的缺失值不能向前或者向后填充,单独填充的话数据量也很大,因此为了是数据更加精准,将有空值的行直接删除
df_duplicates.dropna(axis=0, how='any', inplace=True)

再次查看
df_duplicates.isnull().any()

到此,数据清洗的部分完成。切选出我们想要的内容
查看一下已经处理好的数据
df_duplicates.head(10)
