Pandas-groupby
PANDAS的分组groupby讲解
groupby
- PANDAS的分组groupby讲解
-
- 分布代码演示及结果
- 完整代码展示
分布代码演示及结果
import pandas as pd
import numpy as np
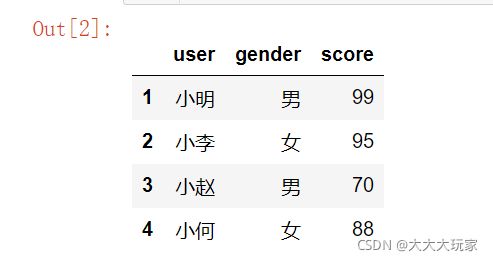
df=pd.DataFrame({
'user':['小明','小李','小赵','小何']
'gender':['男','女','男','女'],
'score':[99,95,70,88]
},index=['1','2','3','4'])
print(df) #创建表格`
df.groupby('gender') #按照性别进行分组
输出结果:
{‘女’: [‘2’, ‘4’], ‘男’: [‘1’, ‘3’]}
df.groupby('gender').groups #获取分组情况
输出结果:
{‘女’: [‘2’, ‘4’], ‘男’: [‘1’, ‘3’]}
grouped=df.groupby('gender') #迭代输出各个组的情况,#name是分组名,group是数据块
for name,group in grouped:
print(name)
print(group)
输出结果:
女
user gender score
2 小李 女 95
4 小何 女 88
男
user gender score
1 小明 男 99
3 小赵 男 70
#选择组
grouped.get_group('女')

#选择组进行聚合运算
grouped.get_group('女')['score'].agg(np.mean)
输出结果:
91.5
#选择组进行聚合运算
grouped.get_group('女')['score'].agg(np.max)
输出结果:
95
grouped.get_group('女').agg(np.size)#获取分组里的长度
输出结果:
user 2
gender 2
score 2
dtype: int64
df['star']=pd.Series([5,7,4,3],index=['1','2','3','4']) #在df中新添加列
df

grouped=df.groupby('gender')
grouped[['score','star']].agg({'score':np.mean,'star':np.sum})#对分组后的对应列进行数据分析
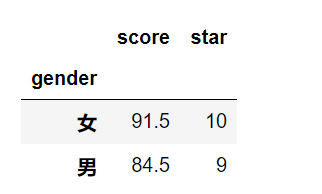
grouped.agg({'score':np.mean,'star':np.sum})#将分组后的指定列进行指定的数据处理

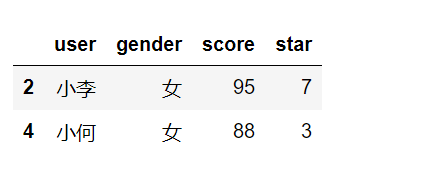
df.groupby('gender').filter(lambda x:x['score'].mean()>90)#筛选出大于90的组的所有数据
完整代码展示
import pandas as pd
import numpy as np
df=pd.DataFrame({
'user':['小明','小李','小赵','小何'],
'gender':['男','女','男','女'],
'score':[99,95,70,88]
},index=['1','2','3','4'])
df #创建表格
df.groupby('gender') #按照性别进行分组
df.groupby('gender').groups#获取分组情况
grouped=df.groupby('gender') #迭代输出各个组的情况,#name是分组名,group是数据块
for name,group in grouped:
print(name)
print(group)
#选择组
grouped.get_group('女')
#选择组进行聚合运算
grouped.get_group('女')['score'].agg(np.mean)
#选择组进行聚合运算
grouped.get_group('女')['score'].agg(np.max)
grouped.get_group('女').agg(np.size)#获取分组里的长度
df['star']=pd.Series([5,7,4,3],index=['1','2','3','4']) #在df中新添加列
df
grouped=df.groupby('gender')
grouped[['score','star']].agg({'score':np.mean,'star':np.sum})
grouped.agg({'score':np.mean,'star':np.sum})#将分组后的指定列进行指定的数据处理
df.groupby('gender').filter(lambda x:x['score'].mean()>90)#筛选出大于90的组的所有数据