【Kaggle】Python数据分析:银行客户消费预测
我们上次在《kaggle新手在平台学习大神的代码》(https://mp.csdn.net/editor/html/111656521)一文中介绍了如何在kaggle中学习大神的代码, 并简单介绍了房价预测, 泰坦尼克号生存预测两个比赛, 可以在文末获取该文链接。
本文为前文的进阶, 并详细翻译和注释了Kaggle上 桑坦德银行客户交易预测比赛(Santander Customer Transaction Prediction) 下某位大神的代码。你可以在在我们的公众号“数据臭皮匠” 中回复“银行客户消费预测” 获取数据集和代码(包含大神原代码, 大神原代码注释版, 大神原代码重构注释版)
笔者认为本文最大的贡献是:尽最大努力翻译注释了大神的代码, 能为kaggle新手降低学习门槛,。完整学习一篇大神代码之后, 读者慢慢就能够尝试寻找最适合自己的代码用以学习借鉴了
赛题介绍:
在这一比赛中,我们邀请Kagglers帮助我们确定哪些客户将来会进行特定交易,而与交易金额无关。
所以这是一个二分类文图,银行想知道,未来哪些客户将会有交易,比赛方给的数据中包含train和test两个数据集,每份数据集包含20万行数据,每行包括200个数值型变量。
1.如何下载数据集
你可以尝试自己从kaggle上下载数据集
2.如何找到并下载大神的代码
3.开始前奏
下载好数据和代码就可以开始照抄大神的代码了, 我认为在初期, 照抄是效率最高的学习方式, 就像练字需要先临摹字帖一样。如果有同学在下载过程中遇到问题,也可以在我们的公众号“数据臭皮匠” 中回复“银行客户消费预测” 获取数据集和代码
由于原作者的代码有很多不必要的画图,且结构不合理,本文会对原作者的代码做一些改动,以增强可读性,跟原作者代码结构一模一样的jupyter我们也会提供
下面是原文代码的翻译(包括文字部分), 笔者的补充将使用斜体字, 以示区别
桑坦德的魔法
在这篇代码中, 我们将要展示桑坦德的魔法图片(之前的代码:
https://www.kaggle.com/cdeotte/modified-naive-bayes-santander-0-899)
在"Modified Naive Bayes"中, 我们了解到,我们可以对每一个变量分别建模然后使用逻辑回归组合这200个模型, 分数能够达到0.899。在这里我们将给每一个变量添加魔法变量后使用相同的方法, 然后使用逻辑回归集成这200个模型, 分数可以达到0.9200。

魔法变量
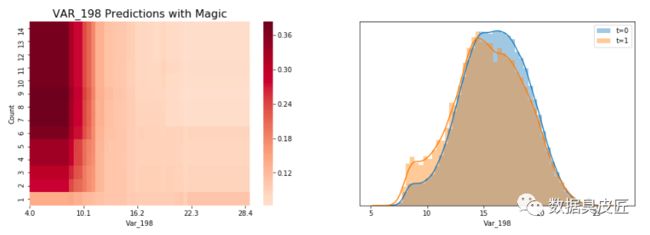
当LGBM看到变量var_198的水平值, 它看起来是当var_198<13 时, target=1 的概率较高,当var_198 >13 时概率较低. 这个现象可以通过LGBM的预测展示出来(当只使用一个变量var_198建模时), 当var_198<13时,LGBM预测target=0.18, 其他情况target=0.1 。
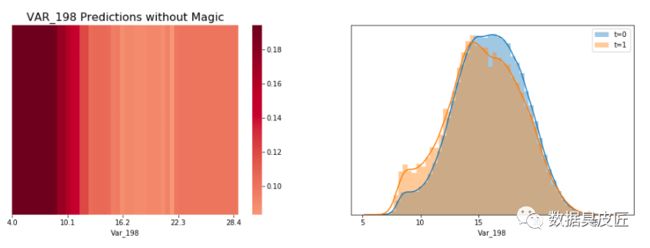
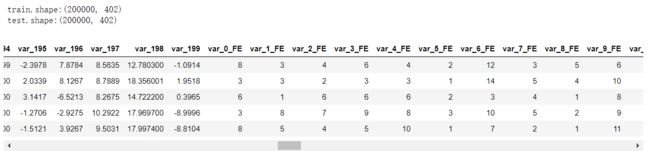
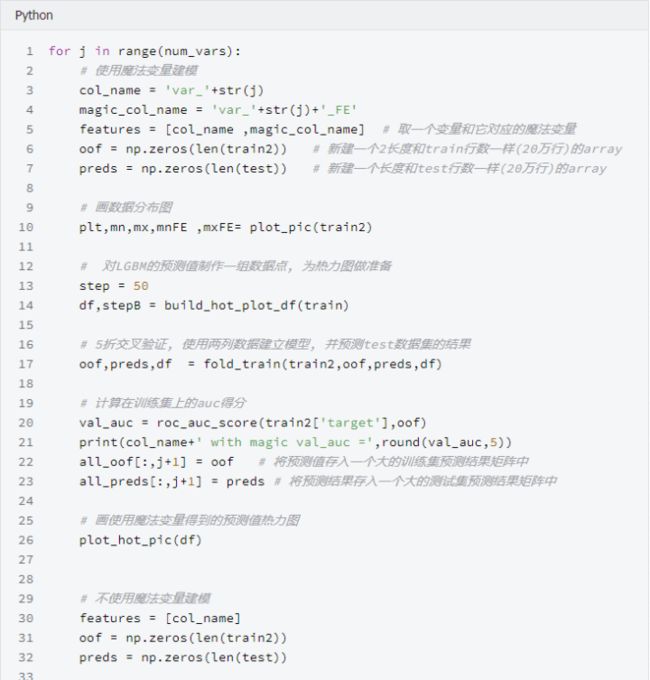
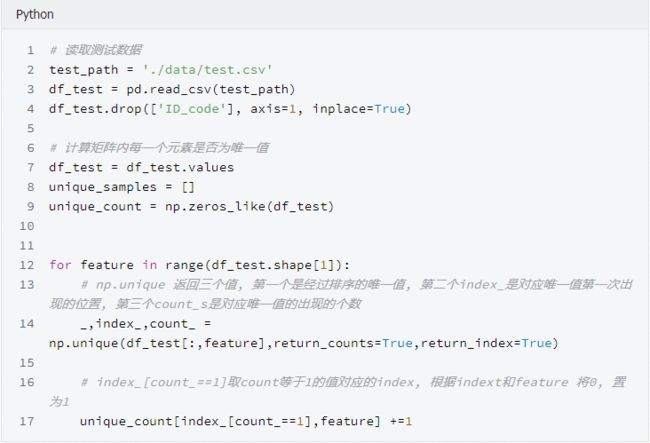
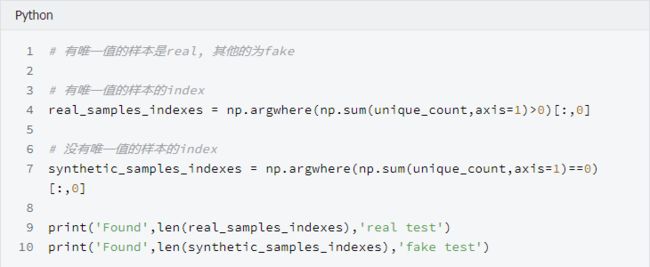
LGBM使用竖线分开柱状图,因为LGBM看不到水平值的不同, 一个柱状图在一个格子中展示多个值并产生一个平滑的图片。如果你将每个值都放到它自己的格子里,你将得到一个锯齿状的图片,图片中竖条的高度跳来跳去,一些值是唯一值, 一些值出现了很多次(在var_108中,一些值出现了超过300次!!)下方是一个聚焦在11.0000 现在了解到, 当var_198<13且count=1 时LGBM预测target=0.1 , 当var_198<13且count>1时, 它预测target=0.36。使用魔法变量导致验证集AUC提升至0.551, 当只适用var_198一个变量时AUC=0.547。 上面说这么多,是在证明,当给变量var_198 增加一个魔法变量的时候, 多了一个观测数据的维度,,单变量建模的AUC会有提升, 像这样的变量有200个, 需要分别重复这个过程。 为什么魔法变量这么难找? 魔法变量是很难找的, 因为新变量Var_198_FE 与Var_198相关, 因此如果你给带有参数feature_fraction = 0.05 的LGBM添加新变量, 你将无法提升你的CV或者LB。你必须设置feature_fraction=1.0 。然后你将从新变量获得益处,但是你也有模型虚假原始变量相关的不利影响。但是,添加这个新的变量并且使用feature_fraction=1.0 达到了CV 0.910。为了达到0.920,我们必须从原始变量相关中移除虚假影响。 我发现为什么魔法变量隐蔽的另一个原因。当计算测试数据的频数时,你必须在计数之前移除虚假测试数据(虚假测试数据描述:https://www.kaggle.com/yag320/list-of-fake-samples-and-public-private-lb-split)。否则, 你的测试集预测将会达到LB 0.900 而不是0.910,您可能会忽略无用的频率计数。 最大化魔法变量 为了最大化魔法变量益处(LB从0.910到0.920), 我们必须在防止原始变量之间互相相关的同时允许新变量与原变量有相关性。这里有三种方式可以选择: 使用数据扩充(像Jiwei'优秀代码那样:https://www.kaggle.com/jiweiliu/lgb-2-leaves-augment)。你必须保持原始变量和新变量在相同行。 像下面展示的代码一样,使用200个单独的模型 组合新变量和原始变量成一个变量。在原始数据中,简单的对每个唯一值加200(且不添加新变量) 当统计每一个出现的值时, 我们将首先拼接训练数据和真实的测试数据, 并放在一起计数。在YaG320才华横溢的代码中, (https://www.kaggle.com/yag320/list-of-fake-samples-and-public-private-lb-split) 我们了解到一半的测试数据是虚假的. 新建200个单变量模型 可以了解到, 训练集和测试机都有20万行数据,200列变量(训练集比测试集多一列target标签) 看下添加完魔法参数之后的训练集和测试机的shape 看下重采样之后的训练数据, 可以发现训练数据顺序已经被打散了 开始构建200个模型, 这里将原代码重构, 使结果更清晰 使用逻辑回归集成200个模型 参考链接: 比赛地址: https://www.kaggle.com/c/santander-customer-transaction-prediction/data 代码地址: https://www.kaggle.com/cdeotte/200-magical-models-santander-0-920 长按公众号关注我们哦(数据臭皮匠) 作者:范小匠 审核:灰灰匠 编辑:森匠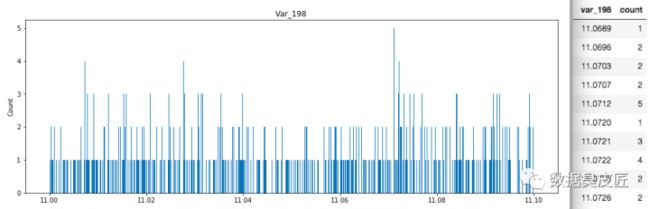
4.让我们开始吧

![]()



![]()