基于粒子群算法优化支持向量机研究(Python代码实现)
欢迎来到本博客❤️❤️
博主优势:博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
目录
1 概述
2 运行结果
3 参考文献
4 Python代码实现
1 概述
本文将分层聚类算法与二叉树相结合,在每个节点上通过分层聚类减少误差积累.利用粒子群算法寻找最优类别划分,采用类别进行编码,把同属于一类故障的样本划到同一个聚类中心。粒子群优化算法[1(particle swarm ptimization,PSO),初始化为一群随机粒子.即随机的初始解,然后粒子们根据自身的飞行经验和群体的飞行经验来调整自己的飞行轨迹,参照最优粒子的位置在解空间中搜索,并通过迭代找到最优解。遗传粒子群算法把遗传算法和粒子群算法有机结合起来,既保证了遗传算法强大的全局搜索性能,又同时融合了粒子群的位置转移思想[11],其寻优过程更有效率,所得到的解精度更高。
2 运行结果
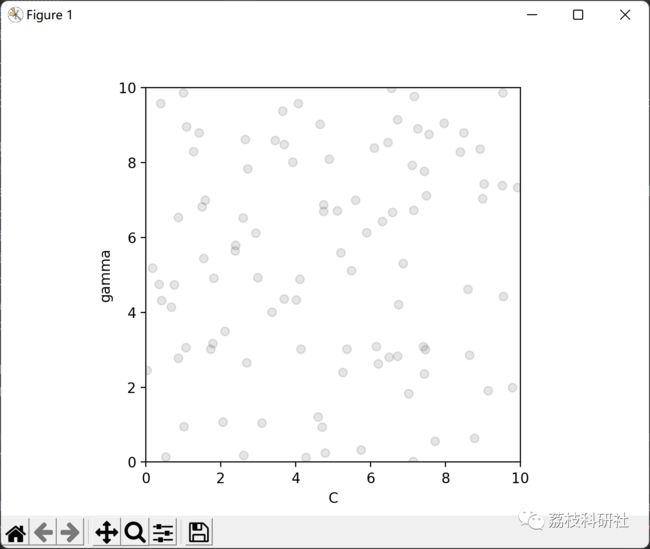
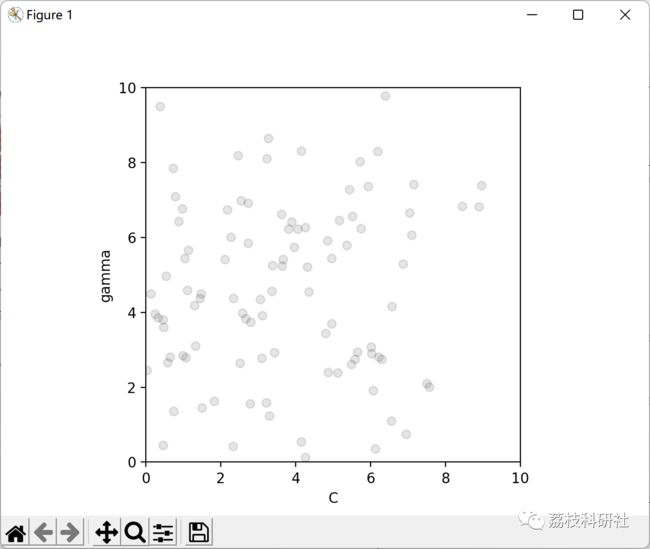
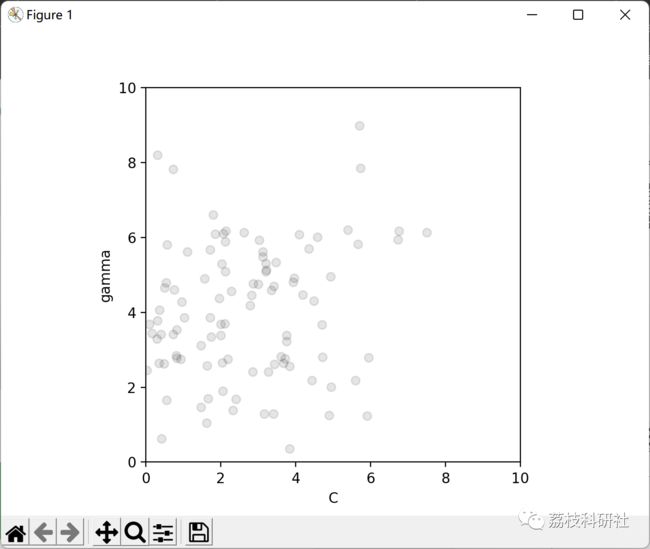
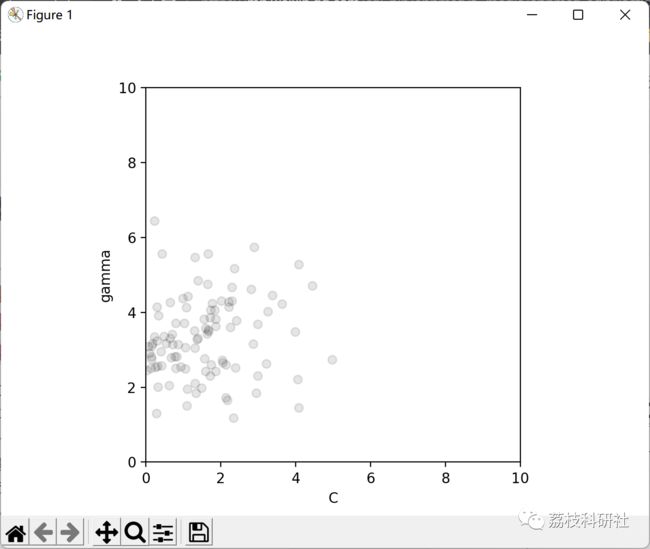
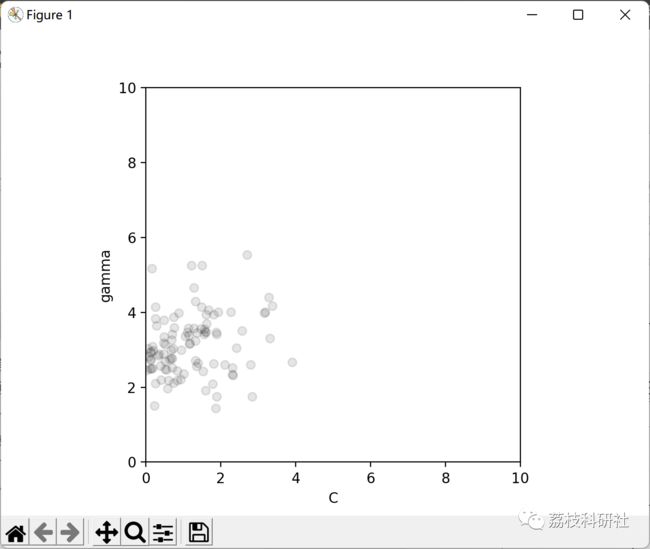
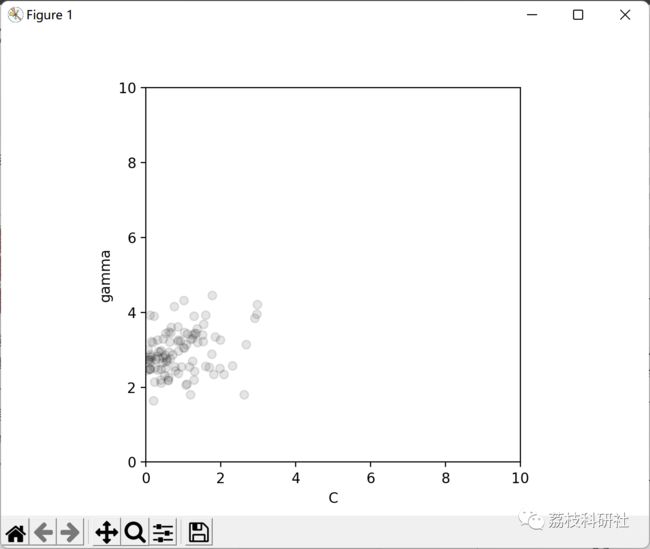
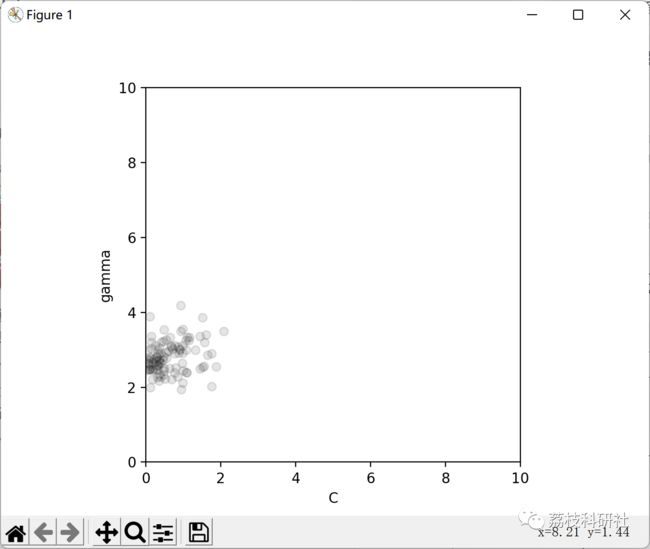
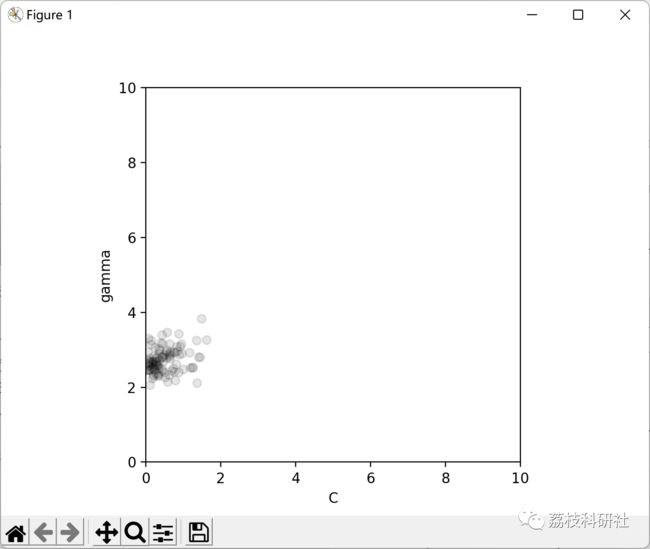
部分代码:
# -*- coding: utf-8 -*-
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import csv
import pandas as pd
import numpy as np
def plot(position):
x = []
y = []
for i in range(0,len(position)):
x.append(position[i][0])
y.append(position[i][1])
colors = (0,0,0)
plt.scatter(x, y, c = colors, alpha = 0.1)
plt.xlabel('C')
plt.ylabel('gamma')
plt.axis([0,10,0,10])
plt.gca().set_aspect('equal', adjustable='box')
return plt.show()
def data_handle_v2(data_path):
colnames = ['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x9', 'x10', 'x11', 'x12', 'x13', 'y']
data = pd.read_csv(data_path, sep=' ', header=None, names=colnames)
X = data.drop('y', axis=1)
X = (X - X.mean()) / X.std()
y = data['y']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=42)
return X_train, X_test, y_train, y_test
def data_handle_v1(csv_data_path):
def change_float(row):
out = [float(i) for i in row]
return out
# 读取并分组
with open(csv_data_path, 'r')as file:
reader = csv.reader(file)
datas = [row for row in reader]
datas = datas[1:]
datas = [change_float(row) for row in datas]
data = [row[0:-2] for row in datas]
lables = [row[-2] for row in datas]
x = np.array(data)
y = np.array(lables)
###数据先归一化,待做。。。###
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=420)
return X_train, X_test, y_train, y_test
3 参考文献
[1]何小二. 基于粒子群算法和支持向量机的船舶结构优化[D].上海交通大学,2014.
[1]余梓唐.基于粒子群算法优化支持向量机汽车故障诊断研究[J].计算机应用研究,2012,29(02):572-574.
4 Python代码实现