踩坑系列-字符编码OneHotEncoder
踩坑系列-字符编码OneHotEncoder
- OneHotEncoder
- pandas.get_dummies构造哑变量
OneHotEncoder
今天想起来,之前应用OneHotEncoder存在的问题,这里和大家分享一下。
OneHotEncoder又被称为独热编码,什么意思呢,就是
1、每一列特征需要构建的状态寄存器的位数等于该列特征独立取值的个数;
2、使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。
到底在说什么呢?请看下面的代码演示就明白了(以下代码在jupyter notebook里执行)
import numpy as np
import pandas as pd
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder()
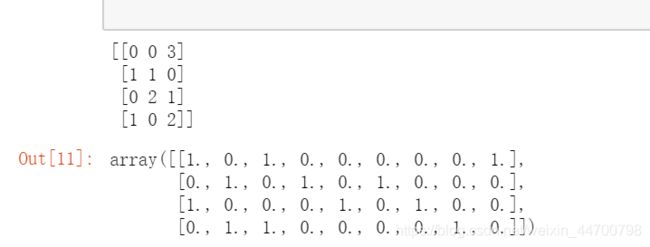
X=np.array([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])
print(X)
enc.fit_transform(X).toarray()
#第一列有两个状态:0、1,需要2位状态寄存器来进行编码,[1,0]表示0,[0,1]表示1
#第二列有三个状态:0、1、2,需要3位状态寄存器来进行编码,[1,0,0]表示0,[0,1,0]表示1,[0,0,1]表示2
#第三列有四个状态:0、1、2、3,需要4位状态寄存器来进行编码,[1,0,0,0]表示0,[0,1,0,0]表示1,[0,0,1,0]表示2,[0,0,0,1]表示3
如果这时候来一个数据:

大家对着编码一下也可以得出这个结果;
但是如果来个(4是训练时没出现的数据):


会报错,因为4在训练时不曾出现,现在也不知道怎么编码它
解决办法:
enc = preprocessing.OneHotEncoder( handle_unknown='ignore')
#默认的是 handle_unknown='error',即不认识的数据报错,改成ignore代表忽略
enc.fit_transform(X)
enc.transform([[0, 1, 4]]).toarray()

可以看到,这时候4,被编码成[0,0,0,0],这样虽然不会报错,但是会造成一定的信息损失,因此,如果需要构建模型,
OneHotEncoder编码慎用。
之前踩坑场景:GBDT+LR复合模型,对数据落在GBDT中每颗树的叶子结点下标进行独热编码,再放入LR中构建模型;
测试数据中,也是存在编码时没见过的数值,出现报错。
pandas.get_dummies构造哑变量
这个方法其实和OneHotEncoder差不多,但是不能训练数据,因此无法入模使用,只能用于数据分析。
pandas.get_dummies(data, prefix=None, prefixsep=’’, dummy_na=False, columns=None, sparse=False, drop_first=False)
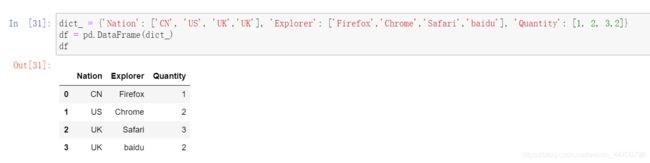
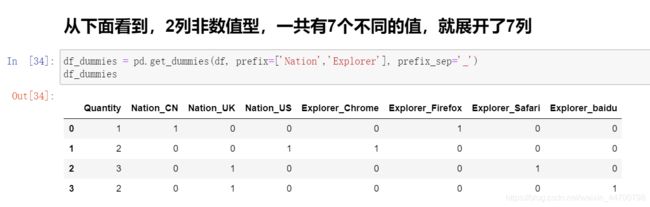
注意:Quantity列为数值型,并没有编码,编码的都是字符串型。