程序员价值观和网络复杂性-网络不可达排查过程
声明:
由于涉及到公网拓扑以及公司内部信息,本文中的IP地址一律采用化名。
序
周三由于吃了可能已经坏掉的生蚝,周四开始腹泻并发烧,周四晚上开始高烧,并持续到周五晚上,没去医院没吃药,死磕,对,死磕,然后在周六白天断断续续高烧低烧相间后,到了晚上看完同事介绍的电影《异度空间》后,好了,生病期间,没有工作,但是却断断续续写了一些技术随笔,算是《病中吟》吧...
其实,生病挺好的,对我而言,发烧就是大量喝水,不停地喝,痛快地喝,喝到快要水中毒,基本就好了,一轮见效。期间想干嘛照常干且效率高高,这是一种超爽感觉。我常说,只有与社会脱钩的人才能做自己,比如病床上的人或者监狱里的人,很多作品都是在监狱或者病榻上创作的,《史记》?《我的奋斗》?...这期间你无须承担任何社会责任。所以,超爽!《 病中吟》我听过,但我不会拉,我二胡无法拉响,心里很悲凉...
...
本文继续演示程序员和网络人员之间的互撕。首先描述一下网络拓扑

00 172.16.0.100 (Host1)->192.168.1.100 (Server1):SYN
02 172.16.0.100 (Host1)->192.168.1.100 (Server1):SYN(retransmit)
22 192.168.1.100 (Server)->172.16.0.100 (Host1):RESET
接连好几天,一直是这样!规律特别明确。
作为程序员的我
由于Server1处在公网边缘的数据中心,且承载流量巨大,在其上启用抓包是不现实的,至于原因,我说一点:即便你使用tcpdump -i eth0 host 172.16.0.100 -s 400 ...也会影响正常数据包的路径,而且是所有数据包。
Why?不是有过滤吗?是的,有过滤,但无卵用!因为所有的数据包只有过一遍这个BPF Filter,才知道自己是不是需要抓取的包,即是不是来自Host1的数据包。而我们知道这个BPF Filter是一个CPU执行的一串指令,后面我就不说了...
其实我早已有判断,来自Host1的数据包可能根本就不会到达Server1!现在的关键是确认它到底是到了还是没有到,而不是却分析什么数据包里面的TCP序列号,窗口,协商选项之类的,就算收到了来自Host1的数据包,也就一个SYN,能有毛用啊,与其说我拿到数据包去看TCP,我还不如去看看MAC和IP呢!首先看MAC可以看出它是否来自路由许可的网关,是否存在双向不对称路径,其次对比IP层的字段比如TTL,IPID等,我可以确保这个来自Host1的数据包没有被篡改。
所以我换了一种方式,与tcpdump抓包的效果相当,也是过一遍过滤器,不同的是,我选择iptables!我这么写这个规则:
iptables -A INPUT -s 172.16.0.100 (172.16.0.100是Host1的地址)
然后在很久之后,我只需要执行下面的命令就可以看到结果了:
[root@localhost ~]#iptables -L -v
Chain INPUT (policy ACCEPT .15.. packets, ..134.... bytes)
pkts bytes target prot opt in out source destination
0 0 all -- any any 172.16.0.100 anywhere
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 50 packets, 6719 bytes)
pkts bytes target prot opt in out source destination
这就是结果(结果有改动,IP为化名),根本就没有来自Host1的数据包到达,规则对应的pkts和bytes都是0!于此对应,在Host1上,分明抓取到了发往Server1的数据包!
事情到此为止应该结束了,结论是Host1到Server1之间的网络不可达或者说防火墙阻滞导致故障。证据确凿!
作为程序员的我,工作结束了,接下来我要换一个角色出演了,作为网管来排查一下这个“网络不可达或者防火墙阻滞”的细节!这以下的事情与工作无关,纯属娱乐。
中场:tcpdump还是iptables
怀疑论者会说我用iptables来逮住这个网络不可达而不是使用tcpdump可能并不妥,原因可能有二:1.iptables不够底层,万一因为协议头格式错误,校验码错误导致的数据包在目标被丢弃,tcpdump可以查出来,iptables不能!
2.iptables比较影响性能。
我十分承认第1点,但我不赞同第2点。即便存在第1点所描述的问题,我还是想冒一次险,用精确换方便。
iptables饱受诟病,因为很多人都说它会影响性能,tcpdump往往被捧为神器,尽管很多人知道,它和iptables一样,会影响性能!然而,我有几个问题:
1.说iptables会影响性能的,你们精确测量过吗?
2.把tcpdump捧为神器的,你们精确测量过吗?
关于以上两个问题,我想大多数并没有测量过,之所以捧这个污那个,或者只是单纯的试图在任何场合使用且仅使用其中一个,往往的原因有两点,第一是因为别人这么说告诉他们这么做,第二是因为第一个原因中的别人恰恰是此人初入该领域的导师或者有经验的同事。于是就这么传播开来,任何先聚集后分散蔓延的东西都符合上述,不管是互联网社交,传染病,传销,宗教,或者说简单的所谓“做事理念”。
幸运的是,我有机会跳出上述的模型。
2010年初,我进入一家中型公司,遇到的第二个导师比较严厉,当我向其推销iptables和tcpdump的时候(这两者是我2006年初入社会时,我的第一份工作中的导师传达给我的“神器”),他直接告诉我“iptables在有10000条规则的时候会降低一半的性能”,这话在我现在看来也许略微粗糙,但是在当时看来确实是给自己心头一击!太精确了!我不顾去较真如果是9999条规则会怎样,我只想赶紧去验证一下。
然而机会一直等到将近两年后才有,那时终于参与了一个真正的网络大项目,集网络编程,网络管理,网络测试,网络排错于一体,我清晰记得我占据了一间会议室,在会议桌上摆满了1U或者2U的工控机,然后模拟一个真实的网络,机器数量最多时有40多台吧,场面太壮观,随着性能测试需求的增加,不得不开辟第二战场,一来会议室桌子怕撑不住,二来电源怕撑不住,当在测试间的空地上开辟第二战场时,晚上下班时为了让测试继续进行而又不会导致火灾,我们就把数十桶的桶装水围在这些机器的周围...
在以上的环境下,难道不是想做什么就做什么?当时还在抱怨孤军奋战,现在回忆起来,看来要不是孤军奋战,我也不会有机会去锻炼自己提升自己的能力。那时我移植并优化了nf-HiPAC,测试了nftables,搞了一把netmap,PF_RING,bonding/bridge信手拈来,让数据包在Netfilter中如入无人之境...最终我确认并得到了结论,iptables确实是在10000条规则下影响一半的性能,但是精确的讲,pps越高影响越剧烈,其根源在于iptbales的线性匹配模式,tcpdump的bpf遵循同样的模式,如果你执行:
i=0
j=0
src='tcpdump -i any host '
for ((i=1;i<20;i++)); do
for ((j=103;j<133;j++)); do
temp=$src" 192.2.$i.$j or host"
src=$temp
done
done
src=$src" 192.168.11.11 -d"
echo $src
$src....
(2639) jeq #0xc002067c jt 2640 jf 2641
(2640) ja 3183
(2641) jeq #0xc002067d jt 2642 jf 2643
(2642) ja 3183
(2643) jeq #0xc002067e jt 2644 jf 2645
(2644) ja 3183
(2645) jeq #0xc002067f jt 2646 jf 2647
(2646) ja 3183
(2647) jeq #0xc0020680 jt 2648 jf 2649
(2648) ja 3183
(2649) jeq #0xc0020681 jt 2650 jf 2651
....
这很明显是一个线性匹配的过程,和iptables不同的是,bpf的线性匹配速度要比iptables的匹配速度高不少。同时,如果紧接着测试了nf-HiPAC,会发现,即便是20000条规则下,性能几乎不会有损失,具体原理请参见我2014年写的几篇关于HiPAC的文章,这并不是本文的主题。
回到本文,现在的问题是,仅仅一条iptables规则,会对性能产生多大影响?直观点讲,你把代码展开的话,会发现不过是多执行了几十行代码而已,从汇编和MIPS的角度来看会更加精确,事实上,一条iptables规则不会对性能产生影响!
但是,iptables绝对不是万能的!
如果你要实现高性能防火墙,请忘掉iptbales,它做不到!如果你要完成一个DDos防护的需求,然后你在网上搜到一个iptables方案,请忽略!iptables不是神器。但是在简单场景下,iptables也没有大家想象的那么糟糕。
下面说一下tcpdump。
这个工具也曾经被我捧为神器,当时我还是一个纯粹的程序员,并没有接触到那么多可恶,奇葩的各种网络协议,网络故障,网络不兼容等...后来,也是那段时间,2012年到2014年吧,各种诸如HSRP,IPSec,PPP,MTU probe,....然后tcpdump就完全派不上用场了,因为:
1.你可能没有同时拿到通信两端的数据包,只有一端的数据包其效果往往是极其有限的
2.中间设备无法抓包,不管是因为你根本没权限还是因为这些设备根本就不支持tcpdump(而镜像的场面又过于宏大)
如果不在机房连续折腾个数月乃至几年,一般程序员都会继续追捧tcpdump的,但事实上,中间随便一个设备随便做点手脚,就可以让tcpdump的结果五花八门令你眼花缭乱,如果你基于这些数据包想去分析出原因,那无异于一次Dos,将大量精力消耗在排查那些你不知道的小Trick上,最终的结果往往是,你只是知道了那些Trick,长了见识,而无法去控制它,对了,你可以适应它,这也是收获,然而,这代价有点大。
在一个单向TCP传输的场景中,你能仅仅通过一个数据接收端的pcap来获取发送端的行为吗?
我举一个简单的例子,以长江为例,如果从来没来过中国,也不知道长江有多长,更不知道三峡大坝,现在你第一次来到了中国上海崇明岛西端,目睹涓涓细流长江水缠绵入海,我问3个问题:
1.长江有多长?
2.水流这么细,是因为水源本来就这么细还是因为中间有大坝呢?
3.如果有大坝,那么大坝在哪里呢?
这3个问题根本没人能给出正确答案,除非你在源头和大坝那里安插一个代理人帮你进行一些测量。
所以,对于单向传输的TCP而言,不能通过接收端的行为来判定发送端的行为,因为你无法欲知中间是否有整形设备以及整形设备的位置,亦不能通过发送端的行为来判定接收端的行为,原因类似,注意,请不要试图将整形设备沿着带宽时延管道拉长而抵消其影响,这是徒劳的,因为整形设备不具备时间延展性!广义来讲,沿着从发送端到接收端的闭区间路径上任意一点的抓包都无法说明问题,并且抓包位置不同,其效果也完全不同,举例来讲,发送端的curr seq指针与curr ack指针的差就是真实的inflight,而对于接收端而言,二者相等,inflight为0,如果希望通过抓包来对网络做出评判,必须在路径上多于两个点的位置抓包,抓包点之间的距离要尽量大。
重新评估一切的价值,尼采如是说。
作为网管的我
现在开始排查Host1到达Server1路径不可达的根本原因。我无法控制Host1,除了能从一个第三方页面上下载在其上抓取的数据包之外,什么都做不来,我甚至不知道这个数据包是不是真的,我更不知道它是Windows还是Linux,是PC,云主机还是VMWare之类的...我能控制的只有Server1,于是我执行下面的步骤:
1.ping 172.16.0.100 (172.16.0.100为Host1的地址)
不通!如果通了,那就肯定是状态防火墙犯傻导致的故障了。
2.nmap -A -T4 172.16.0.100 -Pn (172.16.0.100是Host1的地址)
无果!加上Pn选项都无果!要有果了,那就更有意思了!
3....
这后面要干些什么呢?
排查一个网络问题你首先要有自己的预判断,而不是像台机器一样做例行的工作,这跟破案是一个道理!我的预判断就是Server1到Host1是路由可达的,但是Host1到Server1却不可达,得出这样的判断是基于以下的事实:Server1处在大运营商的机房,而Host1则是一个任意位置的测试客户端,就比如像国内基调这样的...如果是Server1到达Host1方向最后一公里前出现了连通性故障,那么运营商早就会发现,因此最可能故障的地方在Host1附近,或者就是Host1本身!
怎么能快速确认呢?哈哈,很容易想到的就是Idle scan了!
等等!公网上会让你任意scan吗?ICMP或者TCP Syn不是会被任意丢弃吗?这只是程序员端到端的观点,事实上,公网上的路由器都是纯粹的路由转发设备,基本会放开所有流量的。
3.从Server1对Host1来个traceroute
整理后的结果如下:
192.168.1.100 (Server1)
192.168.1.1
10.168.2.1
10.168.3.1
10.168.4.1
10.168.5.1
10.168.6.1
10.168.7.1
10.168.8.1
10.168.9.1
*
*
*
*
*
...
* (30跳超时)
自第10跳开始,音信全无!同一个省的链路,平时的统计来看,跳数在14跳左右,因此几乎可以看到是靠近Host1的地方出了问题。
心里顿时激动不已,准备Idle scan...然而当事情马上就成功时总是会有捣蛋鬼来捣蛋!
我首先要找一个公共的僵尸机器。哪里去找呢?虽然理论上这种僵尸机很好找,但是我扫描了快一个小时也没有找到,此时我想到了温州皮鞋厂老板,,温州老板有很多主机,可以帮我做成僵尸,但是要等到第二天,这可怎么行,于是我想别的办法。
利用公司资源吧,我找到同一省份的另外一个机房的机器,记为Server2,登录,然后从Server2去ping Host1的地址172.16.0.100,是通的!这说明很可能Host1到达Server1和Server2路径的分叉点上出了问题,继续之前,新的拓扑图如下:

从Server1和Server2到达Host1的traceroute结果分别如下:
Server1上traceroute Host1:
192.168.1.100 (Server1)
192.168.1.1
10.168.2.1
10.168.3.1
10.168.4.1
10.168.5.1
10.168.6.1
10.168.7.1
10.168.8.1
10.168.9.1
*
*
*
*
*
...
* (30跳超时)
Server2上traceroute Host1:
192.168.2.200 (Server2)
192.168.2.1
10.10.3.1
10.10.4.1
10.10.5.1
10.10.6.1
10.10.7.1
10.10.8.1
10.10.9.1
172.16.10.1 (分叉后的第一个跳)
172.16.11.1
172.16.12.1
172.16.0.100 (Host1)
可以找到这个分叉点,即10.10.9.1(注意,这是我整理后的化名),于是我赶紧去验证Server1到啊分叉点后一跳的可达性:
4.在Server1上ping 172.16.10.1
果然不通了!问题大概率是因为172.16.10.1,172.16.11.1,172.16.12.1,172.16.0.100这几个IP中到达Server1的路由配置错误,或者说这几个IP到达Server1的单向路径有防火墙限制!此段故障最可能发生的位置是拓扑中的“本地链路1”,最不可能发生的位置是“同运营商链路1”,但是经确认果然是同运营商链路1出来问题,这就是我为什么说运营商不靠谱的原因!
我天真的相信如果运营商链路1出了问题,会有短信告警或者别的什么的,总之可以通知管理员,但事实上,这些都仅仅是书上这么写的而已。
到此为止,我的预判断好像被打破了,可能并不是最后一公里的问题。但是最终还需要一个确认,即Server1到达Host1的单向路径到底是不是通的。
接下来...
我想把Server2作为僵尸主机开始我的最终确认,然而Server2不可能做成僵尸的,这是公司的业务机,承载的流量巨大,我也深知胡乱操作的后果...事实上,根本就不需要做成僵尸,Idle scan之所以需要找一个僵尸机,是因为scaner只能控制一台机器,而我现在可以控制Server1和Server2两台机器,而且一台通另一台不通!
最终的方法简单到极点,那就是在Server1上对Host1发送一个ping,其源IP为Server2的IP,这样如果Host1真的收到了这个ICMP Request,那么它就会把Reply发给Server2,此时如果能在Server2上抓取到了来自Host1的ICMP Reply,就可以说明Server1到达Host1单向是连通的,而Host1到达Server的路径不通。下图展示了这个三角关系:
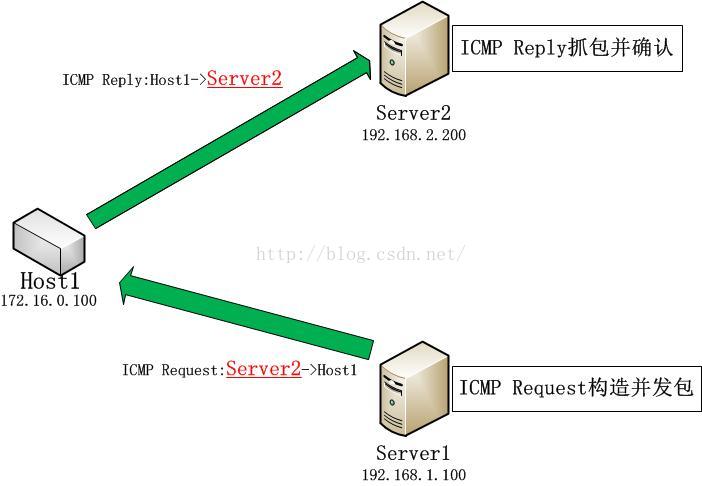
sendp(Ether()/IP(src='192.168.2.200', dst='172.16.0.100')/ICMP(), iface='eth0')tcpdump -i eth0 host 172.16.0.100 -n
果然抓到了结果:
22:46:54.671535 IP 172.16.0.100 > 192.168.1.200: ICMP echo reply, id 0, seq 0, length 8
如果说不想使用tcpdump,使用以下的命令也是等价的:
iptables -A INPUT -s 172.16.0.100
然后使用iptables -L -v来查看!这就确认了最初的猜想,结论是Server1到达Host1的单向路径是通的,但是Host1到达Server1的路径是不通的!
但是,还没有结束...
不得不面对的疑问
这种明确的结论似乎是运气结果,这个过程似乎不会被程序员所认可,然而我想说的是,对于网络上发生的事情,从来不像主机内发生的事情那么确定!运气的背后,是你要对整个过程背后那形而上的东西有充分的理解和心理准备,还记得我们的互联网其根基是什么吗?是“基于统计复用的分组交换网络”!注意,其核心是统计复用!在“统计复用”这四个铿锵有力的字背后,是一个完全自组织的分层分布式系统,有自治域,有路由域,有运营商,就像世界贸易网一样,你永远不要试图预测政策是什么,因为根本就没有政策!在以上理解的基础上,我来试图回答几个问题。
1.我怎么就能确定Scapy的sendp发送的数据包一定就能顺利通过网络到达Host1?
首先我有预期,Server1到达Host1的单向路径是连通的!虽然我预感到的故障点并不正确...
事实上即便路径是通的,我并不能保证单向数据包能顺利到达,但幸运的是,它确实到达了!
要知道,如果中间的路由器启用了反向路由检查,比如Linux的rp_filter(中间链路几乎不可能用Linux!)或者Cisco的VRF(虚拟路由转发)检查,那么Server1到达Host1的数据包在前10跳(参见前面的traceroute)是会被丢弃的,因为反向路由检查会失败!但是据我所知道的事实是,为了转发效率,同一个小域甚至同一个运营商,转发设备并不会启用这个检查!这种检查更多的是基于安全的考虑,然而安全并不是骨干网的考虑范畴,安全问题应该被限制在最后一公里这个接入层或者网络边缘的位置!
这里有一个故事,闲暇时我想扫描一个防火墙后面的机器,只能使用Idle scan,我需要一台僵尸机,然而我并没有时间(或者能力)快速找到一台僵尸机,于是我求助于万能的温州皮鞋厂老板(yk),当温州皮鞋厂老板为我提供了一台日本的机器1.16.22.56并且我执行了以下命令执行扫描1.2.3.4时:
nmap -sI 1.16.22.56 -Pn -p100-250,1000 -r --packet-trace -v 1.2.3.4
令人遗憾的返回了以下信息:
Even though your Zombie (1.16.22.56; 1.16.22.56【注:IP为化名】) appears to be vulnerable to IP ID sequence prediction (class: Incremental), our attempts have failed. This generally means that either the Zombie uses a separate IP ID base for each host (like Solaris), or because you cannot spoof IP packets (perhaps your ISP has enabled egress filtering to prevent IP spoofing), or maybe the target network recognizes the packet source as bogus and drops them
QUITTING!
如果我知道调查的IP地址之间是跨AS的,我几乎可以肯定本文中的方法会失败,因为运营商,省,BGP之间肯定会经过骨干网的多个层次,逃过检查几乎是不可能的,如果真的是这个场景,我要怎么做呢?很遗憾,场景不能假设,不过可以肯定的是,办法是一定有的,至于为什么我的回答如此肯定,还是那个原因,网络上没有政策!
2.我怎么能保证ICMP不会被中间路由器禁用?
我无法保证!
但是理由和问题1一样,我相信除了边缘节点,中间节点几乎不会禁用ICMP,它们顶多是对ICMP限速,但绝对不会禁用!理由是,ICMP是分布式骨干网调试的唯一非标准的标准!不然在出了问题之后,运营商之间,AS之间,够他们喝一壶了!如果他们在其他方面无法达成一致,那就必须遵循和支持ICMP,虽然没有人强迫他们必须这样!
这是什么造成的?这是没有中央控制造成的!这也是网络比较好玩的地方,正如凯文.凯利在《失控》里说的那样。这可比按照需求搞评审,然后概要设计,详细设计进而写代码有意思多了!
3.为什么traceroute的中间设备无法被Idle scan?
这实际上是我自己给自己提出的问题!因为我的本职工作就是个程序员!按照上述的traceroute不通的第一个节点,即172.16.10.1,如果我在Server1上执行:
sendp(Ether()/IP(src='192.168.2.200', dst='172.16.10.1')/ICMP(), iface='eth0')对于程序员而言,这是令人费解的,毕竟从主机的角度来讲,172.16.10.1和Host1没有任何区别!然而区别恰恰就在于,172.16.10.1是个路由器,而Host1是个主机,一般而言路由器对于终到站流量会执行严格的检查而对于过境流量则会轻松放过!对于此,我说再多可能也没用,不过你可以想一下坐火车的情景。
我从哈尔滨坐火车到新乡去看女朋友(也就是小小的妈!),我没有发现有人在每一个站点去检查每一个人的车票(偶尔会查,但只是在刚从始发站开车时查或者中间站查新上来的),火车只是“愚蠢”的运送每一个人经过一站又一站,这种检查总是在终到站出站的时候进行!所以逃票的技巧往往在终到站的地方发挥,比如你知道下了车之后,从哪个缺口可以出站等等...但是...
但是唯独有一次,我没有买票坐车,跟列车员说我到安阳,上车补票,然后在中间站点新乡查票时被抓到...我本以为我已经理解了所有网络运作的原理,然而我错了,当列车快到达新乡站的时候,有人来查票,他们问我要到哪里,我说安阳,他们让我要么补票,要么下车,很显然我被赶下了车,我的女朋友(还是那个小小的妈!)在新乡!事实上,我本来的目的地就是新乡,哈哈,我再次赢了!有备才能无患,Trick是你要想办法
成功利用所有你能想到“他们要针对你要做的一切”去达到自己的目的,这就是网络工程师的法则!当然这些,与程序员无关。
PS:我平日里非常鄙视上述我那种小聪明行为,因此并不提倡!然而,必须告诉大家的时,这就是网络上天天都在发生的事情。
所以说,查票是正常的行为,随时会发生,但你永远不能预测什么时候会发生,对于路由器,也是一样!千万不要试图用你的理论知识和那肤浅的认知去试图解释网络的行为,这也是为什么我对那些所谓的关于TCP拥塞控制算法的各种论文不屑一顾的原因吧,毕竟学院派的东西,我喜欢的是那种工程界靠工匠精神打磨出来的真实的东西!
4.难道我忘了什么是DMZ了吗
我不知道我在说什么?估计是伪装成一个系统管理员在网管和程序员面前装逼,这是一种严重的令人心碎的人格分裂表现!但坦率的讲,DMZ的机器行为真的会比较怪异!如果你碰到了,它们可能会展现成一台老老实实的主机,也可能伪装成一台路由器,更可能对你展现成一个Blackhole!能搞定它们的是扫描和渗透要做的事,而不是抓包!当然,对于这一点,我站在网管的立场上讲,和程序员无关!
程序员的压力
这一次,我站在程序员的立场上,与网管无关!知道为什么在本文所述的作为网管的我排错过程中,为什么如此简单的一个携带非本机source的ping操作大多数程序想不到呢?因为他们总是在动手之前试图把把每件事都确定,遗憾的是,网络本身就是不确定的...
这种确定性要求其实并不是程序员自身的,而是用户带给程序员的。用户的接口是程序员而不是网管,网管可以跟程序员解释网络多么多么复杂且不可控,程序员可以快速理解网管的意图,然而用户可不管这些,比如他们要求,访问必须快,不能慢!他们根本不管什么3G,4G,根本不管什么光纤为铲车所断之类的事情,不管发生什么,访问必须快,不能慢!这是程序员的压力,也是造成很多程序员效率低下的原因,程序员可以理解网管模糊解释蝴蝶效应,然而用户或者说经理却不能理解程序员的模糊解释,这就是原因。这对程序员是不公平的。
试想,如果一个程序员试图要求网管提供精确的解决方案会如何,答案是他们马上就拍桌子了,并且要不是还记得自己是一个有知识的人一定会骂你傻逼,但我敢确定他们心里一定会骂傻逼!我就作为程序员向一个CCIE提过这样的需求,结果就被人家拍桌子,当时差点拍回去,仔细一想工作来之不易,还是用别的方式。后来,我是用自己工作上认真,肯钻研,出问题一定搞定方可罢休才搞定他,也算成了朋友(他们是甲方,我们是乙方)。
你不能奢求每一个用户都理解网络的蝴蝶效应,所以程序员的这部分压力就是固有的,且不可开拔的!程序员还有另一种压力,即解决自己程序bug的压力(我就不谈上线deadline的压力了,那不叫压力,并且有人乐在其中),本来这种压力应该很小,然而悲哀的是,和第一种压力混杂起来往往就压力巨大了!
这,对程序员而言,是不公平的。数据的入口就是程序,然后才进入网络,而程序的作者是程序员!要知道,程序员要承担多少重担啊!