Yolov5训练过程
Yolov5-v3.0训练过程
文章目录
- ***Yolov5-v3.0训练过程***
-
- 一、资源下载
- 二、环境配置
- 三、准备自己的数据集(VOC格式)
-
- 1.利用train_val.py文件生成test.txt train.txt trainval.txt val.txt
- 2.利用voc_label.py文件将xml文件转换为txt文件
- 3.配置文件
-
- (1)创建ab.yaml文件
- (2)修改yolov5s.yaml文件
- 四、训练模型
-
- 1.修改train.py
- 2.模型训练
-
- (1)先激活自己的环境
- (2)开始训练
- (3)过程可视化
- 3.模型测试
-
- (1)图片测试
- (2)摄像头测试
- (3)视频测试
一、资源下载
Yolov5分为多个版本,这里用到的是yolov5的v3.0版本。注意,不同版本所需要的版本号也不同,具体可以看requiremets.txt。官方下载地址:https://github.com/ultralytics/yolov5.git
资源分享下载链接:
源代码链接:https://pan.baidu.com/s/1K_OmHSirEblGPPZtQvOTLg 提取码:j2rh
yolov5s.pt链接:https://pan.baidu.com/s/12Jg8Ca4T9kEg7nhJEujSFQ 提取码:yfj5
yolov5m.pt链接:https://pan.baidu.com/s/1iyXuUee24Junhy624l5MHA 提取码:k6j9
如需yolov5x.pt和yolovl.pt可自行到github上下载(注意权重文件一定要下载对应3.0版本的!)。
二、环境配置
CUDA:10.1 or 10.2(本文选用10.2)
Pytorch:1.6.0
torchvision:0.7.0
Pytorch下的Python:3.7
Pycharm:如何将项目移植到Pycharm中可参考我的另外一篇文章:如何在Pycharm中复现别人pytorch的项目实例_carrymingteng的博客-CSDN博客
其他所需的包可在cmd中进入到自己的Pytorch环境中,用pip install -r requirements.txt安装。当然可能有些依赖包会出现安装不成功,这里建议可以借助Pycharm进行安装,或者自行下载安装包进行安装。
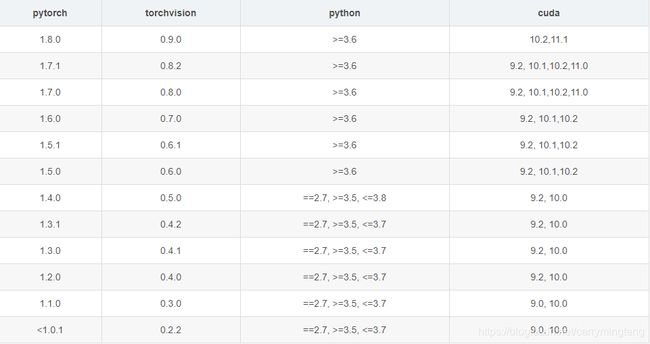
注意:官方给出的环境配置要求为CUDA>=10.1,但实际操作如果CUDA版本过高会出现无法运用GPU的问题。具体版本对应关系可参见下图。
三、准备自己的数据集(VOC格式)
1.利用train_val.py文件生成test.txt train.txt trainval.txt val.txt
进入到yolov5文件夹下,创建paper_data文件夹,目录结构如下图。
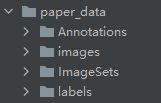
–Annotations 存放xml文件
–images 存放jpg格式图片
–ImageSets/Main 在ImageSets下创建Main文件夹用于存放利用train_val.py文件生成的四个txt文件。train_val.py文件存放在paper_data文件夹下,代码如下:
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
运行train_val.py文件后,会在ImageSets/Main下生成test.txt train.txt trainval.txt val.txt
2.利用voc_label.py文件将xml文件转换为txt文件
在paper_data文件夹下创建labels文件夹,用于存放转化后的txt文件。将voc_label.py文件存放在yolov5大文件夹下,即yolov5/voc_label.py。代码如下:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["person"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
"""以下路径为winows下的格式,可自行修改为自己的文件路径"""
in_file = open('D:\pycharm\PycharmProject\yolov5-3.0/paper_data/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('D:\pycharm\PycharmProject\yolov5-3.0/paper_data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
"""如果xml文件中为Difficult对应注释掉第一句,使用第二句"""
difficult = obj.find('difficult').text
#difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('D:\pycharm\PycharmProject\yolov5-3.0/paper_data/labels/'):
os.makedirs('D:\pycharm\PycharmProject\yolov5-3.0/paper_data/labels/')
image_ids = open('D:\pycharm\PycharmProject\yolov5-3.0/paper_data/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('paper_data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/paper_data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
运行后会在paper_data/labels中生成转换后的txt文件,以及在paper_data下生成test.txt train.txt val.txt
3.配置文件
(1)创建ab.yaml文件
yolov5/data下创建ab.yaml文件,用来存放train.txt和val.txt文件。ab.yaml内容如下:
train: D:\pycharm\PycharmProject\yolov5-3.0\paper_data\train.txt
val: D:\pycharm\PycharmProject\yolov5-3.0\paper_data\val.txt
# number of classes
nc: 1
# class names
names: ['person']
其中nc对应的你数据集中所要检测的种类数,names对应种类名称。
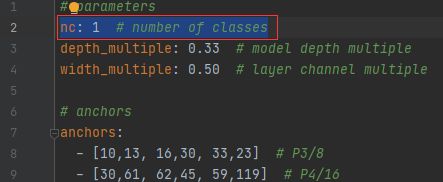
(2)修改yolov5s.yaml文件
注意:如果你训练的不是yolov5s模型,对应修改对应的yaml文件。修改如下:与ab.yaml中的nc数对应
四、训练模型
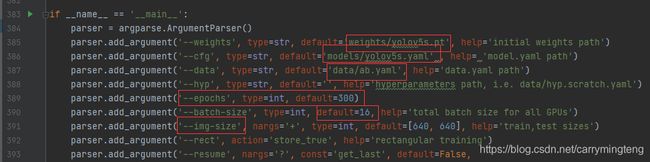
1.修改train.py
2.模型训练
在Pycharm的底端,我们可以看到Terminal,点击后可以以命令窗模式运行。
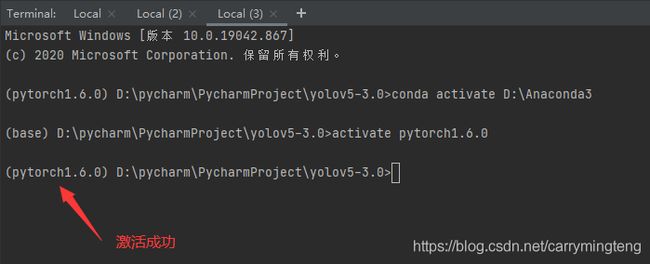
(1)先激活自己的环境
举例我是如何在Terminnal下激活我自己的Pytorch1.6.0的环境
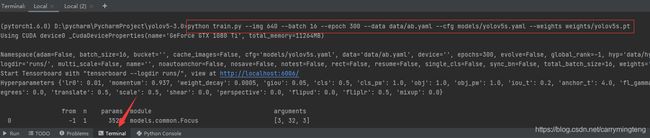
(2)开始训练
键入图片中标注的指令开始训练
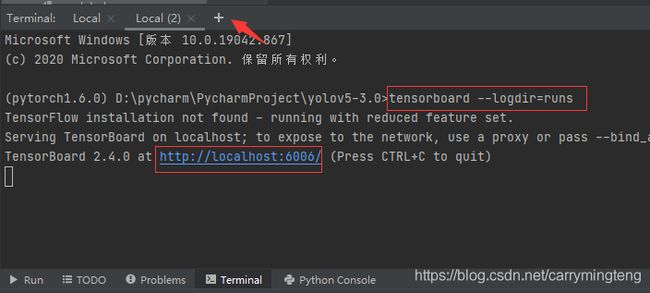
(3)过程可视化
点加号开启另一个命令窗,在新的命令窗键入如下:点击那个网址即可查看到
3.模型测试
(1)图片测试
训练好的模型一般存放在runs/exp/weights下
单张图片测试指令
python detect.py --weights runs/exp26/weights/best.pt --source data/images/1.jpg
多张图片测试指令(将图片统一放到一个文件夹下)
python detect.py --weights runs/exp26/weights/best.pt --source data/images/
测试结果可在inference/output下查看
(2)摄像头测试
指令如下:
python detect.py --weights runs/exp26/weights/best.pt --source 0
(3)视频测试
指令如下:
python detect.py --weights runs/exp26/weights/best.pt --source inference/images/1.mp4
参考链接:https://blog.csdn.net/qq_36756866/article/details/109111065?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161771077216780266255946%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=161771077216780266255946&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_v2~rank_v29-1-109111065.first_rank_v2_pc_rank_v29&utm_term=%E7%94%A8VOC%E6%A0%BC%E5%BC%8F%E6%95%B0%E6%8D%AE%E9%9B%86%E8%AE%AD%E7%BB%83yolov5+v3.0