浅尝Pytorch自动混合精度AMP
AMP目录
- 浅尝Pytorch自动混合精度
-
- 从浮点数说起
- 深度学习中的浮点数
-
- 例1-上溢
- 例2-下溢
- 解决了什么问题?
- Pytorch相关功能简述
- Autocasting
-
- Autocasting作上下文管理器
- Autocasting作装饰器
- 数据类型转换
- 局部禁用autocast
- 多GPU情况
- 其他辅助装饰器
- 梯度缩放
- AMP示例
-
- 典型混合精度训练
- 使用未缩放的梯度
-
- 梯度缩放
- 使用缩放后的梯度
-
- 梯度累积
- 梯度惩罚
- 多个模型、Losses以及优化器的情况
- 参考
浅尝Pytorch自动混合精度
本文是《AUTOMATIC MIXED PRECISION PACKAGE - TORCH.CUDA.AMP》一文的简单学习,所以有些语句有些翻译腔还请各位谅解。本文主要内容为Pytorch的混合精度功能。
先说个题外话,以前我训练模型的时候,尝鲜AMP都是用的Nvidia开源的 APEX 包,这个包里面有个混合精度(AMP)功能,当时堪称训练神器~
关于这个包的故事就不多说了,后来Facebook官方将这个好用的AMP功能加到Pytorch里面去了,成为了原生功能。今天我正好学习一下这个神奇的功能是怎么使用的。
从浮点数说起
说起浮点数,大家肯定很熟悉,我们编程过程中最常用的数据类型之一就是浮点数了,英文名 Float。一般而言我们用浮点数来表示一个小数,比如 0.4。
在Python里面我们直接赋值
In[1] n = 0.4
In[2] print(type(n))
<class 'float'>
实际上,0.4 在二进制上是一个无限循环的数字:0.0110 0110 0110 0110 …
换句话说,0.4 的二进制表示为 0.4 = 0 × 2 − 1 + 1 × 2 − 2 + 1 × 2 − 3 + 0 × 2 − 4 ⋯ 0.4=0\times2^{-1}+1\times2^{-2}+1\times2^{-3}+0\times2^{-4}\cdots 0.4=0×2−1+1×2−2+1×2−3+0×2−4⋯这是一个无穷级数,越往后我们对0.4的表示就越精确。
后来,IEEE制定了 IEEE 754 标准,规定了浮点数的表示方法。这里我们不深究这个标准的制定规则。就简单拿0.4举个例子,如果我们规定它是一个32位浮点数,那么一般来说它会占用4个字节。根据 IEEE 754 标准,这32位如下图:
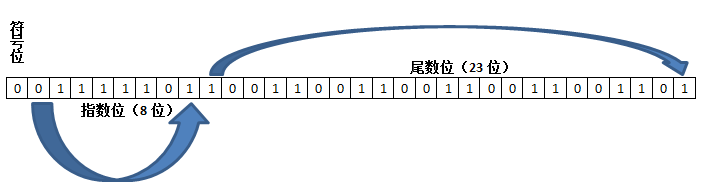
它由三部分组成:

符号位:(第31位)值为0,说明是正数。
指数位:(第 30-23位)01111101
这里指数是-2+127,其中127是偏移量,至于为啥可以看这里。
尾数:(第22-0位)10011001100110011001101
0.4 的二进制是
0.0110 0110 0110 0110 0110 0110 0110 0110 …
根据IEEE 754,首先移动小数点(向左或向右),保证整数部分只有一位非零的1(浮点的来历,对0.4就是小数点向右移动两位):1.100110011001100110011001100110 …
- 因为移动了两位,所以指数就是-2
- 尾数就是取小数点后面23位。
这里我们称这个32位的浮点数为单精度浮点数。同理还有一种double数据类型,就是截取了更长的小数到64位,也就是传说中的双精度浮点数~
以此类推,如果是半精度浮点数,就是16位,也是本文后面的主角之一。
深度学习中的浮点数
现在我们会简单比较一下 FP32 和 FP16 :

很明显 float32 的能表示的数字范围远大于 float16 ,但是 float16 也有其优点。在NVIDIA官方基于 V100 的测试里,在 Tensor Core 运算中:
float16计算吞吐量是float32的8倍float16内存吞吐量是float32的2倍float16只占用一半显存
这就是我们为啥想使用FP16,主要是因为穷。当然我们也不能无脑使用半精度,我们以下面两个例子来说明。
例1-上溢
我们现在进一步比较一下两者区别:
a = torch.cuda.HalfTensor(4096)
a.fill_(16.0)
print(a.sum())
b = torch.cuda.FloatTensor(4096)
b.fill_(16.0)
print(b.sum())
这段代码的作用是创造两个长度为4096的张量,唯一的区别就是前者是半精度张量而后者是单精度张量。
结果,半精度张量的a,其 sum 结果为 inf,而单精度张量的b,其 sum 结果为tensor(65536, device='cuda') 。这个例子说明了其最大动态范围的区别。
例2-下溢
param = torch.cuda.HalfTensor([1.0])
update = torch.cuda.HalfTensor([.0001])
print(param + update)
param = torch.cuda.FloatTensor([1.0])
update = torch.cuda.FloatTensor([.0001])
print(param + update)
这段代码的前半截返回的结果是
tensor([1.], device='cuda:0', dtype=torch.float16)
而后半截返回的结果是
tensor([1.0001], device='cuda:0')
同样说明了半精度和单精度之间的不同。换句话说,如果在某些梯度更新运算中,梯度极其小的情况下,采用半精度来更新梯度有可能导致梯度并没有任何变化。
解决了什么问题?
OK在前面叭叭半天两种精度的区别,我们现在面临的问题在于啥时候用单精度啥时候用半精度呢?这时候就到了AMP出场了。
AMP解决了什么问题?这里不想赘述太多了,网上随便搜一下就有很多相关的解释和来龙去脉说明。简而言之,如果你的神经网络代码采用了AMP,可以加快运算 并且 减少显存占用。换句话说,可以节约时间,可以用更大的batch_size,可以节省带宽…
但是本文又不只是AMP,还涉及到了 梯度缩放(Gradient Scaling) 和 梯度剪裁(Gradent Clipping) 等概念。
通俗易懂地过一下这几个概念。就是平时我们在Pytorch里面创建的tensor,默认是 float32 的,然后我们启用了AMP功能以后,在某些局部运算中会自动变成 float16 以节省空间和时间。但是这样砍掉一半精度进行运算,可能会出问题。
啥问题呢?比如有这么一个浮点数,特别接近于0,可能要用 float32 的精度才能表现出来这是一个非0的数字。但是一旦它变成 float16 ,这么四舍五入一下就成了 0 了!这就是一种梯度消失的情况,我觉得你可能听说过这个词。
现在既然知道梯度消失的原因,我们就可以采用刚刚提到过的梯度剪裁的方法来解决问题。这个方法简单粗暴,比如我规定小于某个特定阈值的梯度,都强制设置为一个非零的极小值,防止梯度消失。
Pytorch相关功能简述
torch.cuda.amp 提供了一种方便的混合精度方法,简单说来就是在一些运算中 torch.float32(float) 数据类型,而另一些运算中使用torch.float16(half) 。在部分运算,如线性层(linear layers)和卷积(convolutions)中,使用float16 要快得多。而其他运算,如归约(reduction),往往需要 float32 这样动态范围。而混合精度(MP)就是用来尝试将各种运算操作与其最合适的数据类型相匹配。
如自动混合精度示例(AMP Examples)和自动混合精度小窍门(AMP Recipe)所示,通常“自动混合精度训练”会同时使用 torch.cuda.amp.autocast 和torch.cuda.amp.GradScaler。但是,autocast 和 GradScaler 是模块化的,如果有需要,也可以单独使用。
Autocasting
CLASS
torch.cuda.amp.autocast(enabled=True)
autocast这个实例可以作为上下文管理器或装饰器,能让你的脚本中特定区域以混合精度运行。
不知道啥是“上下文管理器”和“装饰器”的赶紧搜一下。
在这些区域中,CUDA运算会以autocast选择的特定数据类型运行,提高性能的同时还能保持准确性。具体可以参阅Autocast Op Reference。
这个链接里面详细叙述了哪些运算会autocast到
float16而哪些运算会变成float32,而且记住只有CUDA运算才可以使用此功能。
另外要注意的是,float64或者非浮点类型的数据都不适用于autocast,虽然你用了也不会报错。
当进入启用了autocast的代码区域时,Tensors可以是任何类型。当你使用autocast时,不要对模型或输入调用.half()。
Autocasting作上下文管理器
autocast应该只wrap网络的前向传播和loss计算。不建议autocast带上反向传播,反向传播的运行类型会与autocast用于相应前向传播的类型相同的。也就是说反向传播loss.backward()这块不用我们去操心了,具体可以看下面的代码加深理解。
例:
# 在默认精度下创建模型和优化器
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
for input, target in data:
optimizer.zero_grad()
# 启用 autocasting ,作用于前向传播 (model + loss)
# 注意这里采用的是上下文管理器 + autocast
with autocast():
output = model(input)
loss = loss_fn(output, target)
# 在 backward() 之前退出上下文管理器
loss.backward()
optimizer.step()
在自动混合精度示例中我们还可以了解在更复杂场景中(梯度惩罚(gradient penalty)、多模型/损失、自定义autograd函数)中的用法。
Autocasting作装饰器
autocast也可用作装饰器。例如,在模型的forward上:
class AutocastModel(nn.Module):
...
@autocast()
def forward(self, input):
...
数据类型转换
在启用autocast区域中生成的浮点Tensors可以是float16。而返回禁用autocase的区域后(也就是上面例子中@autocast()或者with autocast()之外的地方,比如反向传播那块),这些float16数据与其他类型的浮点Tensors一起使用,就可能会出现类型不匹配的错误。如果是这样,我们可以将autocast区域中生成的Tensor(s)转换回 float32(或float64等其他数据类型,具体看情况)。如果来自autocast区域的Tensor已经是 float32,则强制转换是no-op的,不会产生额外的开销。
例:
# 创建一些默认数据类型的Tensors (这里当成是 float32)
a_float32 = torch.rand((8, 8), device="cuda")
b_float32 = torch.rand((8, 8), device="cuda")
c_float32 = torch.rand((8, 8), device="cuda")
d_float32 = torch.rand((8, 8), device="cuda")
with autocast():
# torch.mm is on autocast's list of ops that should run in float16.
# Inputs are float32, but the op runs in float16 and produces float16 output.
# No manual casts are required.
e_float16 = torch.mm(a_float32, b_float32)
# Also handles mixed input types
f_float16 = torch.mm(d_float32, e_float16)
# After exiting autocast, calls f_float16.float() to use with d_float32
g_float32 = torch.mm(d_float32, f_float16.float())
启用了autocast的区域中出现了“类型不匹配错误(Type mismatch errors)”是出BUG了;如果你遇到了这种情况,那请提交一个issue。
局部禁用autocast
autocast(enabled=False) 子区域可以嵌入在启用了autocast的区域中。局部禁用autocast有时候很有用,例如你要强制某个子区域以特定的 dtype 运行。禁用autocast可以让你显式控制执行类型。在这些子区域中,来自周围区域的输入记得在使用前就转换为相应dtype:
# 创建一些默认数据类型的Tensors (这里当成是 float32)
a_float32 = torch.rand((8, 8), device="cuda")
b_float32 = torch.rand((8, 8), device="cuda")
c_float32 = torch.rand((8, 8), device="cuda")
d_float32 = torch.rand((8, 8), device="cuda")
with autocast():
e_float16 = torch.mm(a_float32, b_float32)
with autocast(enabled=False):
# Calls e_float16.float() to ensure float32 execution
# (necessary because e_float16 was created in an autocasted region)
f_float32 = torch.mm(c_float32, e_float16.float())
# No manual casts are required when re-entering the autocast-enabled region.
# torch.mm again runs in float16 and produces float16 output, regardless of input types.
g_float16 = torch.mm(d_float32, f_float32)
多GPU情况
autocast state是thread-local的。所以如果你希望在一个新线程中启用autocast,则必须在该线程中调用上下文管理器或装饰器。当每个进程与多个GPU一起使用时,会影响到torch.nn.DataParallel和torch.nn.parallel.DistributedDataParallel(具体可以参阅Working with Multiple GPUs)。
其他辅助装饰器
torch.cuda.amp.custom_fwd(fwd=None, **kwargs)
用于自定义autograd函数(torch.autograd.Function的子类)中 forward 方法的辅助装饰器(helper decorator)。有关更多详细信息,请参见示例页。
torch.cuda.amp.custom_bwd(bwd)
用于自定义autograd函数(torch.autograd.Function的子类)中后向方法的辅助装饰器。确保backward执行时,与forward处于相同autocast状态。有关更多详细信息,请参见示例页。
梯度缩放
先举个例子,如果某个特定操作的前向传播中有 float16 的输入,那么其反向传播会产生一个 float16 的梯度。有些很小幅度的梯度值可能无法用float16表示。结果这些值将刷新为零(称为“ 下溢(underflow) ”),因此相应参数的更新也就没了。
啥叫 梯度缩放(gradient scaling) 呢?刚刚提到了下溢情况,那么为了防止这种情况,“梯度缩放”会将网络的loss(es)乘以缩放因子,并基于缩放后的loss(es)调用反向传播。然后,梯度通过网络向后流动,这些梯度也按相同的因子进行了缩放。换句话说,梯度值具有更大的幅值,因此它们不会变成零。
在优化器更新参数前,每个参数的梯度(.grad 属性)应当是 未缩放(unscaled) 的,因此缩放因子不会影响到学习率。
CLASS
torch.cuda.amp.GradScaler(init_scale=65536.0, growth_factor=2.0, backoff_factor=0.5, growth_interval=2000, enabled=True)
其实在文档原文后面大多是一些方法函数的解释,并没有过多说明这个 torch.cuda.amp.GradScaler() 的用法。不过我们可以在示例页给出的例子中加深理解。
AMP示例
一般说来,“AMP Training”指的是同时采用 torch.cuda.amp.autocast 和 torch.cuda.amp.GradScaler 进行训练。关于这两个模块在上文已经全部过了一遍了,不过在这一节还会再用一些代码片段加深印象。这一节的代码和相关解释主要出自AUTOMATIC MIXED PRECISION EXAMPLES,也就是前文所说的示例页。
典型混合精度训练
# 在默认精度下创建模型和优化器
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
# 在训练的一开始创建一个 GradScaler
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
# 带 autocasting 的前向传播
with autocast():
output = model(input)
loss = loss_fn(output, target)
# Scales loss. Calls backward() on scaled loss to create scaled gradients.
# 不推荐在autocast作用区域内进行反向传播
# Backward ops run in the same dtype autocast chose for corresponding forward ops.
scaler.scale(loss).backward()
# scaler.step() 首先会 unscale 优化器指定参数的梯度。
# 如果这些梯度中没有 inf 或者 NaN,那么调用 optimizer.step()
# 否则跳过 optimizer.step()
scaler.step(optimizer)
# Updates the scale for next iteration.
scaler.update()
其实这块代码已经很清楚明白了,感觉直接照抄就没啥问题。
使用未缩放的梯度
使用 scaler.scale(loss).backward() 生成的所有梯度都被缩放了。如果你想要修改或检查一下 backward() 和 scaler.step(optimizer) 之间众多参数的 .grad 属性,就得先取消对它们的缩放。
举个例子, 梯度剪裁(gradient clipping) 会操纵一组梯度,使其全局范数(global norm)(参见torch.nn.utils.clip_grad_norm_())或 最大幅值(maximum magnitude)(参见torch.nn.utils.clip_grad_value_() 小于等于用户自己设置的某个阈值。
如果你想要在 不取消 缩放的情况下进行剪裁,梯度的范数/最大幅值也会被缩放,因此你请求的阈值(即未缩放梯度的阈值)是无效的。
Gradient clipping:梯度剪裁,有的人也称之为梯度裁剪或者梯度截断。
scaler.unscale_(optimizer) 会将由 optimizer 保存的指定参数的梯度给 unscale 掉。如果你的模型包含指定给另一个优化器(例如 optimizer2)的其他参数,则可以单独调用 scaler.unscale_(optimizer2) 来取消这些参数的梯度缩放。
梯度缩放
在剪裁之前调用 scaler.unscale_(optimizer),能让你像平时一样剪裁未缩放的梯度:
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
with autocast():
output = model(input)
loss = loss_fn(output, target)
scaler.scale(loss).backward()
# Unscales the gradients of optimizer's assigned params in-place
scaler.unscale_(optimizer)
# Since the gradients of optimizer's assigned params are unscaled, clips as usual:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
# optimizer's gradients are already unscaled, so scaler.step does not unscale them,
# although it still skips optimizer.step() if the gradients contain infs or NaNs.
scaler.step(optimizer)
# Updates the scale for next iteration.
scaler.update()
在这个迭代中,scaler 记录了已经为此优化器调用了 scaler.unscale(optimizer),因此 scaler.step(optimizer) 知道在(内部)调用优化器 .step() 之前不用多此一举地取消梯度缩放。
- 警告⚠️
unscale_只应在每个优化器的每个step中调用一次,并且只有在该优化器的指定参数的所有梯度都已累积之后。如果在每个step之间为给定优化器调用unscale_两次,会触发 RuntimeError。
使用缩放后的梯度
梯度累积
梯度累积(Gradient accumulation) 会在一个 size 为 batch_per_iter * iters_to_accumulate (* num_procs if distributed)
的有效 batch 上累加梯度。
之前说的 scale 应该针对有效batch进行校准,换句话说你需要检查里面是不是有 inf / NaN,如果找到 inf / NaN 梯度,则跳过这个 step,记住 scale updates 应该在有效 batch 的粒度下进行。
此外,给定的有效 batch 的梯度照常累积的同时,梯度应保持缩放后的状态,缩放因子也应保持不变。
如果梯度在累积完成之前被取消缩放(unscaled)(或缩放因子发生变化),则下一次反向传播将用缩放后的梯度去和未缩放(或者是按不同因子缩放)的梯度相加,之后就没法正确提供给 step 必须要用到的,未缩放的梯度累积。
因此,如果你要 unscale_ 梯度(比如允许剪裁未缩放的梯度),请在即将开始的步骤的所有(缩放的)梯度累积之后,在 step 之前调用 unscale_ 。
另外记住,只有在迭代(iterations)结束时才调用 update,同时为了一个完整的有效 batch 调用 step ,参考代码如下:
scaler = GradScaler()
for epoch in epochs:
for i, (input, target) in enumerate(data):
with autocast():
output = model(input)
loss = loss_fn(output, target)
loss = loss / iters_to_accumulate
# 累积缩放后的梯度
scaler.scale(loss).backward()
if (i + 1) % iters_to_accumulate == 0:
# may unscale_ here if desired (e.g., to allow clipping unscaled gradients)
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
梯度惩罚
梯度惩罚的实现通常使用 torch.autograd.grad() 创建梯度,然后将它们组合起来创建惩罚值(penalty value),并将惩罚值添加到 loss 中。
下面是一个普通 L2 惩罚示例,不带梯度缩放或 autocasting:
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
# 创建梯度
grad_params = torch.autograd.grad(outputs=loss,
inputs=model.parameters(),
create_graph=True)
# Computes the penalty term and adds it to the loss
grad_norm = 0
for grad in grad_params:
grad_norm += grad.pow(2).sum()
grad_norm = grad_norm.sqrt()
loss = loss + grad_norm
loss.backward()
# clip gradients here, if desired
optimizer.step()
为了使用梯度缩放来实现梯度惩罚,传递给 torch.autograd.grad() 的 outputs 的 Tensor(s) 也应该是被缩放后的。 所以呢,我们生成的梯度也是缩放后的,再然后,在合并并且生成惩罚值之前,我们需要将其取消缩放。
此外,惩罚项的计算是前向传播的一部分,因此它应该在autocast 上下文中。
下面的例子依然是L2惩罚,不过采用了梯度缩放,可以配合注释理解,注意这里使用了一个上下文管理器:
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
with autocast():
output = model(input)
loss = loss_fn(output, target)
# 为了 autograd.grad 的反向传播而放缩 loss,
# 结果存入 scaled_grad_params.
scaled_grad_params = torch.autograd.grad(outputs=scaler.scale(loss),
inputs=model.parameters(),
create_graph=True)
# 在计算惩罚之前取消对 grad_param 的放缩.
# scaled_grad_params 不属于任何一个优化器,所以这里使用普通除法,
# 而不是使用 scaler.unscale_
inv_scale = 1./scaler.get_scale()
grad_params = [p * inv_scale for p in scaled_grad_params]
# Computes the penalty term and adds it to the loss
with autocast():
grad_norm = 0
for grad in grad_params:
grad_norm += grad.pow(2).sum()
grad_norm = grad_norm.sqrt()
loss = loss + grad_norm
# Applies scaling to the backward call as usual.
# Accumulates leaf gradients that are correctly scaled.
scaler.scale(loss).backward()
# may unscale_ here if desired (e.g., to allow clipping unscaled gradients)
# step() and update() proceed as usual.
scaler.step(optimizer)
scaler.update()
多个模型、Losses以及优化器的情况
如果你的模型有多个loss,就得为每个loss分别调用 scaler.scale。
如果你的模型有多种优化器,可能你就得为他们中的任意一个优化器调用scaler.unscale_,然后还得分别为他们调用
scaler.step。
不过,scaler.update 只应该被调用一次,一般在所有的优化器在本迭代中都 step 完事以后。具体可以参考下面的例子,注意 scaler.update 的位置:
scaler = torch.cuda.amp.GradScaler()
for epoch in epochs:
for input, target in data:
optimizer0.zero_grad()
optimizer1.zero_grad()
with autocast():
output0 = model0(input)
output1 = model1(input)
loss0 = loss_fn(2 * output0 + 3 * output1, target)
loss1 = loss_fn(3 * output0 - 5 * output1, target)
# (这里的 retain_graph 和 amp 没啥关系,它出现在这里是因为在本例子中
# 俩 backward() 的调用共享了同一个计算图
# 多说一句,一般双 loss 就会采用 retain_graph=True
# example, both backward() calls share some sections of graph.)
scaler.scale(loss0).backward(retain_graph=True)
scaler.scale(loss1).backward()
# You can choose which optimizers receive explicit unscaling, if you
# want to inspect or modify the gradients of the params they own.
scaler.unscale_(optimizer0)
scaler.step(optimizer0)
scaler.step(optimizer1)
scaler.update()
参考
https://www.sohu.com/a/342131560_453160
https://www.bilibili.com/video/BV1Vt4y1Y7zp?from=search&seid=7197249994049089941