使用Pytorch简单实现混合密度网络(Mixture Density Network, MDN)
本文主要参考自:
https://github.com/sksq96/pytorch-mdn/blob/master/mdn.ipynb
https://blog.otoro.net/2015/11/24/mixture-density-networks-with-tensorflow/?tdsourcetag=s_pctim_aiomsg
引言
我们知道,神经网络具有很强的拟合能力。比方说,假设我们要拟合如下一个带噪声的函数: y = 7.0 sin ( 0.75 x ) + 0.5 x + ϵ y=7.0 \sin (0.75 x)+0.5 x+\epsilon y=7.0sin(0.75x)+0.5x+ϵ
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from torchsummary import summary
import numpy as np
import matplotlib.pyplot as plt
n_samples = 1000
epsilon = torch.randn(n_samples)
x_data = torch.linspace(-10, 10, n_samples)
y_data = 7*np.sin(0.75*x_data) + 0.5*x_data + epsilon
y_data, x_data = y_data.view(-1, 1), x_data.view(-1, 1)
plt.figure(figsize=(8, 8))
plt.scatter(x_data, y_data, alpha=0.4)
plt.show()
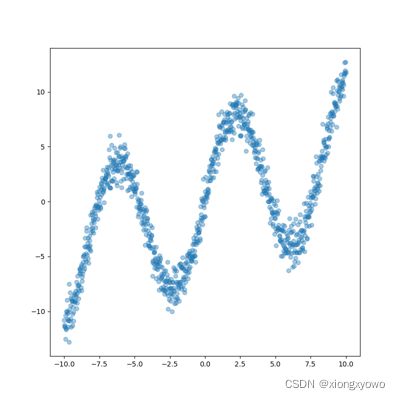
拟合这个显然是很容易的,随便构建一个由两个全连接层组成的网络就具有非线性的拟合能力:
n_input = 1
n_hidden = 20
n_output = 1
model = nn.Sequential(nn.Linear(n_input, n_hidden),
nn.Tanh(),
nn.Linear(n_hidden, n_output))
loss_fn = nn.MSELoss()
optimizer = torch.optim.RMSprop(model.parameters())
然后编写代码进行训练:
for epoch in range(3000):
y_pred = model(x_data)
loss = loss_fn(y_pred, y_data)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 1000 == 0:
print(loss.data.tolist())
x_test = torch.linspace(-15, 15, n_samples).view(-1, 1)
y_pred = model(x_test).data
plt.figure(figsize=(8, 8))
plt.scatter(x_data, y_data, alpha=0.4)
plt.scatter(x_test, y_pred, alpha=0.4, color='red')
plt.show()
结果如下:

可以看到,给定一个输入x,要求预测一个y的话,这种一对一的建模能力神经网络是很擅长的。但是实际工程中我们也很容易遇到这种情况,在这里,我们将x与y调换,模拟一对多的情形: x = 7.0 sin ( 0.75 y ) + 0.5 y + ε x=7.0 \sin (0.75 y)+0.5 y+\varepsilon x=7.0sin(0.75y)+0.5y+ε
y_data, x_data = x_data.view(-1, 1), y_data.view(-1, 1)
重新训练进行预测,结果如下:

可以看到网络在试图拟合同一x下各y的平均值。那么,有没有一种网络能够去拟合这种一对多的情况呢?
MDN
传统的神经网络:对于单一输入x,给出一个单一预测y
MDN:对于单一输入x,预测y的概率分布
具体来说,对于输入x,MDN的输出为服从混合高斯分布(Mixture Gaussian distributions),具体的输出值被建模为多个高斯随机值的和,这几个高斯分布的均值和标准差是不同的。形式化地,有: P ( Y = y ∣ X = x ) = ∑ k = 0 K − 1 Π k ( x ) ϕ ( y , μ k ( x ) , σ k ( x ) ) , ∑ k = 0 K − 1 Π k ( x ) = 1 P(Y=y \mid X=x)=\sum_{k=0}^{K-1} \Pi_{k}(x) \phi\left(y, \mu_{k}(x), \sigma_{k}(x)\right), \sum_{k=0}^{K-1} \Pi_{k}(x)=1 P(Y=y∣X=x)=k=0∑K−1Πk(x)ϕ(y,μk(x),σk(x)),k=0∑K−1Πk(x)=1 需要注意的是,这里各个高斯分布的参数 Π k ( x ) , μ k ( x ) , σ k ( x ) \Pi_{k}(x), \mu_{k}(x), \sigma_{k}(x) Πk(x),μk(x),σk(x)是取决于输入 x x x的,也就是要通过网络训练去预测得到。实际上,这依然可以通过全连接层来搞定,接下来我们去介绍怎么实现MDN。
实现
class MDN(nn.Module):
def __init__(self, n_hidden, n_gaussians):
super(MDN, self).__init__()
self.z_h = nn.Sequential(
nn.Linear(1, n_hidden),
nn.Tanh()
)
self.z_pi = nn.Linear(n_hidden, n_gaussians)
self.z_mu = nn.Linear(n_hidden, n_gaussians)
self.z_sigma = nn.Linear(n_hidden, n_gaussians)
def forward(self, x):
z_h = self.z_h(x)
pi = F.softmax(self.z_pi(z_h), -1)
mu = self.z_mu(z_h)
sigma = torch.exp(self.z_sigma(z_h))
return pi, mu, sigma
混个高斯分布由多少个子高斯分布构成属于超参数,这里我们设计为5个:
model = MDN(n_hidden=20, n_gaussians=5)
然后是损失函数的设计。由于输出本质上是概率分布,因此不能采用诸如L1损失、L2损失的硬损失函数。这里我们采用了对数似然损失(和交叉熵类似): CostFunction ( y ∣ x ) = − log [ ∑ k K Π k ( x ) ϕ ( y , μ ( x ) , σ ( x ) ) ] \operatorname{CostFunction}(y \mid x)=-\log \left[\sum_{k}^{K} \Pi_{k}(x) \phi(y, \mu(x), \sigma(x))\right] CostFunction(y∣x)=−log[k∑KΠk(x)ϕ(y,μ(x),σ(x))]
def mdn_loss_fn(y, mu, sigma, pi):
m = torch.distributions.Normal(loc=mu, scale=sigma)
loss = torch.exp(m.log_prob(y))
loss = torch.sum(loss * pi, dim=1)
loss = -torch.log(loss)
return torch.mean(loss)
接下来则是训练的过程:
for epoch in range(10000):
pi, mu, sigma = model(x_data)
loss = mdn_loss_fn(y_data, mu, sigma, pi)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 1000 == 0:
print(loss.data.tolist())
最后是推理的过程。需要注意的是,MDN学到的只是若干个高斯分布:
pi, mu, sigma = model(x_test)
因此我们还要手动去从高斯分布中采样获得具体的值:
k = torch.multinomial(pi, 1).view(-1)
y_pred = torch.normal(mu, sigma)[np.arange(n_samples), k].data
plt.figure(figsize=(8, 8))
plt.scatter(x_data, y_data, alpha=0.4)
plt.scatter(x_test, y_pred, alpha=0.4, color='red')
plt.show()
最后结果如下:

完整代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
n_samples = 1000
epsilon = torch.randn(n_samples)
x_data = torch.linspace(-10, 10, n_samples)
y_data = 7*np.sin(0.75*x_data) + 0.5*x_data + epsilon
# y_data, x_data = y_data.view(-1, 1), x_data.view(-1, 1),
y_data, x_data = x_data.view(-1, 1), y_data.view(-1, 1)
plt.figure(figsize=(8, 8))
plt.scatter(x_data, y_data, alpha=0.4)
plt.show()
n_input = 1
n_hidden = 20
n_output = 1
model = nn.Sequential(nn.Linear(n_input, n_hidden),
nn.Tanh(),
nn.Linear(n_hidden, n_output))
loss_fn = nn.MSELoss()
optimizer = torch.optim.RMSprop(model.parameters())
for epoch in range(3000):
y_pred = model(x_data)
loss = loss_fn(y_pred, y_data)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 1000 == 0:
print(loss.data.tolist())
x_test = torch.linspace(-15, 15, n_samples).view(-1, 1)
y_pred = model(x_test).data
plt.figure(figsize=(8, 8))
plt.scatter(x_data, y_data, alpha=0.4)
plt.scatter(x_test, y_pred, alpha=0.4, color='red')
plt.show()
class MDN(nn.Module):
def __init__(self, n_hidden, n_gaussians):
super(MDN, self).__init__()
self.z_h = nn.Sequential(
nn.Linear(1, n_hidden),
nn.Tanh()
)
self.z_pi = nn.Linear(n_hidden, n_gaussians)
self.z_mu = nn.Linear(n_hidden, n_gaussians)
self.z_sigma = nn.Linear(n_hidden, n_gaussians)
def forward(self, x):
z_h = self.z_h(x)
pi = F.softmax(self.z_pi(z_h), -1)
mu = self.z_mu(z_h)
sigma = torch.exp(self.z_sigma(z_h))
return pi, mu, sigma
model = MDN(n_hidden=20, n_gaussians=5)
optimizer = torch.optim.Adam(model.parameters())
def mdn_loss_fn(y, mu, sigma, pi):
m = torch.distributions.Normal(loc=mu, scale=sigma)
loss = torch.exp(m.log_prob(y))
loss = torch.sum(loss * pi, dim=1)
loss = -torch.log(loss)
return torch.mean(loss)
for epoch in range(10000):
pi, mu, sigma = model(x_data)
loss = mdn_loss_fn(y_data, mu, sigma, pi)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 1000 == 0:
print(loss.data.tolist())
pi, mu, sigma = model(x_test)
k = torch.multinomial(pi, 1).view(-1)
y_pred = torch.normal(mu, sigma)[np.arange(n_samples), k].data
plt.figure(figsize=(8, 8))
plt.scatter(x_data, y_data, alpha=0.4)
plt.scatter(x_test, y_pred, alpha=0.4, color='red')
plt.show()