PCA及其实战学习
知识学习
整体思想就是根据重要特征(为主)附加其他特征(为辅)生成新的维度的特征

代码实战
学习视频链接:b站传送门
这里使用了来自视频教程的数据集:github传送门
数据集下载方式:CSDN传送门
首先是数据预处理部分:
过程中所需要使用的所有包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
获得原始数据并进行简要查看,可以借助info和head工具
#数据集处理部分
traindata_0 = pd.read_csv(r'C:\Users\Administrator\Desktop\train_titanic.csv', index_col = 'PassengerId')
'''Pandas dataframe.info()函数用于获取 DataFrame 的简要摘要。在对数据进行探索性分析时,它非常方便。为了快速浏览数据集,我们使用dataframe.info()功能。
用法: DataFrame.info(verbose=None, buf=None, max_cols=None, memory_usage=None, null_counts=None)
参数:verbose:是否打印完整的摘要。屏幕上将不显示任何内容。max_info_columns设置。 True或False会覆盖显示。max_info_columns设置。buf:可写缓冲区,默认为sys.stdoutmax_cols:确定是打印完整摘要还是简短摘要。屏幕上将不显示任何内容。max_info_columns设置。memory_usage:指定是否应显示DataFrame元素(包括索引)的总内存使用情况。屏幕上将不显示任何内容。memory_usage设置。 True或False会覆盖显示。memory_usage设置。 “ deep”的值与True相同,具有自省性。内存使用情况以人类可读的单位(以2为基数的表示形式)显示。null_counts:是否显示非空计数。如果为None,则仅显示框架是否小于max_info_rows和max_info_columns。如果为True,则始终显示计数。如果为False,则从不显示计数。'''
print(traindata_0.info())
'''Pandas DataFrame head()方法返回DataFrame或Series的前n行,其中n是用户输入值。 head()函数用于获取前n行。这对于快速测试对象中的数据类型是否正确非常有用。对于n的负值,head()函数返回除最后n行之外的所有行,等效于df[:-n]。
句法:DataFrame.head(n=5) (n=5 is default we can set any value)
参量:python中的head()方法仅包含一个参数,即n。它是一个可选参数。通过设置它,我们固定了想要从DataFrame获得的行数。
返回值:head()函数从DataFrame返回n行。'''
# print(traindata_0.head())
traindata_0.head()
#对缺失数据的声明,Age,Embarked,Cabin,可以看出,它们的数据量小
#先使用常规方法处理缺失数据,本期重点在PCA
处理缺失数据
traindata = traindata_0.copy()
#replace
#其实这里最好使用one-hot形式,但是最终使用的类似于是查表法
traindata.Sex = traindata.Sex.replace({'female':0, 'male':1})
traindata.Embarked = traindata_0.Embarked.replace({'C':0, 'Q':1, 'S':2})
#fillna
traindata.Age.fillna(traindata.Age.mean(), inplace = True)
traindata.Embarked.fillna(method = 'ffill', inplace = True)
#drop
traindata.drop(columns = ['Survived', 'Name', 'Ticket', 'Cabin'], inplace = True)
traindata.info()
print(traindata.head())
traindata.to_csv(r'C:\Users\Administrator\Desktop\data_pca.csv')
然后是pca部分:
读入数据,得有一个矩阵x,维度为(m,n),m个采样数据,每个数据有n个feature
data = pd.read_csv(r'C:\Users\Administrator\Desktop\data_pca.csv')
data.describe()
#可以看出量纲差别还是比较大的。
对x去均值、标准化
def norm_(x):#做normalization标准化
xmean = np.mean(x, 0)
std = np.std(x,0)
return (x - xmean)/std
data_ = norm_(data)
data_.describe()
#这里能够看出明显区别。标准化了嘛,均值变成0,量纲差异也没有了
求 X T X X^TX XTX或 C o v ( X T ) Cov(X^T) Cov(XT)的特征值 ( e w ) (ew) (ew)和特征向量 ( e v ) (ev) (ev),其中维度: e w ( 1 , n ) , e v ( n , n ) ew(1,n),ev(n,n) ew(1,n),ev(n,n)
借助numpy工具提取特征值
#提取特征值
#第一种方式Xt*X(agin value是下面的m-1倍)
ew, ev = np.linalg.eig(data_.T.dot(data_))#原始数据的格式不合适
print(ew)
print(ev)
print('\n')
#第二种方式,方便起见采用了这一种
ew, ev = np.linalg.eig(np.cov(data_.T))
print(ew)
print(ev)
print('\n')
按照 e w ew ew从大到小的顺序,取 e v ev ev的对应的列。 e v ev ev取前k列得到矩阵 V V V,维度 ( n , k ) (n,k) (n,k)
将特征值进行排序
#将特征值进行排序
'''在输出数据中可以看出有七个特征值(分别对应七个特征,但是没有按照顺序排布)'''
ew_order = np.argsort(ew)[::-1]#[::-1]可以令其从大到小排序,去掉就是从小到大排序
#注意argsort是获得标号的,不是获得值的
print(ew_order)
ew_sort = ew[ew_order]
ev_sort = ev[:,ew_order]
print(ew_sort)
print(ev_sort)
画图来直观认识一下特征向量:
pd.DataFrame(ew_sort).plot(kind='bar')
得到图片如下:
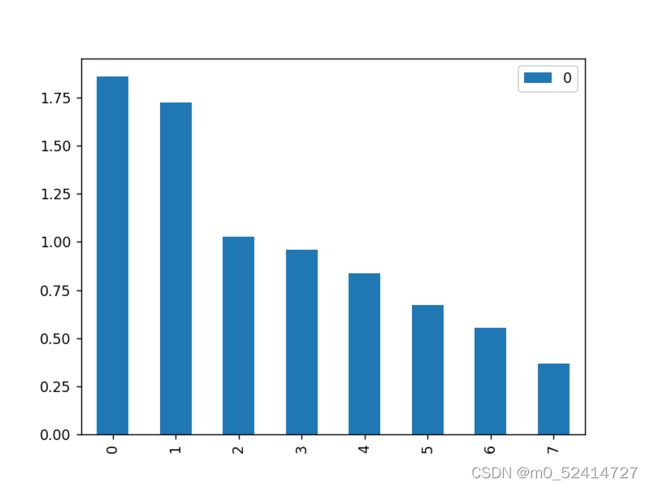
我们希望使得前k个的核远大于后几个,能达到总核的95%就是最理想的,这样的话主成分提取就会效果比较好。
因为我们需要将原始的7个feature降到几个feature去代表观察,这里的话前两个可以近似代表观察。
于是我们提取关键特征
V = ev_sort[:,:2]#这里就是应上面所说的取前两列
有 X n e w = X ∗ V X_{new}=X * V Xnew=X∗V, 维度: X n e w ( m , k ) X_{new}(m,k) Xnew(m,k)
X_new = data_.dot(V)#原始数据和V内积
print(x_new.shape)#可以看到由(891,7)降到了(891,2)
前k个 e v ev ev即主成分(主方向)。因为前k个很重要,就实现了从n维到k维的降维
此时可以画图查看一下(不知道为什么我画的图和教程不是特别一致)
#scatter
#先确认一下X_new的格式
print(type(X_new))#可以看出是DataFrame
%matplotlib notebook
#由于X_new的格式是DataFrame而不是array所以这里不能这么用
# plt.scatter(X_new[:,0], X_new[:,1],s=5, c = traindata_0.Survived,cmap = plt.cm.coolwarm)
sc = plt.scatter(X_new.iloc[:,0], X_new.iloc[:,1],s=5, c = traindata_0.Survived,cmap = plt.cm.coolwarm)
plt.xlabel('PC 0')#第一组特征
plt.ylabel('PC 1')#第二组特征
plt.colorbar(sc)