R语言手动绘制分类Logistic回归模型的校准曲线(Calibration curve)(3)
校准曲线图表示的是预测值和实际值的差距,作为预测模型的重要部分,目前很多函数能绘制校准曲线。
一般分为两种,一种是通过Hosmer-Lemeshow检验,把P值分为10等分,求出每等分的预测值和实际值的差距

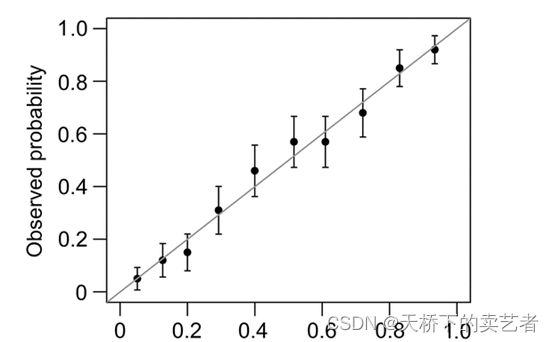
另外一种是calibration函数重抽样绘制连续的校准图
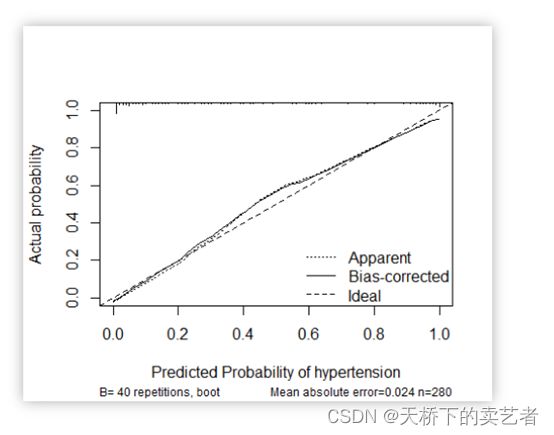
我们既往文章《手动绘制R语言Logistic回归模型的外部验证校准曲线(Calibration curve)(2)》已经介绍了如何绘制外部验证模型的校准曲线,今天我们来介绍一下如何绘制分类的校准曲线,如下面的图

其实如果我们了解了绘图原理就会明白,这4个曲线就是4个概率,只要求出概率,绘制这样的图形非常轻松,我们今天来演示一下
我们先导入数据,继续使用我们的早产数据,
bc<-read.csv("E:/r/test/zaochan.csv",sep=',',header=TRUE)
library(ggplot2)
library(rms)
library(tidyverse)
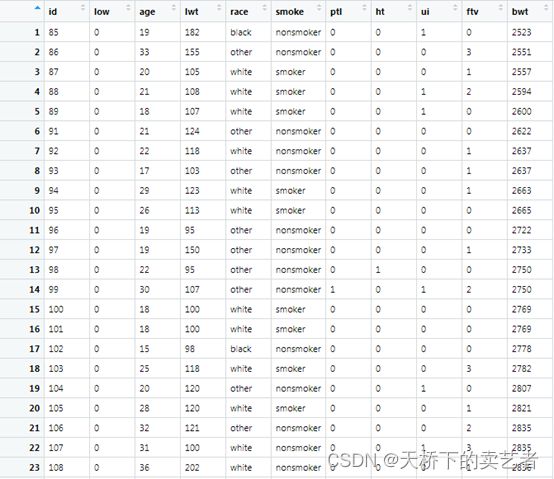
这是一个关于早产低体重儿的数据(公众号回复:早产数据,可以获得该数据),低于2500g被认为是低体重儿。数据解释如下:low 是否是小于2500g早产低体重儿,age 母亲的年龄,lwt 末次月经体重,race 种族,smoke 孕期抽烟,ptl 早产史(计数),ht 有高血压病史,ui 子宫过敏,ftv 早孕时看医生的次数,bwt 新生儿体重数值。
我们先把分类变量转成因子
bc$race<-ifelse(bc$race=="black",1,ifelse(bc$race=="white",2,3))
bc$smoke<-ifelse(bc$smoke=="nonsmoker",0,1)
bc$race<-factor(bc$race)
bc$ht<-factor(bc$ht)
bc$ui<-factor(bc$ui)
bc$smoke<-factor(bc$smoke)
假设我们想了解吸烟人群和不吸烟人群比较,模型的预测能力有什么不同,可以把原数据分成2个模型,分别做成校准曲线,然后进行比较,
先分成吸烟组和不吸烟组两个数据
dat0<-subset(bc,bc$smoke==0)
dat00<-dat0[,-6]
dat1<-subset(bc,bc$smoke==1)
dat11<-dat1[,-6]
建立两个回归方程
fit0<-glm(low ~ age + lwt + race + ptl + ht + ui + ftv,
family = binomial("logit"),
data = dat00)
fit1<-glm(low ~ age + lwt + race + ptl + ht + ui + ftv,
family = binomial("logit"),
data = dat11)
我们做校准曲线还需求出方程的概率和Y值,两个方程都要求,
pr0<- predict(fit0,type = c("response"))#得出预测概率
y0<-dat00[, "low"]
pr1<- predict(fit1,type = c("response"))#得出预测概率
y1<-dat11[, "low"]
得出了数据,概率和Y值后就可以按我们上一篇的方法做出校准曲线了,我这里为了节省时间直接用我自己编写的gg2程序代替了,就是就是把原来的步骤整合在一起,gg2程序可以做出单独和分类的校准曲线,
smoke0<-gg2(dat00,pr0,y0,group = 2,leb = "nosmoke")
做分类的时候有5个参数,前面3个是数据,概率和Y值,group = 2是固定的,leb = "nosmoke"是你想给这个分类变量取的名字,生成如下数据

接下来做吸烟组的数据
smoke1<-gg2(dat11,pr1,y1,group = 2,leb = "smoke")
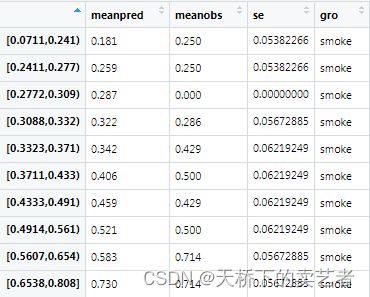
把两个数据合并最后生成绘图数据
plotdat<-rbind(smoke0,smoke1)
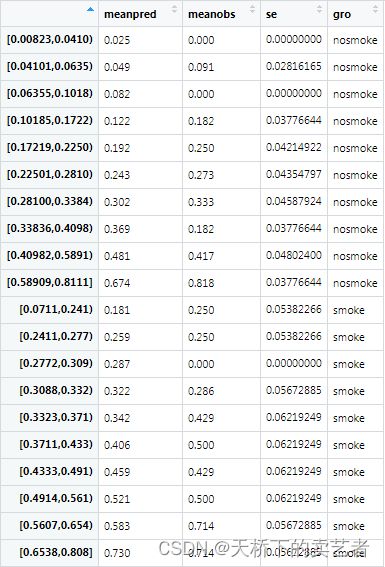
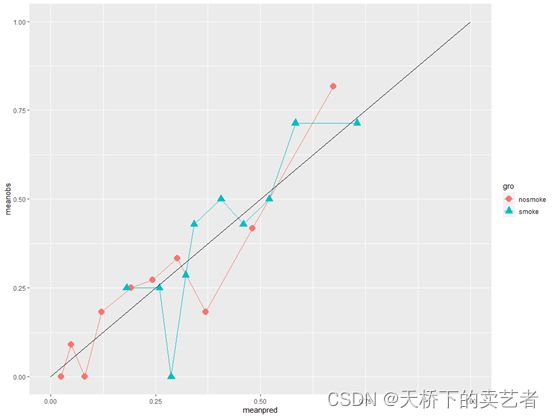
生成了绘图数据后就可以绘图了,只需把plotdat放进去其他不用改,当然你想自己调整也是可以的
ggplot(plotdat, aes(x=meanpred, y=meanobs, color=gro,fill=gro,shape=gro)) +
geom_line() +
geom_point(size=4)+
annotate(geom = "segment", x = 0, y = 0, xend =1, yend = 1)+
expand_limits(x = 0, y = 0)
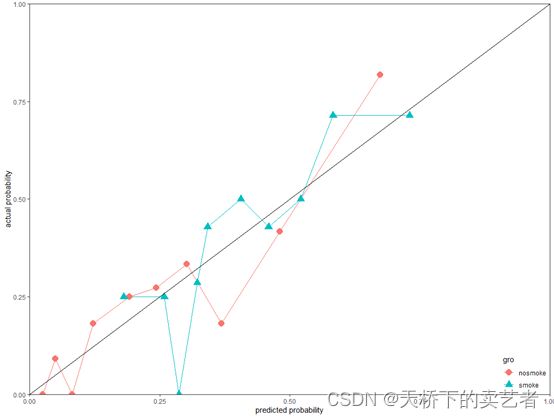
美化一下图形,这样一个用于发表的图就做好了
ggplot(plotdat, aes(x=meanpred, y=meanobs, color=gro,fill=gro,shape=gro)) +
geom_line() +
geom_point(size=4)+
annotate(geom = "segment", x = 0, y = 0, xend =1, yend = 1)+
expand_limits(x = 0, y = 0)+
scale_x_continuous(expand = c(0, 0)) +
scale_y_continuous(expand = c(0, 0))+
xlab("predicted probability")+
ylab("actual probability")+
theme_bw()+
theme(panel.grid.major = element_blank(),panel.grid.minor = element_blank())+
theme(legend.justification=c(1,0),
legend.position=c(1,0))
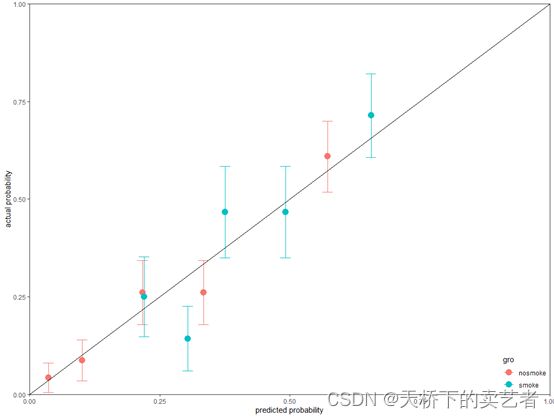
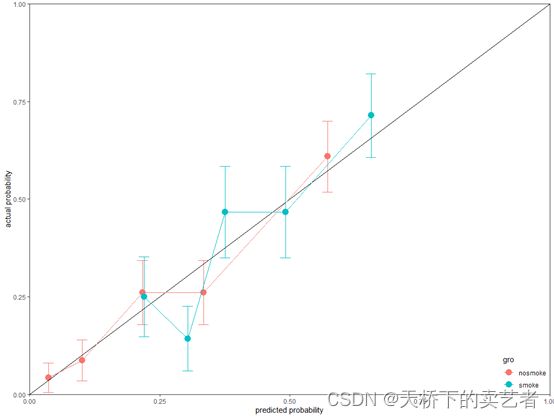
我们还可以做出带可信区间的分类校准曲线,我们把概率区间调小一点,10个太多了,画图不够美观,我看很多函数都是做成5个。(当然你不调也是可以的)
smoke0<-gg2(dat00,pr0,y0,group = 2,leb = "nosmoke",g=5)
smoke1<-gg2(dat11,pr1,y1,group = 2,leb = "smoke",g=5)
plotdat<-rbind(smoke0,smoke1)

得出数据后就可以继续绘图了
ggplot(plotdat, aes(x=meanpred, y=meanobs, color=gro,fill=gro)) +
geom_errorbar(aes(ymin=meanobs-1.96*se, ymax=meanobs+1.96*se,), width=.02)+
geom_point(size=4)+
annotate(geom = "segment", x = 0, y = 0, xend =1, yend = 1)+
expand_limits(x = 0, y = 0)+
scale_x_continuous(expand = c(0, 0)) +
scale_y_continuous(expand = c(0, 0))+
xlab("predicted probability")+
ylab("actual probability")+
theme_bw()+
theme(panel.grid.major = element_blank(),panel.grid.minor = element_blank())+
theme(legend.justification=c(1,0),legend.position=c(1,0))
也可以加入连线,不过我这个数据加入连线感觉不是很美观
ggplot(plotdat, aes(x=meanpred, y=meanobs, color=gro,fill=gro)) +
geom_errorbar(aes(ymin=meanobs-1.96*se, ymax=meanobs+1.96*se,), width=.02)+
geom_point(size=4)+
annotate(geom = "segment", x = 0, y = 0, xend =1, yend = 1)+
expand_limits(x = 0, y = 0)+
scale_x_continuous(expand = c(0, 0)) +
scale_y_continuous(expand = c(0, 0))+
xlab("predicted probability")+
ylab("actual probability")+
theme_bw()+
theme(panel.grid.major = element_blank(),panel.grid.minor = element_blank())+
theme(legend.justification=c(1,0),
legend.position=c(1,0)) +
geom_line()
OK,本期文章结束,觉得有用的话多多分享哟。