《动手学深度学习》笔记 2.2 “数据预处理”
开始进行《动手学深度学习》的学习,记录一切学习到的值得学习的东西。
一. python3的OS模块
1.创建目录
os.makedirs(path, mode, exist_ok)
该函数用来递归创建多层目录
path:path是递归创建的目录,可以是相对路径或者绝对路径
mode:mode是权限模式,默认值是511(八进制)
exist_ok:是否在目录存在时触发异常。如果 exist_ok 为 False(默认值),则在目标目录已存在的情况下触发 FileExistsError 异常;如果 exist_ok 为 True,则在目标目录已存在的情况下不会触发 FileExistsError 异常。
2.合并文件
os.path.join(path1[], path2[, ...])
该函数用来将目录和文件名合成一个路径,如:
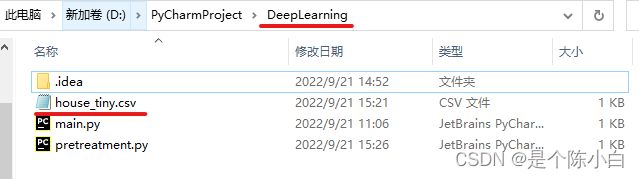
data_file = os.path.join('..', 'data', 'house_tiny.csv')
就是将"house_tiny.csv"文件合并到了data目录下

同理,要是将参数值’data’换成另一个目录’Deeplearning’
data_file = os.path.join('..', 'DeepLearning', 'house_tiny.csv')
那么,DeepLearning目录下就会出现这个文件
但是该函数的第一个参数‘…’,目前暂时不知道是什么意思,猜测是文件所在的上级目录,或者是根目录,后续再进行了解。
注意:os.patn.join()函数只是用来合并文件和目录名,如果是想要创建目录并合并,可以这样使用:
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
二. python3内置函数
1.打开文件
open(file, mode='r')
file:该参数就是要执行操作的文件对象
mode:该参数描述了要对文件执行什么样的操作,'r'就是读文件,'w'就是写文件。如:
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n')
就是写入"NumRooms,Alley,Price"
-------------------------------------------------------------------------手动分割线----------------------------------------------------------------------------------
这里有个写入文件的地方要注意。
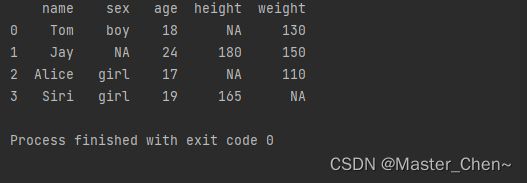
若输入数据集的列值,数据和数据之间的逗号还有一个空格时,系统输出时是当作一个正常的数据来处理
with open(datafile, 'w') as f:
f.write('name, sex, age, height, weight\n') # 列名
f.write('Tom, boy, 18, NA, 130\n')
f.write('Jay, NA, 24, 180, 150\n')
f.write('Alice, girl, 17, NA, 110\n')
f.write('Siri, girl, 19, 165, NA\n')
可以看到若输入的是"NA",则输出时也是"NA",而正常python中输入是"NA"时,输出应该时"NaN"代表空值
正确的输入应该时删掉数据和数据之间的空格,只保留逗号作分隔。
with open(datafile, 'w') as f:
f.write('name,sex,age,height,weight\n') # 列名
f.write('Tom,boy,18,NA,130\n')
f.write('Jay,NA,24,180,150\n')
f.write('Alice,girl,17,NA,110\n')
f.write('Siri,girl,19,165,NA\n')
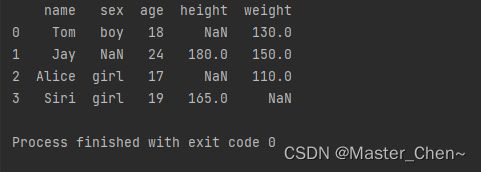
这时候当输入为空值时,系统的输出显示才正确为"NaN"
三. python3的pandas库
pandas是python的扩展程序库,用于数据分析操作。
1.CSV文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
在pands中提供了访问CSV文件的方法
data = pd.read_csv(data_file)
print(data)

2.检测缺失值
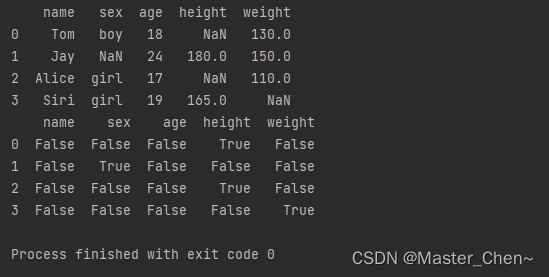
pandas的dataframe.isna()函数用于检测缺失值,返回一个布尔值,当对应的数据为空时,即值为None或者NA时,返回True。反之返回False。
data = pd.read_csv(datafile)
print(data)
print(data.isna())
3.获取对应列的值
根据实验,可以知道使用pandas读取CSV文件后,返回的是一个DataFrame类型的数据结构。那么获取对应的列值就简单了:
比如在这里获取列name的值:
(暂时还不知道如何返回多列值)
print(data['name'])
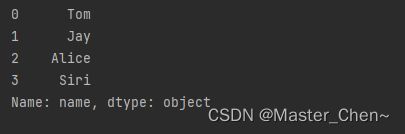
4.dataframe.drop()
dataframe.drop()可以用来删除该表格的行或者列值。该函数有多个参数类型来指定删除行还是列,删除几行几列。
data_new2 = data.drop(['height', 'weight'], axis=1)
删除了height和weight列,其中axis=1指定按列删除,若为0,则是按行删除。
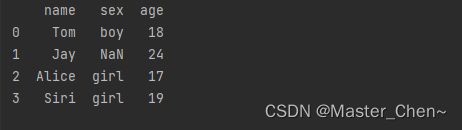
5.iloc的用法
iloc[ ; ]行列切片,中间用“;”隔开,分号前面取的是行,分号后面取的是列
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
就是将data数据的前两列赋给了inputs,将最后一列赋给了outputs
6.数据清洗
在数据集中常常有不合理的数据值,如缺失,重复,格式错误等。pandas提供了数据清洗的方法。
用fillna()方法来替换一些空字段。那么用什么值来填入数据集中缺失的值呢?在这里用了计算列均值的方法:mean()
inputs = inputs.fillna(inputs.mean())
print(inputs)
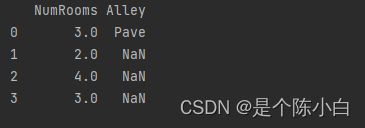
可以看到前两列值赋给了Inputs变量,且原本第一行和第四行的NumRooms是空值,计算列均值后填入。
7.类别和离散值的转换
对于第二列属性Alley而言,只有Pave和NaN两个属性,属于类别和离散值。pandas可以自动将这一列转换为Alley_Pave和Alley_nan。其中Alley_Pave下值为Pave的那一行赋值为1,nan为0。Alleynan则相反。
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)

这样以来,数据集就全转换为数值格式了。
再接下来,就可以转换成张量格式以便运算。
四. python的PyTorch库
1.将数据集转换成张量格式
x, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
print(x, y)
