深度学习——卷积神经网络
卷积神经网络(Convolutional Neural Networks, CNN)在深度学习领域有着广泛的使用。本篇文章介绍一下CNN的原理及实现过程。
CNN原理
前馈神经网络的缺陷
在使用传统的前馈神经网络进行图片的特征提取时,需要首先将图片的像素矩阵拉直,以符合前馈神经网络的输入要求。但如果图片进行了位移或旋转,尽管图片本身的内容没有改变,但其拉直后的输入向量会有很大的变化。经过前馈神经网络特征提取得到的特征也会有不同,不利于进行后续的分类等操作。
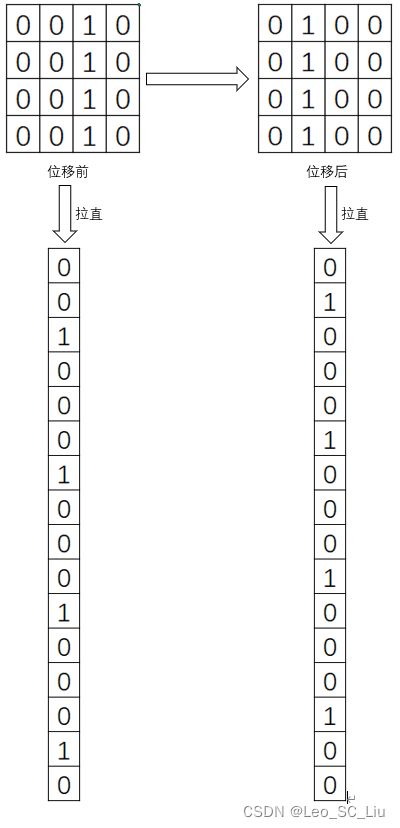
图1 图片矩阵及其位移
如图1所示,位移前和位移后的像素矩阵拉直后有很大的区别,位移前为1的地方在位移后都变为了0。前馈神经网络可能会认为二者并无关联,属于两类不同的特征。但使用CNN则可以克服这个问题。
CNN计算方法
卷积
与前馈神经网络不同,CNN可以直接在二维的图片像素矩阵上进行计算。其提出了卷积核的思想。所谓卷积核,其实就是一个二维的矩阵。如图2所示,其中间的矩阵就被称为卷积核。卷积核通过和图片矩阵进行预算,提取了图片的特征,这一步骤被称为卷积。
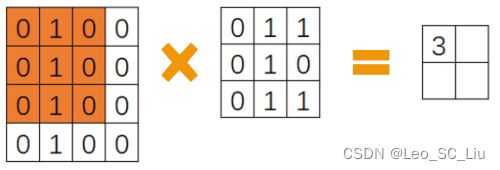
图2 卷积1
选出一个和卷积核大小相同的窗口(橙色区域),最开始窗口放置于图片矩阵的左上角上。窗口中的每个元素与卷积核对应位置的元素相乘,再将相乘结果相加,即可得到卷积的结果。如图2中进行的计算为0*0+1*1+1*0+0*0+1*1+0*0+0*0+1*1+1*0=3。
完成一次计算后,需要将窗口在图片矩阵上移动n个步长。窗口首选的移动方向是从左向右。若窗口的最右端已抵达图片的最右端,则将窗口向下移动n个步长,并重新回到最左端。在图2中的计算完成后,窗口就会移动到如图3所示的状态(这里设定步长为1,即n=1)。
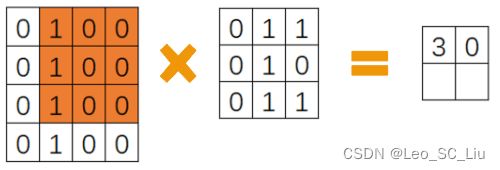
图3 卷积2
图3中进行的计算为0*1+1*0+1*0+0*1+1*0+0*0+0*1+1*0+1*0=0。将每次计算的结果记录到一个新的矩阵中,在所有计算完成后即可得到一个全新的特征矩阵。完成这一步也就完成了一次卷积。
池化
卷积步骤可以从图片中提取特征,但在很多时候,一个区域内只需要选出最主要的特征就可以完成后续的分类了。因此,CNN还需要进行池化操作。
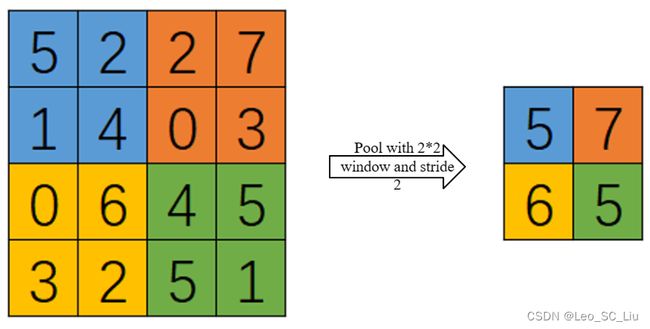
图4 池化
池化分为最大池化和平均池化两种,图4描述了最大池化的过程。所谓最大池化,就是在池化窗口中选出最大值保留。池化需要设置池化窗口的大小和步长。在图4中采用了2*2的池化窗口,并设置步长为2。其中不同颜色的区域表示了不同的池化窗口。在第一个池化窗口中(蓝色),由于5为最大值,则得到池化结果为5。对每个池化窗口进行相同的操作,再将结果记录到一个新的矩阵中,就可以得到池化后的矩阵。
平均池化与最大池化类似,其只是将取最大值的操作改为了去均值的操作。若对图4蓝色区域进行平均池化,得到的结果则为(5+2+1+4)÷4=3。
代码实现
使用CNN进行手写数字识别的代码如下:
import sys
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sklearn
import time
# Import our deep learning libraries which were installed last week
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
np.random.seed(42)
tf.random.set_seed(42)
keras.backend.clear_session()
# Load data
(X_train_full, y_train_full), (X_test, y_test) = keras.datasets.mnist.load_data()
# Scale the data to the range 0-1
X_train_full = X_train_full / 255.
X_test = X_test / 255.
# Create validation set from the training set
X_train, X_valid, y_train, y_valid = train_test_split(X_train_full, y_train_full, train_size=0.9)
# Print the shape of data
print(f"Shape of X_train: {X_train.shape}")
X_train = np.expand_dims(X_train, -1)
X_valid = np.expand_dims(X_valid, -1)
X_test = np.expand_dims(X_test, -1)
print(f"New shape of X_train: {X_train.shape}")
# Create model
model1=keras.Sequential([
keras.Input(shape=(28, 28, 1)),
# Conv and pool block 1
keras.layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
keras.layers.AveragePooling2D(pool_size=(2, 2)),
# Conv and pool block 2
keras.layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
keras.layers.AveragePooling2D(pool_size=(2, 2)),
# Flatten and classify using dense output layer
keras.layers.Flatten(),
keras.layers.Dropout(0.5),
keras.layers.Dense(10, activation="softmax"),
])
model1.compile(loss='sparse_categorical_crossentropy',
optimizer="adam",metrics=['accuracy'])
batch_size = 128
epochs = 10
# Train CNN model
history = model1.fit(X_train, y_train, batch_size=batch_size,epochs=epochs, validation_data=(X_valid, y_valid))