字符串问题
文章目录
-
- 判断两个字符串是否互为变形词
- 判断两个字符串是否互为旋转词
- 将整数字符串转成整数值
- 字符串的统计字符串
- 判断字符数组中是否所有的字符都只出现过一次
- 在有序但含有空的数组中查找字符串
- 字符串的调整与替换
- 翻转字符串
- 完美洗牌问题
- 删除多余字符得到字典序最小的字符串
- 数组中两个字符串的最小距离
- 字符串的转换路径问题
- 添加最少字符使字符串整体都是回文字符串
- 括号字符串的有效性和最长有效长度
- 公式字符串求值
- 0 左边必有 1 的二进制字符串数量
- 拼接所有字符串产生字典顺序最小的大写字符串
- 找到字符串的最长无重复字符子串
- 找到指定的新类型字符
- 旋变字符串问题
- 最小包含子串的长度
- 回文最少分割数
- 字符串匹配问题
- 字典树(前缀树)的实现
- 子数组的最大异或和
判断两个字符串是否互为变形词
【题目】
给定两个字符串 str1 和 str2,如果 str1 和 str2 中出现的字符种类一样且每种字符出现的次数也一样,那么 str1 与 str2 互为变形词。请实现函数判断两个字符串是否互为变形词。
例如:
str1=“123”,str2=“231”,返回 true。
str1=“123”,str2=“2331”,返回 false。
【解答】
-
建立字符编码值的词频表
如果字符串 str1 和 str2 长度不同,直接返回 false。如果长度相同,假设出现字符的编码值在 0~255 之间,那么先申请一个长度为 256 的整型数组 map,map[a]=b 代表字符编码为 a 的字符出现了 b 次,初始时 map[0…255]的值都是 0。然后遍历字符串 str1,统计每种字符出现的数量,比如遍历到字符’a’,其编码值为 97,则令 map[97]++。这样 map 就成了 str1 中每种字符的词频统计表。然后遍历字符串 str2,每遍历到一个字符,都在 map 中把词频减下来,比如遍历到字符’a’,其编码值为 97,则令 map[97]–,如果减少之后的值小于 0,直接返回 false。如果遍历完 str2,map 中的值也没出现负值,则返回 true。
【代码】
#include 附:如果字符的类型有很多,可以用哈希表代替长度为 256 的整型数组,但整体过程不变。
判断两个字符串是否互为旋转词
【题目】
如果一个字符串为 str,把字符串 str 前面任意的部分挪到后面形成的字符串叫作 str 的旋转词。比如 str=“12345”,str 的旋转词有"12345"、“23451”、“34512”、“45123"和"51234”。给定两个字符串 a 和 b,请判断 a 和 b 是否互为旋转词。
例如:
a=“cdab”,b=“abcd”,返回 true。
a=“1ab2”,b=“ab12”,返回 false。
a=“2ab1”,b=“ab12”,返回 true。
【解答】
-
字符串拼接包含自身所有旋转词+KMP
如果 a 和 b 的长度不一样,字符串 a 和 b 不可能互为旋转词。如果a 和 b 长度一样,先生成一个大字符串 b2,b2 是两个字符串 b 拼在一起的结果,即 string b2 = b + b。然后看 b2 中是否包含字符串 a,如果包含,说明字符串 a 和 b 互为旋转词,否则说明两个字符串不互为旋转词。这是为什么呢?举例说明,假设 a=“cdab”,b=“abcd”。b2=“abcdabcd”,b2[0…3]="abcd"是 b 的旋转词,b2[1…4]="bcda"是 b 的旋转词……b2[i…i+3]都是 b 的旋转词,b2[4…7]="abcd"是 b 的旋转词。由此可见,如果一个字符串 b 长度为 N。在通过 b 生成的 b2 中,任意长度为 N 的子串都是 b 的旋转词,并且 b2 中包含字符串 b 的所有旋转词。
后面看 b2 中是否包含字符串 a 需要用到KMP算法。
【代码】
#include 将整数字符串转成整数值
【题目】
给定一个字符串 str,如果 str 符合日常书写的整数形式,并且属于 32 位整数的范围,返回 str 所代表的整数值,否则返回 0。
例如:
str=“123”,返回 123。
str=“023”,因为"023"不符合日常的书写习惯,所以返回 0。
str=“A13”,返回 0。str=“0”,返回 0。
str=“2147483647”,返回 2147483647。
str=“2147483648”,因为溢出了,所以返回 0。
str=“-123”,返回-123。
【解答】
-
穷举例外情况+判断越界溢出(负数绝对值范围大于正数)
首先检查 str 是否符合日常书写的整数形式,具体判断如下:
1.如果 str 不以“-”开头,也不以数字字符开头,例如,str=“A12”,返回 false。
2.如果 str 以“-”开头,但是 str 的长度为 1,即 str=“-”,返回 false。如果 str 的长度大于 1,但是“-”的后面紧跟着“0”,例如,str=“-0"或”-012",返回 false。
3.如果 str 以“0”开头,但是 str 的长度大于 1,例如,str=“023”,返回 false。
4.如果经过步骤 1~步骤 3 都没有返回,接下来检查 str[1…N-1]是否都是数字字符,如果有一个不是数字字符,则返回 false。如果都是数字字符,说明 str 符合日常书写,返回 true。
如果 str 不符合日常书写的整数形式,根据题目要求,直接返回 0 即可。如果符合,则进行如下转换过程。
1.生成 4 个变量。布尔型常量 posi,表示转换的结果是负数还是非负数,这完全由 str 开头的字符决定,如果以“-”开头,那么转换的结果一定是负数,则 posi 为 false,否则 posi 为true。整型常量 minq,minq 等于 INT_MIN/10,即 32 位整数最小值除以 10 得到的商,其意义稍后说明。整型常量 minr,minr 等于 INT_MIN%10,即 32 位整数最小值除以 10 得到的余数,其意义稍后说明。整型变量 res,转换的结果,初始时 res=0。
2.32 位整数的最小值为 -2147483648,32 位整数的最大值为 2147483647。可以看出,最小值的绝对值比最大值的绝对值大 1,所以转换过程中的绝对值一律以负数的形式出现,然后根据 posi 决定最后返回什么。比如 str=“123”,转换完成后的结果是 -123,posi=true,所以最后返回 123。再如 str=“-123”,转换完成后的结果是 -123,posi=false,所以最后返回-123。比如str=“-2147483648”,转换完成后的结果是 -2147483648,posi=false,所以最后返回 -2147483648。比如 str=“2147483648”,转换完成后的结果是 -2147483648,posi=true,此时发现-2147483648 变成 2147483648 会产生溢出,所以返回 0。也就是说,既然负数比正数拥有更大的绝对值范围,那么转换过程中一律以负数的形式记录绝对值,最后再决定返回的数到底是什么。
3.如果 str 以’-‘开头,从 str[1]开始从左往右遍历 str,否则从 str[0]开始从左往右遍历 str。举例说明转换过程,比如 str=“123”,遍历到’1’时,res=res * 10+(-1)=-1,遍历到’2’时,res=res * 10+(-2)=-12,遍历到’3’时,res=res * 10+(-3)=-123。比如 str=“-123”,字符’-‘跳过,从字符’1’开始遍历,res=res * 10+(-1)=-1,遍历到’2’时,res=res * 10+(-2)=-12,遍历到’3’时,res=res * 10+(-3)=-123。遍历的过程中如何判断 res 已经溢出了?假设当前字符为 a,那么’0’-a就是当前字符所代表的数字的负数形式,记为 cur。如果在 res 加上 cur 之前,发现 res 已经小于 minq,那么 res 加上 cur 之后一定会溢出,比如 str=“3333333333”,遍历完倒数第二个字符后,res=-333333333 < minq=-214748364,所以当遍历到最后一个字符时,res*10 肯定会产生溢出。如果在 res 加上 cur 之前,发现 res 等于 minq,但又发现 cur 小于 minr,那么 res 加上 cur 之后一定会溢出,比如 str=“2147483649”,遍历完倒数第二个字符后,res=-214748364 = minq,当遍历到最后一个字符时发现有 res=minq,同时也发现 cur= -9 < minr=-8,那么 res 加上 cur 之后一定会溢出。出现任何一种溢出情况时,直接返回 0。
4.遍历后得到的 res 根据 posi 的符号决定返回值。如果 posi 为 true,说明结果应该返回正,否则说明应该返回负。如果 res 正好是 32 位整数的最小值,同时又有 posi 为 true,说明溢出,直接返回 0。
【代码】
#include 字符串的统计字符串
【题目】
给定一个字符串 str,返回 str 的统计字符串。例如,“aaabbadddffc"的统计字符串为"a_3_b_2_a_1_d_3_f_2_c_1”。
补充问题:给定一个字符串的统计字符串 cstr,再给定一个整数 index,返回 cstr 所代表的原始字符串上的第 index 个字符。例如,"a_1_b_100"所代表的原始字符串上第 0 个字符是’a’,第 50 个字符是’b’。
【解答】
-
原问题:遍历
原问题。具体过程如下:
1.如果 str 为空,那么统计字符串不存在。
2.如果 str 不为空。首先生成 string 类型的变量 res,表示统计字符串,还有整型变量 num,代表当前字符的数量。初始时字符串 res 只包含 str 的第 0 个字符(str[0]),同时 num=1。
3.从 str[1]位置开始,从左到右遍历 str,假设遍历到 i 位置。如果 str[i]==str[i-1],说明当前连续出现的字符(str[i-1])还没结束,令 num++,然后继续遍历下一个字符。如果 str[i]!=str[i-1],说明当前连续出现的字符(str[i-1])已经结束,令 res=res+" _ “+num+” _ “+str[i],然后令 num=1,继续遍历下一个字符。以题目给出的例子进行说明,在开始遍历"aaabbadddffc"之前,res=“a”,num=1。遍历 str[1~2]时,字符’a’一直处在连续的状态,所以 num 增加到 3。遍历 str[3]时,字符’a’连续状态停止,令 res=res+” _ “+“3”+” _ “+“b”(即"a_3_b”),num=1。遍历 str[4],字符’b’在连续状态,num 增加到 2。遍历 str[5]时,字符’a’连续状态停止,令 res 为"a_3_b_2_a",num=1。依此类推,当遍历到最后一个字符时,res 为"a_3_b_2_a_1_d_3_f_2_c",num=1。
4.对于步骤 3 中的每一个字符,无论是连续还是不连续,都是在发现一个新字符时再将这个字符连续出现的次数放在 res 的最后。当遍历结束时,最后字符的次数还没有放入 res,所以,最后令 res=res+“_”+num。在步骤 3 的例子中,当遍历结束时,res 为"a_3_b_2_a_1_d_3_f_2_c",num=1,最后需要把 num 加在 res 后面,令 res 变为"a_3_b_2_a_1_d_3_f_2_c_1",然后再返回。
-
补充问题:遍历+连续数字字符转 int
补充问题。求解的具体过程如下:
1.布尔型变量 stage,stage 为 true 表示目前处在遇到字符的阶段,stage 为 false 表示目前处在遇到连续字符统计的阶段。字符型变量 cur,表示在上一个遇到字符阶段时,遇到的是 cur字符。整型变量 num,表示在上一个遇到连续字符统计的阶段时,字符出现的数量。整型变量sum,表示目前遍历到 cstr 的位置相当于原字符串的什么位置。初始时,stage=true,cur=0(字符编码为 0 表示空字符),num=0,sum=0。
2.从左到右遍历 cstr,举例说明这个过程,cstr=“a_100_b_2_c_4”,index=105。遍历完str[0]=‘a’后,记录下遇到字符’a’,即 cur=‘a’。遇到 str[1]=’ _ ',表示该转阶段了,从遇到字符的阶段变为遇到连续字符统计的阶段,即 stage=!stage。遇到 str[2]='1’时,num=1;遇到 str[3]='0’时,num=10;遇到 str[4]=‘0’时,num=100;遇到 str[5]=’ _ ‘,表示遇到连续字符统计的阶段变为遇到字符的阶段;遇到 str[6]=‘b’,一个新的字符出现了,此时令 sum+=num(即 sum=100),sum 表示目前原字符串走到什么位置了,此时发现 sum 并未到达 index 位置,说明还要继续遍历,记录下遇到了字符’b’,即 cur=‘b’,然后令 num=0,因为字符’a’的统计已经完成,现在 num开始表示字符’b’的连续数量。也就是说,每遇到一个新的字符,都把上一个已经完成的统计数num 加到 sum 上,再看 sum 是否到达 index,如果已到达,就返回上一个字符 cur,如果没到达,就继续遍历。
3.每个字符的统计都在遇到新字符时加到 sum 上,所以当遍历完成时,最后一个字符的统计数并不会加到 sum 上,要单独加。
【代码】
- 原问题
#include - 补充问题
#include 判断字符数组中是否所有的字符都只出现过一次
【题目】
给定一个字符串 chars,判断 chars 中是否所有的字符都只出现过一次。
例如:
chars=“abc”,返回 true
chars=“121”,返回 false。
补充问题1:实现时间复杂度为 O(N)的方法。
补充问题2:在保证额外空间复杂度为 O(1)的前提下,请实现时间复杂度尽量低的方法。
【解答】
-
补充问题1:哈希表或数组
遍历一遍 chars,用 map 记录每种字符出现的情况,这样就可以在遍历时发现字符重复出现的情况,map 可以用长度固定的数组实现,也可以用哈希表unordered_map实现。
-
补充问题2:非递归方式实现堆排序
整体思路是先将 chars 中的字符进行排序,排序后相同的字符就放在一起,然后判断有没有重复字符就会变得非常容易,所以问题的关键是选择什么样的排序算法。
四种经典排序中,只有堆排序可以做到额外空间复杂度为 O(1) 的情况下,时间复杂度还能稳定地保持 O(NlogN)。但遗憾的是,虽然堆排序的确是答案,但一般堆排序的实现却是基于递归函数实现的。而我们知道递归函数需要使用函数栈空间,这样堆排序的额外空间复杂度就增加至 O(logN)。所以需要用非递归的方式实现堆排序。
【代码】
- 补充问题1
#include - 补充问题2
#include 在有序但含有空的数组中查找字符串
【题目】
给定一个字符串数组 strs[],在 strs 中有些位置为 null,但在不为 null 的位置上,其字符串是按照字典顺序由小到大依次出现的。再给定一个字符串 str,请返回 str 在 strs 中出现的最左的位置。
例如:
strs=[null,“a”,null,“a”,null,“b”,null,“c”],str=“a”,返回 1。
strs=[null,“a”,null,“a”,null,“b”,null,“c”],str=null,只要 str 为 null,就返回 -1。
strs=[null,“a”,null,“a”,null,“b”,null,“c”],str=“d”,返回 -1。
【解答】
-
二分查找
1.假设在 strs[left…right]上进行查找的过程,全局整型变量 res 表示字符串 str 在 strs 中最左的位置。初始时,left=0,right=strs.size()-1,res=-1。
2.令 mid=(left+right)/2,则 strs[mid]为 strs[left…right]中间位置的字符串。
3.如果字符串 strs[mid]与 str 一样,说明找到了 str,令 res=mid。但要找的是最左的位置,还要在左半区寻找,看有没有更左的 str 出现,所以令 right=mid-1,然后重复步骤 2。
4.如果字符串 strs[mid]与 str 不一样,并且 strs[mid]!=null,此时可以比较 strs[mid]和 str,如果 strs[mid]的字典顺序比 str 小,说明整个左半区不会出现 str,需要在右半区寻找,所以令 left=mid+1,然后重复步骤 2;如果 strs[mid]的字典顺序比 str 大,说明整个右半区不会出现 str,需要在左半区寻找,所以令 right=mid-1,然后重复步骤 2。
5.如果字符串 strs[mid]与 str 不一样,并且 strs[mid]==null,此时从 mid 开始,从右到左遍历左半区(即 strs[left…mid])。如果整个左半区都为 null,那么继续用二分的方式在右半区上查找(即令 left=mid+1),然后重复步骤 2。如果整个左半区不都为 null,假设从右到左遍历strs[left…mid]时,发现第一个不为 null 的位置是 i,那么把 str 和 strs[i]进行比较。如果 strs[i]字典顺序小于 str,同样说明整个左半区没有 str,令 left=mid+1,然后重复步骤 2。如果 strs[i]字典顺序等于 str,说明找到 str,令 res=mid,但要找的是最左的位置,还要在 strs[left…i-1]上寻找,看有没有更左的 str 出现,所以令 right=i-1,然后重复步骤 2。如果 strs[i]字典顺序大于 str,说明strs[i…right]上都没有 str,需要在 strs[left…i-1]上查找,所以令 right=i-1,然后重复步骤 2。
【代码】
#include 字符串的调整与替换
【题目】
给定一个字符串 chars,其中只含有数字字符和“ # ”字符。现在想把所有的“ # ”字符挪到 chars 的左边,数字字符挪到 chars 的右边。请完成调整函数,但不得改变数字字符从左到右出现的顺序。
例如:
chars=“12##345”。调整后 chars 为"##12345"。
【解答】
-
双指针+逆序复制
从右向左逆序复制,遇到数字字符则直接复制,遇到“ # ”字符不复制。把数字字符复制完后,再把左半区全部设置成“ # ”即可。
【代码】
#include 翻转字符串
【题目】
给定一个字符串 chars,请在单词间做逆序调整。只要做到单词的顺序逆序即可,对字符串中空格的位置没有特别要求。使用额外空间为O(1)。
例如:
chars=“dog loves pig”,调整成"pig Loves dog"。
chars=“I’m a student.”,调整成"student. a I’m"。
补充问题:给定一个字符串 chars 和一个整数 size,请把大小为 size 的左半区整体移到右半区,右半区整体移到左边。使用额外空间为O(1)。
例如:
chars=“ABCDE”,size=3,调整成"DEABC"。
【解答】
-
原问题:大逆序+小逆序
原问题。首先把 chars 整体逆序。在逆序之后,遍历 chas 找到每一个单词,然后把每个单词里的字符逆序处理即可。比如“dog loves pig”,先整体逆序变为“gip sevol god”,然后每个单词进行逆序处理就变成了“pig loves dog”。逆序之后找每一个单词的逻辑,做到不出错即可。
-
补充问题:大逆序+小逆序(法一)
补充问题。先把 chars[0…size-1]部分逆序处理,再把 chars[size…N-1]部分逆序处理,最后把 chars 整体逆序处理即可。比如,chars=“ABCDE”,size=3。先把 chars[0…2]部分逆序处理,chars 变为"CBADE",再把 chars[3…4]部分逆序处理,chars 变为"CBAED",最后把 chars 整体逆序处理,chars 变为"DEABC"。
-
补充问题:分左右半区交换字符(法二)
补充问题。用举例的方式来说明这个过程,chars=“1234567ABCD”,size=7。
1.左部分为"1234567",右部分为"ABCD",右部分的长度为 4,比左部分小,所以把左部分前 4 个字符与右部分交换,chars[0…10]变为"ABCD5671234"。右部分小,所以右部分"ABCD"换过去后再也不需要移动,剩下的部分为 chars[4…10]= “5671234”。左部分大,所以换过来的"1234"视为下一步的右部分,下一步的左部分为“567”。
2.左部分为"567",右部分为"1234",左部分的长度为 3,比右部分小,所以把右部分的后 3 个字符与左部分交换,chas[4…10]变为"2341567"。左部分小,所以左部分"567"换过去后再也不需要移动,剩下的部分为 chars[4…7]= “2341”。右部分大,所以换过来的"234"视为下一步的左部分,下一步的右部分为"1"。
3.左部分为"234",右部分为"1"。右部分的长度为 1,比左部分小,所以把左部分前 1 个字符与右部分交换,chars[4…7]变为"1342"。右部分小,所以右部分"1"换过去后再也不需要移动,剩下的部分为 chars[5…7]= “342”。左部分大,所以换过来的"2"视为下一步的右部分,下一步的左部分为"34"。
4.左部分为"34",右部分为"2"。右部分的长度为 1,比左部分小,所以把左部分前 1 个字符与右部分交换,chars[5…7]变为"243"。右部分小,所以右部分"2"换过去后再也不需要移动,剩下的部分为 chars[6…7]= “43”。左部分大,所以换过来的"3"视为下一步的右部分,下一步的左部分为"4"。
5.左部分为"4",右部分为"3"。一旦发现左部分跟右部分的长度一样,那么左部分和右部分完全交换即可,chars[6…7]变为"34",整个过程结束,chars 已经变为"ABCD1234567"。
如果每一次左右部分的划分进行 M 次交换,那么都有 M 个字符再也不需要移动,而字符数一共为 N,所以交换行为最多发生 N 次。另外,如果某一次划分出的左右部分长度一样,那么交换完成后将不会再有新的划分,所以在很多时候交换操作会少于 N 次。比如,chars=“1234ABCD”,size=4,最开始左部分为"1234",右部分为"ABCD",左右两个部分完全交换后为"ABCD1234",同时不会有后续的划分,所以,这种情况下一共只有 4 次交换操作。
【代码】
- 原问题
#include - 补充问题(法一)
#include - 补充问题(法二)
#include 完美洗牌问题
【题目】
给定一个长度为偶数的数组 arr,长度记为 2×N。前 N 个为左部分,后 N 个为右部分。arr就可以表示为{L1,L2,…,Ln,R1,R2,…,Rn},请将数组调整成{R1,L1,R2,L2,…,Rn,Ln}的样子。
例如:
arr = {1,2,3,4,5,6},调整之后为{4,1,5,2,6,3}。
进阶问题:给定一个数组 arr,请将数组调整为依次相邻的数字总是先<=、再>=的关系,并交替下去。比如数组中有五个数字,调整成{a,b,c,d,e},使之满足 a<=b>=c<=d>=e。
【解答】
-
原问题:完美洗牌结论+翻转字符串补充问题解法
原问题。先看看 arr 长度为 2×3 的例子,下面列出了调整前和调整后数字的位置变化,以后都假设下标是从 1 开始的。
调整前的数字: a b c d e f
调整前的位置: 1 2 3 4 5 6
调整后的数字: d a e b f c
调整前的位置: 4 1 5 2 6 3
1 2 3 4 5 6
依然假设 arr 长度为 2×N,可以总结一下调整前的 i 位置上的数,在调整之后来到什么位置。如果调整前 i 在左半区(i≤N),调整之后会来到 2×i 位置;如果调整前 i 在右半区(i>N),调整之后会来到 2×(i-N)-1 位置,N=数组长度/2。
所以,可以写出一个函数来描述位置变化。
也就是说,原始位置 i 去往什么位置其实只由一个公式来决定。那么初始想法就是,能不能利用“下标连续推”的方式调整好所有的数字呢?我们举个例子解释什么叫“下标连续推”。
调整前的数字: a b c d
调整前的位置: 1 2 3 4
调整后的数字: c a d b
调整前的位置: 3 1 4 2
1 2 3 4
从 1 位置出发开始调整数组,位置变化的函数假设为 m。m(1)=2,所以 a 直接放在 2 位置上,并且把位于 2 位置的 b 推了出来。b 原来的位置是 2,m(2)=4,所以 b 直接放在 4 位置上,并且把位于 4 位置的 d 推了出来。d 原来的位置是 4,m(4)=3,所以 d 直接放在 3 位置上,并且把位于 3 位置的 c 推了出来。c 原来的位置是 3,m(3)=1,所以 c 直接放在 1 位置上,因为 1 位置就是最初的开始位置,所以“下标连续推”过程停止。所有数字都来到了正确的位置上,数组调整正确。
这个思路有点类似于一个环状的多米诺骨牌。从一张牌开始连续推倒下一张牌,最终还会回到原位置。之所以强调这是一个环,是因为不管从哪个位置出发,最后的位置一定能够来到出发的位置,并且“下标连续推”的过程只使用了几次 m 函数,并不需要任何中间状态被记录。但遗憾的是,对于任意长度为偶数的数组,可能由多条环组成。比如长度为 6 的数组,如下:
调整前的数字: a b c d e f
调整前的位置: 1 2 3 4 5 6
如果从 1 位置出发,每一步根据 m 函数来到下一个位置。那么“下标连续推”的过程:a(1)推出 b(2),b(2)推出 d(4),d(4)回到 1 位置,也就是 1->2->4->1 这条环。但是此时数组还有需要调整的数字。
还需要调整的数字(X 代表已经调整好的数组)为:X X c X e f。
所以还需要从 3 位置出发,再进行一轮“下标连续推”的过程:c(3)推出 f(6),f(6)推出 e(5),e(5)回到 3 位置。也就是 3->6->5->3 这条环。此时数组中所有的数字才调整完毕。
数组长度不同,环的数量也不同,并且任何一条环一定不和其他的环共享任何数字。如果在不记录哪些位置是经历过“下标连续推”过程的情况下,就要求我们必须找到一个简洁的公式,可以根据长度的值,直接算出每一条环的出发位置。然后从这些出发位置开始都经历一遍“下标连续推”。存在这样的公式吗?当然,即完美洗牌问题论文中的结论。如果数组长度为 2 * N=(3^k)-1,那么出发位置有 k 个,依次为 1,3,9,…3^(k-1),k≥1。比如数组长度为 2 时,2=3^1-1,所以出发位置只有 1 个,也就是 1 位置 3 0 3^0 30。比如数组长度为 8 时,8=3^2-1,所以出发位置有 2 个,依次为 1,3。比如数组长度为 26 时,26=3^3-1,所以出发位置有 3 个,依次为1,3,9。
可是这个结论只能解决数组长度为 3^k-1 的特殊情况,如果数组长度为一个普通的偶数,又该怎么解决呢?下面用一个例子来展示如果数组长度为一个普通的偶数该如何解决。比如数组长度为 12 的时候,数组如下:
L1 L2 L3 L4 L5 L6 R1 R2 R3 R4 R5 R6
目标调整成:
R1 L1 R2 L2 R3 L3 R4 L4 R5 L5 R6 L6
首先计算一下,小于或等于 12,并且是离 12 最近的,满足 3^k-1 的数是谁(2,8,26,…),是8。这代表想先得到调整结果的前 8 个,也就是想先得到:
R1 L1 R2 L2 R3 L3 R4 L4
为了做到这一点,先在原数组[L5 L6 R1 R2 R3 R4]这一段上做调整,在这一段上,认为左部分是[L5 L6],右部分是[R1 R2 R3 R4]。左部分放到这一段的右边,右部分放到这一段的左边。根据“翻转字符串”问题可以将数组先调整成:
L1 L2 L3 L4 R1 R2 R3 R4 L5 L6 R5 R6
此时数组的前 8 个数为[L1 L2 L3 L4 R1 R2 R3 R4],并且长度是满足 3^k-1 关系的,就可以利用之前的结论进行调整了。数组还没有调整的数字就是[L5 L6 R5 R6]这一段,长度为 4,如下所示(X 为已经调好不需要再考虑的位置):
X X X X X X X X L5 L6 R5 R6
长度为 12 的数组已经搞定了 8 个,还剩下 4 个。接下来计算一下小于或等于 4,并且是离4 最近的,满足 3^k-1 的数是谁(2,8,26,…),是 2。这代表想先在剩余的[L5 L6 R5 R6]中,得到调整结果的前 2 个[R5 L5]。为了做到这一点,在剩余的部分中先在[L6 R5]这一段上做调整。认为左部分是[L6],右部分是[R5]。左部分放到这一段的右边,右部分放到这一段的左边。剩余部分在调整之后就变成[L5 R5 L6 R6]。此时剩余部分的前 2 个数为[L5 R5],并且长度是满足 3^k-1 关系的,就可以利用之前的结论进行调整了。数组还没有调整的数字就剩[L6 R6]这一段了,长度为 2,如下所示(X 为已经调好不需要再考虑的位置):
X X X X X X X X X X L6 R6
最后这个部分是长度为 2 的,并且长度是满足 3^k-1 关系的,就可以利用之前的结论进行调整了。整个数组就调整完毕。
长度为一个任意的偶数,都一定可以把这个偶数拆成一块块长度满足 3^k-1 的部分。比如长度为 126,类比之前的流程,会先拆出长度为 80(即 3^4-1)的块先解决;剩余的长度为 46,再拆出长度为 26(即 3^3-1)的块解决;剩余长度为 20,再拆出长度为 8(即 3^2-1)的块解决;剩余长度为 12,接下来拆出的块为 8,2,2。任何一个偶数都可如此。每一个块解决之后,后续都不需要再碰了。
-
进阶问题:排序+完美洗牌结论+翻转字符串补充问题解法
进阶问题。首先把整个数组排序,比如堆排序。如果数组长度是偶数,然后把排序之后的数组调整成[L1 R1 L2 R2 … Ln Rn]即可。举个例子,比如 arr 排序之后是[1,2,3,4,5,6],调整成[1,4,2,5,3,6]就是题目要求的大小关系。完美洗牌问题能调整成[R1 L1 R2 L2 … Rn Ln],只再需要遍历一遍,把[R1 L1]、[R2 L2]、…、[Rn Ln]每一对里的两个数换一下位置即可。如果数组长度是奇数,arr[0]位置的数不用动,把后面剩下的长度为偶数的部分看作是[L1 L2 … Ln R1 R2 … Rn],然后用完美洗牌问题调整成[R1 L1 R2 L2 … Rn Ln]即可。举个例子,比如 arr 排序之后是[1,2,3,4,5],不管 1 这个数,剩下的部分是[2,3,4,5],调整成[4,2,5,3],那么数组整体变成[1,4,2,5,3],就是题目要求的大小关系。
【代码】
- 原问题
#include - 进阶问题
#include 删除多余字符得到字典序最小的字符串
【题目】
给定一个全是小写字母的字符串 str,删除多余字符,使得每种字符只保留一个,并让最终结果字符串的字典序最小。
例如:
str = “acbc”,删掉第一个’c’,得到"abc",是所有结果字符串中字典序最小的。
str = “dbcacbca”,删掉第一个’b’、第一个’c’、第二个’c’、第二个’a’,得到"dabc",是所有结果字符串中字典序最小的。
【解答】
-
不考虑删除而是考虑挑选+双指针
str 的结果字符串记为 res,假设 str 长度为 N,其中有 K 种不同的字符,那么 res 长度为 K。思路是怎么在 str 中从左到右依次挑选出 res[0]、res[1]、…、res[K-1]。举个例子,str[0…9]=“baacbaccac”,一共 3 种字符,所以要在 str 中从左到右依次找到 res[0…2]。
1.建立 str[0…9]的字频统计,b 有 2 个、a 有 4 个、c 有 4 个。
2.从左往右遍历 str[0…9],遍历到字符的字频统计减 1,当发现某一种字符的字频统计已经为 0 时,遍历停止。在例子中当遍历完"baacb"时,字频统计为 b 有 0 个、a 有 2 个、c 有 3个,发现 b 的字频已经为 0,所以停止遍历,当前遍历到 str[4]。str[5…9]为"accac"已经没有 b 了,而流程是在 str 中从左到右依次挑选出 res[0]、res[1]、res[2],所以,如果 str[5…9]中任何一个字符被挑选成为 res[0],之后过程是在挑选位置的右边继续挑选,那么一定会错过 b 字符,所以在str[0…4]上挑选 res[0]。
3.在 str[0…4]上找到字典序最小的字符,即 str[1]=‘a’,它就是 res[0]。
4.在挑选字符 str[1]的右边,字符串为"acbaccac",删掉所有的’a’字符变为"cbccc",令str=“cbccc”,下面找 res[1]。
5.建立 str[0…4]的字频统计,b 有 1 个、c 有 4 个。
6.从左往右遍历 str[0…4],遍历到字符的字频统计减 1,当发现某一种字符的字频统计已经为 0 时,遍历停止。当遍历完"cb"时,字频统计为 b 有 0 个、c 有 3 个,发现 b 的字频已经为0,所以停止遍历,当前遍历到 str[1]。str[2…4]为"ccc"已经没有 b 了,所以如果 str[2…4]中任何一个字符被挑选成为 res[1],之后的过程是在挑选位置的右边继续挑选,那么一定会错过 b 字符,所以在 str[0…1]上挑选 res[1]。
7.在 str[0…1]上找到字典序最小的字符,即 str[1]=‘b’,它就是 res[1]。
8.在挑选字符 str[1]的右边,字符串为"ccc",删掉所有的’b’字符,仍为"ccc",令 str=“ccc”,下面找 res[2]。
9.建立 str[0…2]的字频统计,c 有 3 个。
10.从左往右遍历 str[0…2],遍历到字符的字频统计减 1,当发现某一种字符的字频统计已经为 0 时,遍历停止。当遍历完"ccc"时,字频统计为 c,有 0 个,当前遍历到 str[2]。右边没有字符了,当然无法成为 res[2],所以在 str[0…2]上挑选 res[2]。
11.在 str[0…2]上找到字典序最小的字符,即 str[0]=‘c’,它就是 res[2]。整个过程结束。如上过程虽然是用例子来说明的,但是整个过程其实比较简单。根据字频统计,遍历 str 时找到一个前缀 str[0…R],然后在 str[0…R]中找到最小 ASCII 码的字符 str[X],就是结果字符串的当前字符。然后令 str=(str[X+1…R]去掉所有 str[X]得到的字符串),重复整个过程,找到结果字符串的下一个字符,直到 res 生成完毕。并且每找到一个 res[i],都要重新建立字频统计以及在整个字符串中删除已经找到的字符。
【代码】
#include 数组中两个字符串的最小距离
【题目】
给定一个字符串数组 strs,再给定两个字符串 str1 和 str2,返回在 strs 中 str1 与 str2 的最小距离,如果 str1 或 str2 为 null,或不在 strs 中,返回 -1。
例如:
strs=[“1”,“3”,“3”,“3”,“2”,“3”,“1”],str1=“1”,str2=“2”,返回 2。
strs=[“CD”],str1=“CD”,str2=“AB”,返回-1。
进阶问题:如果查询发生的次数有很多,如何尽量减少每次查询的时间复杂度?
【解答】
-
原问题:双指针
原问题。从左到右遍历 strs,用变量 last1 记录最近一次出现 str1 的位置,用变量 last2 记录最近一次出现 str2 的位置。如果遍历到 str1,那么 i-last2 的值就是当前的 str1 和左边离它最近的 str2 之间的距离。如果遍历到 str2,那么 i-last1 的值就是当前的 str2 和左边离它最近的 str1之间的距离。用变量 minValue 记录这些距离的最小值即可。
-
进阶问题:嵌套哈希表
进阶问题。通过数组 strs 先生成某种记录,在查询时通过记录进行查询。
实现的记录是一个哈希表 unordered_map
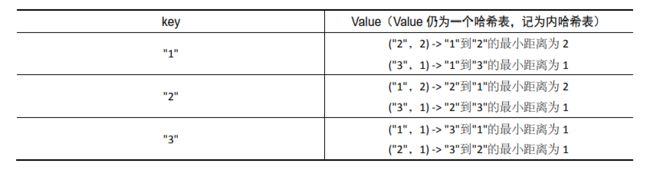
如果生成了这种结构的记录,那么查询 str1 和 str2 的最小距离时只用两次哈希查询操作就可以完成。
【代码】
- 原问题
#include - 进阶问题
#include 字符串的转换路径问题
【题目】
给定两个字符串,记为 start 和 to,再给定一个字符串列表 list,list 中一定包含 to,list 中没有重复字符串。所有的字符串都是小写的。规定 start 每次只能改变一个字符,最终的目标是彻底变成 to,但是每次变成的新字符串必须在 list 中存在。请返回所有最短的变换路径。
例如:
start=“abc”,end=“cab”,list={“cab”,“acc”,“cbc”,“ccc”,“cac”,“cbb”,“aab”,“abb”}转换路径的方法有很多种,但所有最短的转换路径如下:
abc -> abb -> aab -> cab
abc -> abb -> cbb -> cab
abc -> cbc -> cac -> cab
abc -> cbc -> cbb -> cab
【解答】
-
图的广度优先和深度优先遍历
步骤 1:把 start 加入 list,然后根据 list 生成每一个字符串的 nexts 信息。nexts 具体是指如果只改变一个字符,该字符串可以变成哪些字符串。比如,例子中的 list,先把"abc"加入 list,然后根据 list 生成信息如下:
字符串 nexts 信息 acc abc, ccc abb aab, cbb, abc ccc acc, cac, cbc cbb abb, cab, cbc abc abb, cbc, acc aab abb, cab cac cbc, cab, ccc cab aab, cbb, cac cbc abc, cac, cbb, ccc 如何生成每一个字符串的 nexts 信息呢?首先把 list 中所有的字符串放入哈希表 set 中,这样检查某个字符串是否在 list 中,就可以通过查询 set 来实现。后续过程举例说明,比如字符串"acc",要生成它的 nexts 信息。
因为所有的字符都是小写,所以看"bcc"、“ccc”、“dcc”、“ecc”…“zcc"哪些在 set 中,就把哪些放到"acc"的 nexts 列表里;然后看"aac”、“abc”、“adc”、“aec”…“azc"哪些在 set 中,就把哪些放到"acc"的 nexts 列表里;最后看"aca”、“acb”、“acd”、“ace”…"acz"哪些在 set 中,就把哪些放到"acc"的 nexts 列表里。也就是说,某个位置的字符都从 a~z 枚举,哪些在 set 中,就把哪些放到 nexts 列表里,但是不加入原始字符串。
步骤 2:有了每个字符串的 nexts 信息之后,相当于我们有了一张图,每个字符串相当于图中的一个点,nexts 信息相当于这个点的所有邻接节点。比如,步骤 1 生成了所有字符串的 nexts 信息,相当于得到了下图。
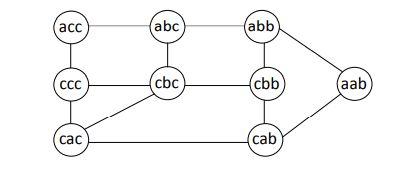
接下来从 start 字符串出发,利用 nexts 信息和宽度优先遍历的方式,求出每一个字符串到 start 的最短距离。上图中从"abc"出发,生成的距离信息如下:
字符串 到 start 的最短距离 abb 1 acc 1 cbb 2 ccc 2 abc 0 aab 2 cac 2 cbc 1 cab 3 步骤 3:从 start 出发往下走,保证每一步走到的字符串 cur 到 start 的最短距离都在加 1。如果能走到 to,收集整条路。用例子来说明,从"abc"出发,情况如下图所示。
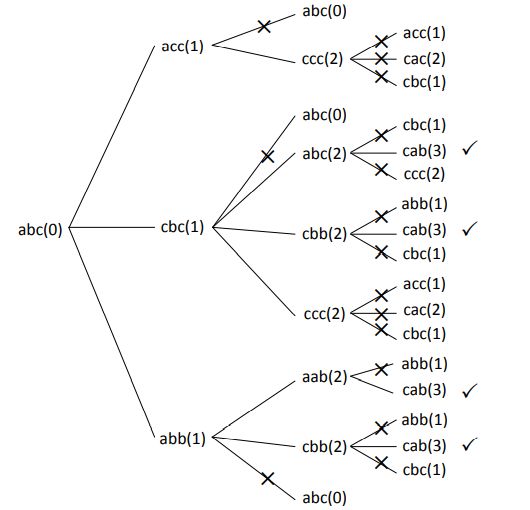
上图中从"abc"出发,每一步都通过字符串的 nexts 信息往下走,但是必须保证到 start 的最短距离是+1 递增的。图中画叉号的路都是因为最短距离没有+1 递增而终止了,最后画对号的是在走的过程中遇到了 to,整条路应该记录下来。整个过程是标准的深度优先遍历,往下走的过程中,因为有最短距离要不停+1 递增的限制,所以走的岔路不可能无穷尽地展开,也不可能形成环。与题目的例子一样,答案为4条最短路径。
【代码】
#include 添加最少字符使字符串整体都是回文字符串
【题目】
给定一个字符串 str,如果可以在 str 的任意位置添加字符,请返回在添加字符最少的情况下,让 str 整体都是回文字符串的一种结果。
例如:
str=“ABA”。str 本身就是回文串,不需要添加字符,所以返回"ABA"。
str=“AB”。可以在’A’之前添加’B’,使 str 整体都是回文串,故可以返回"BAB"。也可以在’B’之后添加’A’,使 str 整体都是回文串,故也可以返回"ABA"。总之,只要添加的字符数最少,返回其中一种结果即可。
进阶问题:给定一个字符串 str,再给定 str 的最长回文子序列字符串 strlps,请返回在添加字符最少的情况下,让 str 整体都是回文字符串的一种结果。
例如:
str=“A1B21C”,strlps=“121”,返回"AC1B2B1CA"或者"CA1B2B1AC"。总之,只要是添加的字符数最少,只返回其中一种结果即可。
【解答】
-
原问题:动态规划+双指针
原问题。在求解原问题之前,我们先来解决下面这个问题,如果可以在 str 的任意位置添加字符,最少需要添几个字符可以让 str 整体都是回文字符串。这个问题可以用动态规划的方法求解。如果 str 的长度为 N,动态规划表是一个 N×N 的矩阵,记为 dp[][]。dp[i] [j]值的含义代表子串 str[i…j]最少添加几个字符可以使 str[i…j]整体都是回文串。那么,如何求 dp[i] [j]的值呢?有如下三种情况:
- 字符串 str[i…j]只有一个字符,此时 dp[i] [j]=0,这是很明显的,如果 str[i…j]只有一个字符,那么 str[i…j]已经是回文串了,自然不必添加任何字符。
- 字符串 str[i…j]只有两个字符且两个字符相等,那么 dp[i] [j]=0。比如,如果 str[i…j]为"AA",两字符相等,说明 str[i…j]已经是回文串,自然不必添加任何字符。如果两个字符不相等,那么 dp[i] [j]=1。比如,如果 str[i…j]为"AB",只用添加一个字符就可以令 str[i…j]变成回文串,所以 dp[i] [j]=1。
- 字符串 str[i…j]多于两个字符。如果 str[i]=str[j],那么 dp[i] [j]=dp[i+1] [j-1]。比如,如果str[i…j]为"A124521A",str[i…j]需要添加的字符数与 str[i+1…j-1](即"124521")需要添加的字符数是相等的,因为只要能把"124521"整体变成回文串,然后在左右两头加上字符’A’,就是 str[i…j]整体变成回文串的结果。如果 str[i]!=str[j],要让 str[i…j]整体变为回文串有两种方法,一种方法是让 str[i…j-1]先变成回文串,然后在左边加上字符 str[j],就是 str[i…j]整体变成回文串的结果。另一种方法是让 str[i+1…j]先变成回文串,然后在右边加上字符 str[i],就是 str[i…j]整体变成回文串的结果。两种方法中,哪个代价最小就选择哪个,即 dp[i] [j] = min { dp[i] [j-1] , dp[i+1] [j] }+1。
既然 dp[i] [j]值代表子串 str[i…j]最少添加几个字符可以使 str[i…j]整体都是回文串,所以根据上面的方法求出整个 dp 矩阵之后,就得到了 str 中任何一个子串添加几个字符后可以变成回文串。
下面介绍如何根据 dp 矩阵,求在添加字符最少的情况下,让 str 整体都是回文字符串的一种结果。首先,dp[0] [N-1]的值代表整个字符串最少需要添加几个字符,所以,如果最后的结果记为字符串 res,res 的长度=dp[0] [N-1]+str 的长度,然后依次设置 res 左右两头的字符。具体过程如下:
1.如果 str[i…j]中 str[i]=str[j],那么 str[i…j]变成回文串的最终结果=str[i]+str[i+1…j-1]变成回文串的结果+str[j],此时 res 左右两头的字符为 str[i](也是 str[j]),然后继续根据 str[i+1…j-1]和矩阵 dp 来设置 res 的中间部分。
2.如果 str[i…j]中 str[i]!=str[j],看 dp[i] [j-1]和 dp[i+1] [j]哪个小。如果 dp[i] [j-1]更小,那么 str[i…j]变成回文串的最终结果=str[j]+str[i…j-1]变成回文串的结果+str[j],所以此时 res 左右两头的字符为str[j],然后继续根据 str[i…j-1]和矩阵 dp 来设置 res 的中间部分。如果 dp[i+1] [j]更小,那么 str[i…j]变成回文串的最终结果=str[i]+str[i+1…j]变成回文串的结果+str[i],所以此时 res 左右两头的字符为 str[i],然后继续根据 str[i+1…j]和矩阵 dp 来设置 res 的中间部分。如果相等,任选一种设置方式都可以得出最终结果。
3.如果发现 res 所有的位置都已设置完毕,过程结束。
-
进阶问题:双指针
进阶问题。如果 str 的长度为 N,strlps 的长度为 M,则整体回文串的长度应该是 2×N-M。该解法类似“剥洋葱”的过程,给出如下示例来具体说明:
str=“A1BC22DE1F”,strlps = “1221”。res=…长度为 2×N-M…
洋葱的第 0 层由 strlps[0]和 strlps[M-1]组成,即"1…1"。从 str 最左侧开始找字符’1’,发现’A’是 str 第 0 个字符,‘1’是 str 第 1 个字符,所以左侧第 0 层洋葱圈外的部分为"A",记为 leftPart。从 str 最右侧开始找字符’1’,发现右侧第 0 层洋葱圈外的部分为"F",记为 rightPart。把 leftPart+(rightPart的逆序)复制到 res 左侧未设值的部分,把 rightPart+(leftPart的逆序)复制到 res 的右侧未设值的部分,即 res 变为"AF…FA"。把洋葱的第 0 层复制进 res 的左右两侧未设值的部分,即 res 变为"AF1…1FA"。至此,洋葱第 0 层被剥掉。洋葱的第 1 层由 strlps[1]和strlps[M-2]组成,即"2…2"。从 str 左侧的洋葱第 0 层往右找"2",发现左侧第 1 层洋葱圈外的部分为"BC",记为 leftPart。从 str 右侧的洋葱第 0 层往左找"2",发现右侧第 1 层洋葱圈外的部分为"DE",记为 rightPart。把 leftPart+(rightPart的逆序)复制到 res 左侧未设值的部分,把 rightPart+(leftPart的逆序)复制到 res 的右侧未设值的部分,res 变为"AF1BCED…DECB1FA"。把洋葱的第 1 层复制进 res 的左右两侧未设值的部分,即 result 变为"AF1BCED2…2DECB1FA"。第 1 层被剥掉,洋葱剥完了,返回"AF1BCED22DECB1FA"。整个过程就是不断找到洋葱圈的左部分和右部分,把 leftPart+(rightPart的逆序)复制到 res 左侧未设值的部分,把 rightPart+(leftPart的逆序)复制到 res 的右侧未设值的部分,洋葱剥完则过程结束。
【代码】
- 原问题
#include - 进阶问题
#include 括号字符串的有效性和最长有效长度
【题目】
给定一个字符串 str,判断是不是整体有效的括号字符串。
例如:
str=“()”,返回 true。
str=“(()())”,返回 true。
str=“(())”,返回 true。
str=“())”。返回 false。
str=“()(”,返回 false。
str=“()a()”,返回 false。
补充问题:给定一个括号字符串 str,返回最长的有效括号子串。
例如:
str=“(()())”,返回 6。
str=“())”,返回 2。
str=“()(()()(”,返回 4。
【解答】
-
原问题:遍历
原问题。判断过程如下:
1.从左到右遍历字符串 str,判断每一个字符是不是’(‘或’)',如果不是,就直接返回 false。
2.遍历到每一个字符时,都检查到目前为止’(‘和’)‘的数量,如果’)'更多,则直接返回 false。
3.遍历后检查’(‘和’)'的数量,如果一样多,则返回 true,否则返回 false。
-
补充问题:动态规划
补充问题。首先生成长度和 str 字符串一样的数组 dp[],dp[i]值的含义为 str[0…i]中必须以字符 str[i]结尾的最长的有效括号子串长度。那么 dp[i]值可以按如下方式求解:
1.dp[0]=0。只含有一个字符肯定不是有效括号字符串,长度自然是 0。
2.从左到右依次遍历 str[1…N-1]的每个字符,假设遍历到 str[i]。
3.如果 str[i]=‘(’,有效括号字符串必然是以’)‘结尾,而不是以’('结尾,所以 dp[i] = 0。
4.如果 str[i]=‘)’,那么以 str[i]结尾的最长有效括号子串可能存在。dp[i-1]的值代表必须以str[i-1]结尾的最长有效括号子串的长度,所以,如果 i-dp[i-1]-1 位置上的字符是’(‘,就能与当前位置的 str[i]字符再配出一对有效括号。比如"(()())",假设遍历到最后一个字符’)‘,必须以倒数第二个字符结尾的最长有效括号子串是"()()",找到这个子串之前的字符,即 i-dp[i-1]-1 位置的字符,发现是’(‘,所以它可以和最后一个字符再配出一对有效括号。如果该情况发生,dp[i]的值起码是 dp[i-1]+2,但还有一部分长度容易被人忽略。比如,“()(())”,假设遍历到最后一个字符’)',通过上面的过程找到的必须以最后字符结尾的最长有效括号子串起码是"(())“,但是前面还有一段”()“,可以和”(())"结合在一起构成更大的有效括号子串。也就是说,str[i-dp[i-1]-1]和 str[i]配成了一对,这时还应该把 dp[i-dp[i-1]-2]的值加到 dp[i]中,这么做表示把 str[i-dp[i-1]-2]结尾的最长有效括号子串接到前面,才能得到以当前字符结尾的最长有效括号子串。
5.dp[0…N-1]中的最大值就是最终结果。
【代码】
- 原问题
#include - 补充问题
#include 公式字符串求值
【题目】
给定一个字符串 str,str 表示一个公式,公式里可能有整数、加减乘除符号和左右括号,返回公式的计算结果。
说明:
1.可以认为给定的字符串一定是正确的公式,即不需要对 str 做公式有效性检查。
2.如果是负数,就需要用括号括起来,比如"4 * (-3)“。但如果负数作为公式的开头或括号部分的开头,则可以没有括号,比如”-3 * 4"和"(-3 * 4)"都是合法的。
3.不用考虑计算过程中会发生溢出的情况。
例如:
str=“48 * ((70-65)-43)+8 * 1”,返回 -1816。
str=“3+1 * 4”,返回 7。str=“3+(1 * 4)”,返回 7。
【解答】
-
递归+使用deque
假设 value 方法是一个递归过程,具体解释如下。
从左到右遍历 str,开始遍历或者遇到字符’(‘时,就进行递归过程。当发现 str 遍历完,或者遇到字符’)‘时,递归过程就结束。比如"3 * (4+5)+7",一开始遍历就进入递归过程 value(str,0),在递归过程 value(str,0)中继续遍历 str,当遇到字符’(‘时,递归过程 value(str,0)又重复调用递归过程 value(str,3)。然后在递归过程 value(str,3)中继续遍历 str,当遇到字符’)'时,递归过程 value(str,3)结束,并向递归过程 value(str,0)返回两个结果,第一结果是 value(str,3)遍历过的公式字符子串的结果,即"4+5"=9,第二个结果是 value(str,3)遍历到的位置,即字符")“的位置=6。递归过程 value(str,0)收到这两个结果后,既可知道交给 value(str,3)过程处理的字符串结果是多少(”(4+5)"的结果是 9),又可知道自己下一步该从什么位置继续遍历(该从位置 6 的下一个位置(即位置 7)继续遍历)。总之,value 方法的第二个参数代表递归过程是从什么位置开始的,返回的结果是一个长度为 2 的数组,记为 res。res[0]表示这个递归过程计算的结果,res[1]表示这个递归过程遍历到 str 的什么位置。
既然在递归过程中遇到’(‘就交给下一层的递归过程处理,自己只用接收’(‘和’)‘之间的公式字符子串的结果,所以对所有的递归过程来说,可以看作计算的公式都是不含有’(‘和’)‘字符的。比如,对递归过程 value(str,0)来说,实际上计算的公式是"3 * 9+7","(4+5)"的部分交给递归过程 value(str,3)处理,拿到结果 9 之后,再从字符’+‘继续。所以,只要想清楚如何计算一个不含有’(‘和’)'的公式字符串,整个实现就完成了。
【代码】
#include 0 左边必有 1 的二进制字符串数量
【题目】
给定一个整数 N,求由"0"字符与"1"字符组成的长度为 N 的所有字符串中,满足"0"字符的左边必有"1"字符的字符串数量。
例如:
N=1。只由"0"与"1"组成,长度为 1 的所有字符串:“0”、“1”。只有字符串"1"满足要求,所以返回 1。
N=2。只由"0"与"1"组成,长度为 2 的所有字符串为:“00”、“01”、“10”、“11”。只有字符串"10"和"11"满足要求,所以返回 2。
N=3。只由"0"与"1"组成,长度为 3 的所有字符串为:“000”、“001”、“010”、“011”、“100”、“101”、“110”、“111”。字符串"101"、“110”、"111"满足要求,所以返回 3。
【解答】
-
法一:暴力递归
假设第 0 位的字符为最高位字符,很明显,第 0 位的字符不能为’0’。假设 p(i)表示 0~i-1 位置上的字符已经确定,这一段符合要求且第 i-1 位置的字符为’1’时,如果穷举 i~N-1位置上的所有情况会产生多少种符合要求的字符串。比如 N=5,p(3)表示 0~2 位置上的字符已经确定,这一段符合要求且位置 2 上的字符为’1’时,假设为"101…“。在这种情况下,穷举 3、4位置所有可能的情况会产生多少种符合要求的字符串,因为只有"10101”、“10110"和"10111”,所以 p(3)=3。也可以假设前三位是"111…",p(3)同样等于 3。有了 p(i)的定义,同时知道不管 N是多少,最高位的字符只能为’1’,那么只要求出 p(1),就是所有符合要求的字符串数量。
那到底 p(i)应该怎么求呢?根据 p(i)的定义,在位置 i-1 的字符已经为’1’的情况下,位置 i 的字符可以是’1’,也可以是’0’。如果位置 i 的字符是’1’,那么穷举剩下字符的所有可能性,并且符合要求的字符串数量就是 p(i+1)的值。如果位置 i 的字符是’0’,那么位置 i+1 的字符必须是’1’,穷举剩下字符的所有可能性,符合要求的字符串数量就是 p(i+2)的值。所以 p(i)=p(i+1)+p(i+2)。p(N-1)表示除了最后位置的字符,前面的子串全符合要求,并且倒数第二个字符为’1’,此时剩下的最后一个字符既可以是’1’,也可以是’0’,所以 p(N-1)=2。p(N)表示所有的字符串已经完全确定,并且符合要求,最后一个字符(N-1)为’1’,所以,此时符合要求的字符串数量就是 0~N-1 的全体,而不再有后续的可能性,所以 p(N)=1。即 p(i)如下:
i < N-1 时,p(i) = p(i+1)+p(i+2)
i = N-1 时,p(i) = 2
i = N 时,p(i) = 1
很明显,可以写成递归方法。
-
法二:类斐波那契数列
当 N 分别为 1,2,3,4,5,6,7,8 时,结算的结果为 1,2,3,5,8,13,21,34。可以看出,这就是一个形如斐波那契数列的结果,唯一的区别就是斐波那契数列的初始项为 1,1。而这个数列的初始项为 1,2。
【代码】
- 法一
#include - 法二
#include 拼接所有字符串产生字典顺序最小的大写字符串
【题目】
给定一个字符串类型的数组 strs,请找到一种拼接顺序,使得将所有的字符串拼接起来组成的大字符串是所有可能性中字典顺序最小的,并返回这个大字符串。
例如:
strs=[ “abc”,“de” ],可以拼成"abcde",也可以拼成"deabc",但前者的字典顺序更小,所以返回"abcde"。
strs=[“b”,“ba” ],可以拼成"bba",也可以拼成"bab",但后者的字典顺序更小,所以返回"bab"。
【解答】
-
贪心+排序
有一种思路为:先把 strs 中的字符串按照字典顺序排序,然后将串起来的结果返回。这么做是错误的,比如题目中的例子 2,按照字典排序结果是 b、ba,串起来的大写字符串为"bba",但是字典顺序最小的大写字符串是"bab",所以按照单个字符串的字典顺序进行排序的想法是行不通的。如果要排序,应该按照下文描述的标准进行排序。
假设有两个字符串,分别记为 a 和 b,a 和 b 拼起来的字符串表示为 a.b。那么如果 a.b 的字典顺序小于 b.a,就把字符串 a 放在前面,否则把字符串 b 放在前面。每两个字符串之间都按照这个标准进行比较,以此标准排序后,再依次串起来的大字符串就是结果。这样做为什么对呢?当然需要证明。
证明的关键步骤是证明这种比较方式具有传递性。
假设有 a、b、c 三个字符串,它们有如下关系:
a.b < b.a
b.c < c.b
如果能够根据上面两式证明出 a.c < c.a,说明这种比较方式具有传递性,证明过程如下:
字符串的本质是 K 进制数,比如,只由字符’a’~'z’组成的字符串其实可以看作 26 进制数。那么字符串 a.b 这个数可以看作 a 是它的高位,b 是低位,即 a.b=a * K 的 b 长度次方+b。举一个十进制数的例子,x=123,y=6789,x.y=x * 10000+y=1230000+6789,其中,10000=10 的 4 次方,4 是 y 的长度。为了让证明过程便于阅读,我们把“K 的 b 长度次方”记为 k(b)。则原来的不等式可化简为:
a.b < b.a => a * k(b) + b < b * k(a) + a(不等式 1)
b.c < c.b => b * k© + c < c * k(b) + b(不等式 2)
现在要证明 a.c < c.a,即证明 a * k© + c < c * k(a) + a。
不等式 1 的左右两边同时减去 b,再乘以 c,变为 a * k(b) * c < b * k(a) * c + a * c - b * c。
不等式 2 的左右两边同时减去 b,再乘以 a,变为 b * k© * a + c * a - b * a < c * k(b) * a。
a,b,c 是 K 进制数,服从乘法交换律,有 a * k(b) * c = c * k(b) * a,所以有如下不等式:
b * k© * a + c * a - b * a < c * k(b) * a = a * k(b) * c < b * k(a) * c + a * c - b * c
=> b * k© * a + c * a - b * a < b * k(a) * c + a * c - b * c
=> b * k© * a - b * a < b * k(a) * c - b * c
=> a * k© - a < c * k(a) - c
=> a * k© + c < c * k(a) + a
即 a.c < c.a,传递性证明完毕。
证明传递性后,还需要证明通过这种比较方式排序后,如果交换任意两个字符串的位置所得到的总字符串,将拥有更大的字典顺序。
假设通过如上比较方式排序后,得到字符串的序列为:
…A.M1.M2…M(n-1).M(n).L…
该序列表示,代号为 A 的字符串之前与代号为 L 的字符串之后都有若干字符串用“…”表示,A 和 L 中间有若干字符串,用 M1…M(n)。现在交换 A 和 L 这两个字符串,交换之前和交换之后两个总字符串就分别为:
…A.M1.M2…M(n-1).M(n).L… 换之前
…L.M1.M2…M(n-1).M(n).A… 换之后
现在需要证明交换之后的总字符串字典顺序大于交换之前的,具体过程如下。
在排好序的序列中,M1 排在 L 的前面,所以有 M1.L < L.M1,进一步有:
…L.M1.M2…M(n-1).M(n).A… > …M1.L.M2…M(n-1).M(n).A…
在排好序的序列中,M2 排在 L 的前面,所以有 M2.L < L.M2,进一步有:
…M1.L.M2…M(n-1).M(n).A… > …M1.M2.L…M(n-1).M(n).A…
在排好序的序列中,M(i)排在 L 的前面,所以有 M(i).L < L.M(i),进一步有:
…M1.M2…L.M(i)…M(n-1).M(n).A… > …M1.M2…M(i).L…M(n-1).M(n).A…
最终,…M1.M2…M(n-1).M(n).L.A… > …M1.M2…M(n-1).M(n).A.L…
在排好序的序列中,A 排在 M(n)的前面,所以有 A.M(n) < M(n).A,进一步有:
…M1.M2…M(n-1).M(n).A.L… > …M1.M2…M(n-1).A.M(n).L…
在排好序的序列中,A 排在 M(n-1)的前面,所以有 A.M(n-1) < M(n-1).A,进一步有:
…M1.M2…M(n-1).A.M(n).L… > …M1.M2…A.M(n-1).M(n).L…
最终,…M1.A.M2…M(n-1).M(n).L… > …A.M1.M2…M(n-1).M(n).L…
所以,…A.M1.M2…M(n-1).M(n).L…< …M1.A.M2…M(n-1).M(n).L… < …M1.M2.A…M(n-1).M(n).L… < … < …M1.M2…M(n-1).M(n).A.L… < …M1.M2…M(n-1).M(n).L.A… < … < …L.M1.M2…M(n-1).M(n).A…
解法有效性证明完毕。
【代码】
#include 找到字符串的最长无重复字符子串
【题目】
给定一个字符串 str,返回 str 的最长无重复字符子串的长度。
例如:
str=“abcd”,返回 4。
str=“aabcb”,最长无重复字符子串为"abc",返回 3。
【解答】
-
哈希表或数组+遍历
1.在遍历 str 之前,先申请几个变量。哈希表 map,key 表示某个字符,value 为这个字符最近一次出现的位置。整型变量 pre,如果当前遍历到字符 str[i],pre 表示在必须以 str[i-1]字符结尾的情况下,最长无重复字符子串开始位置的前一个位置,初始时 pre=-1。整型变量 len,记录以每一个字符结尾的情况下,最长无重复字符子串长度的最大值,初始时,len=0。从左到右依次遍历 str,假设现在遍历到 str[i],接下来求在必须以 str[i]结尾的情况下,最长无重复字符子串的长度。
2.map(str[i])的值表示之前的遍历中最近一次出现 str[i]字符的位置,假设在 a 位置。想要求以 str[i]结尾的最长无重复子串,a 位置必然不能包含进来,因为 str[a]等于 str[i]。
3.根据 pre 的定义,pre+1 表示在必须以 str[i-1]字符结尾的情况下,最长无重复字符子串的开始位置。也就是说,以 str[i-1]结尾的最长无重复子串是向左扩到 pre 位置停止的。
4.如果 pre 位置在 a 位置的左边,因为 str[a]不能包含进来,而 str[a+1…i-1]上都是不重复的,所以以 str[i]结尾的最长无重复字符子串就是 str[a+1…i]。如果 pre 位置在 a 位置的右边,以str[i-1]结尾的最长无重复子串是向左扩到 pre 位置停止的。所以以 str[i]结尾的最长无重复子串向左扩到 pre 位置也必然会停止,而且 str[pre+1…i-1]这一段上肯定不含有 str[i],所以以 str[i]结尾的最长无重复字符子串就是 str[pre+1…i]。
5.计算完长度之后,pre 位置和 a 位置哪一个在右边,就作为新的 pre 值。然后计算下一个位置的字符,整个过程中求得所有长度的最大值用 len 记录下来返回即可。
【代码】
#include 找到指定的新类型字符
【题目】
新类型字符的定义如下:
1.新类型字符是长度为 1 或者 2 的字符串。
2.表现形式可以仅是小写字母,例如"e";也可以是大写字母+小写字母,例如"Ab";还可以是大写字母+大写字母,例如"DC"。
现在给定一个字符串 str,str 一定是若干新类型字符正确组合的结果。比如"eaCCBi",由新类型字符"e"、“a”、"CC"和"Bi"拼成。再给定一个整数 k,代表 str 中的位置。请返回被 k 位置指定的新类型字符。
例如:
str=“aaABCDEcBCg”。
1.k=7 时,返回"Ec"。
2.k=4 时,返回"CD"。
3.k=10 时,返回"g"。
【解答】
-
只从所求点入手
一种笨方法是从 str[0]开始,从左到右依次划分出新类型字符,到 k 位置的时候就知道指向的新类型字符是什么。比如 str=“aaABCDEcBCg”,k=7。从左到右可以依次划分出"a"、“a”、“AB”、“CD”。然后发现 str[7]是大写字母’E’,所以被指定的新类型字符一定是"Ec",返回即可。
更快的方法。从 k-1 位置开始,向左统计连续出现的大写字母的数量记为 uNum,遇到小写字母就停止。如果 uNum 为奇数,str[k-1…k]是被指定的新类型字符,见例子 1。如果 uNum 为偶数且 str[k]是大写字母,str[k…k+1]是被指定的新类型字符,见例子 2。如果 uNum 为偶数且 str[k]是小写字母,str[k]是被指定的新类型字符,见例子 3。
【代码】
#include 旋变字符串问题
【题目】
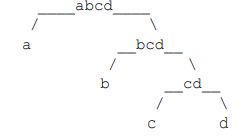
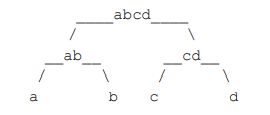
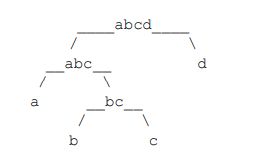
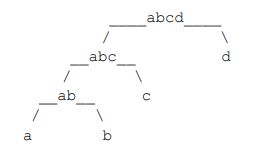
一个字符串可以分解成多种二叉树结构。如果 str 长度为 1,认为不可分解;如果 str 长度为 N(N>1),左部分长度可以为 1~N-1,剩下的为右部分的长度。左部分和右部分都可以按照同样的逻辑,继续分解。形成的所有结构都是 str 的二叉树结构。比如,字符串"abcd",可以分解成五种结构,分别如下图所示。
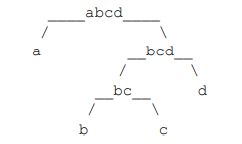
任何一个 str 的二叉树结构中,如果两个节点有共同的父节点,那么这两个节点可以交换位置,这两个节点叫作一个交换组。一个结构会有很多交换组,每个交换组都可以选择进行交换或者不交换,最终形成一个新的结构,这个新结构所代表的字符串叫作 str 的旋变字符串。比如,在上面最后一张图中的交换组有 a 和 b、ab 和 c、abc 和 d,如果让 a 和 b 的组交换,让 ab 和 c 的组不交换,让 abc 和 d 的组交换,形成的结构如下图所示。
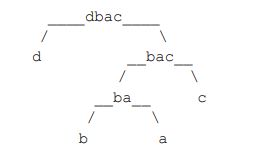
这个新结构所代表的字符串为"dbac",叫作"abcd"的旋变字符串。也就是说,一个字符串 str 的旋变字符串是非常多的,str 可以形成很多种结构,每一种结构都有很多交换组,每一个交换组都可以选择交换或者不交换,形成的每一个新的字符串都叫 str 的旋变字符串。
给定两个字符串 str1 和 str2,判断 str2 是不是 str1 的旋变字符串。
【解答】
-
法一:暴力递归
首先判断 str1 和 str2 包含的字符种类是否一样且每一种字符出现的数量也一样,如果不满足,str2 一定不是 str1 的旋变字符串,这是显而易见的。这时可能会根据如此灵活的旋变变化猜一个结论:str1 所有字符的全排列中,每一种都是 str1 的旋变字符串。但是这个猜测是不对的,比如 str1=“abcd”,str2=“cadb”,str2 就不是 str1 的旋变字符串,理由如下。
1.如果让"abcd"最开始划分的左部分为"abc",右部分为"d",想要最终得到"cadb",'c’就要在’d’的左边。所以左部分和右部分不能交换,这样左部分的’b’就会继续留在’d’的左边。但是在最终结果中,'b’在’d’的右边。所以这种划分无论怎么变换都不能得到"cadb"。
2.如果让"abcd"最开始划分的左部分为"ab",右部分为"cd",想要最终得到"cadb",'c’就要在’a’的左边。所以左部分和右部分必须交换,这样左部分的’a’就会移动到右部分’d’的右边。但是在最终结果中,'a’在’d’的左边。所以这种划分无论怎么变换都不能得到"cadb"。
3.如果让"abcd"最开始划分的左部分为"a",右部分为"cbd",想要最终得到"cadb",'c’就要在’a’的左边,所以左部分和右部分必须交换,这样右部分的’b’和’d’就会移动到左部分’a’的左边。但是在最终结果中,'b’和’d’在’a’的右边。所以这种划分无论怎么变换都不能得到"cadb"。
以上三种情况已经穷举了"abcd"第一次分割的所有可能性,"abcd"没有旋变出"cadb"的可能性。进而可以说明,str1 所有字符的全排列中,每一种都是 str1 旋变字符串的猜测是不成立的。
要判断 str2 是否是 str1 的旋变字符串,思路是尝试每一种 str1 的初次划分。比如,如果 str1 和 str2 长度为 N,判断str1[0…N-1]和 str2[0…N-1]是否互为旋变字符串的过程如下:
0,如果 str1[0…0]和 str2[0…0]互为旋变,并且 str1[1…N-1]和 str2[1…N-1]互为旋变,则 str1 和 str2 互为旋变字符串;如果 str1[0…0]和 str2[N-1…N-1]互为旋变,并且 str1[1…N-1]和 str2[0…N-2]互为旋变,则 str1 和 str2 互为旋变字符串。
1,如果 str1[0…1]和 str2[0…1]互为旋变,并且 str1[2…N-1]和 str2[2…N-1]互为旋变,则 str1 和 str2 互为旋变字符串;如果 str1[0…1]和 str2[N-2…N-1]互为旋变,并且 str1[2…N-1]和 str2[0…N-3]互为旋变,则 str1 和 str2 互为旋变字符串。
……
i,如果 str1[0…i]和 str2[0…i]互为旋变,并且 str1[i+1…N-1]和 str2[i+1…N-1]互为旋变,则 str1和 str2 互为旋变字符串;如果 str1[0…i]和 str2[N-i-1…N-1]互为旋变,并且 str1[i+1…N-1]和 str2[0…N-i-2]互为旋变,则 str1 和 str2 互为旋变字符串。
……
N-2,如果 str1[0…N-2]和 str2[0…N-2]互为旋变,并且 str1[N-1…N-1]和 str2[N-1…N-1]互为旋变,则 str1 和 str2 互为旋变字符串;如果 str1[0…N-2]和 str2[1…N-1]互为旋变,并且 str1[N-1…N-1]和 str2[0…0]互为旋变,则 str1 和 str2 互为旋变字符串。
N-1,如果 str1[0…N-1]和 str2[0…N-1]每个对应位置上的字符都相等,则 str1 和 str2 互为旋变字符串。
一共枚举 N 种情况,有一个可以算出是旋变就返回 true,都算不出就返回 false。
根据如上分析,现在推广到这样一个问题,判断 str1[从 L1 开始往右长度为 size 的子串]和str2[从 L2 开始往右长度为 size 的子串]是否互为旋变字符串。
最终答案是 str1[从 0 开始往右长度为 N 的子串]和 str2[从 0 开始往右长度为 N 的子串]是否互为旋变字符串。
-
法二:动态规划
前提是尝试过程是无后效性的。process(L1, L2, size)解决的问题就是 str1[从 0 开始往右长度为 N 的子串]和str2[从 0 开始往右长度为 N 的子串]是否互为旋变字符串,不管如何到达process(L1, L2, size)状态,返回值一定是固定的。
1)可变参数 L1、L2、size 一旦确定,返回值就确定了。
2)如果可变参数 L1、L2、size 组合的所有情况组成一张表,这张表一定可以装下所有的返回值。假设 str1 和 str2 长度为 N,L1 和 L2 变量的含义分别是 str1 中的位置和 str2 中的位置,所以 L1 和 L2 一定不会在 0~N-1 的范围之外。size 的含义是长度为 size 的子串,所以 size 一定不会在 1~N 的范围之外。那么这三个参数的全部组合构成一个立方体如下图所示。
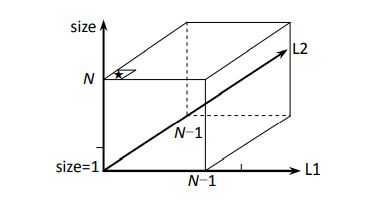
因为 size 不会等于 0,所以 size=0 的那一层二维平面也就是立方体中的最底层,是永远不会被使用到的。任何一个状态 process(L1, L2, size)都一定可以放在这个立方体中,记为dp[N] [N] [N+1],第一维对应 L1,第二维对应 L2,第三维(高)对应 size。
3)我们要的最终状态是 process(0,0,N),也就是 dp[0] [0] [N]的值,在图中已经用星号标出。那么如何求出这个值呢?
4)根据 process(L1, L2, size)函数的 base case,填写初始的位置:size=1 时,就是上图中 size=1 时由 L1 和 L2 的轴组成的二维平面。
5)base case 之外的情况都是普遍位置。而 process(a, b, size)依赖的子状态的假设为 process(c,d,size’),size’ 总是小于 size的。这说明如果来到 dp[a] [b] [k]位置,这个位置在计算时所依赖的状态一定位于 k 层二维平面的下方,即依赖 size
6)返回 dp[0] [0] [N]的值就是答案。
【代码】
- 法一
#include - 法二
#include 最小包含子串的长度
【题目】
给定字符串 str1 和 str2,求 str1 的子串中含有 str2 所有字符的最小子串长度。
例如:
str1=“abcde”,str2=“ac”。因为"abc"包含 str2 所有的字符,并且在满足这一条件的 str1 的所有子串中,"abc"是最短的,返回 3。
str1=“12345”,str2=“344”。最小包含子串不存在,返回 0。
【解答】
-
滑动窗口
假设 str1 的长度为 N,str2 的长度为 M。
如果 str1 或者 str2 为空,或者 N 小于 M,那么最小包含子串必然不存在,直接返回 0。接下来讨论一般情况,即 str1 和 str2 不为空且 N 不小于 M。为了便于理解,现在以 str1=“adabbca”、str2="acb"来举例说明整个过程。
1.在开始遍历 str1 之前,先通过遍历 str2 生成哈希表(或数组) map 的一些记录如下:
key value ‘a’ 1 ‘b’ 1 ‘c’ 1 哈希表记为 map,key 为 char 类型,value 为 int 型。每条记录的意义是,对于 key 字符,str1 字符串目前还欠 str2 字符串 value 个。
2.需要定义如下 4 个变量。
1)left:遍历 str1 的过程中,str1[left…right]表示被框住的子串,所以 left 表示这个子串的左边界,初始时,left=0。
2)right:right 表示被框住子串的右边界,初始时,right=0。
3)match:表示对所有的字符来说,str1[left…right]目前一共欠 str2 多少个。对本例来说,初始时,match=3,即开始时欠 1 个’a’、1 个’c’和 1 个’b’。
4)minLen:最终想要的结果为最小包含子串的长度,初始时为 INT_MAX。
3.接下来开始通过 right 变量从左到右遍历 str1。
1)right=0,str[0]=‘a’。在 map 中把 key 为’a’的 value 减 1,减完后变为(‘a’,0)。减完之后 value 为 0,说明减之前大于 0,那么 str1 归还了 1 个’a’,match 值也要减 1,表示对 str2 的所有字符来说,str1 目前归还了 1 个。目前变量状况如下:
key value ‘a’ 0 ‘b’ 1 ‘c’ 1 match=2,left=0,right=0,minLen=INT_MAX
2)right=1,str[1]=‘d’。在 map 中,把 key 为’d’的 value 减 1,但是发现 map 中没有 key为’d’的记录,就加一条记录(‘d’,-1),表示’d’字符 str1 多归还了 1 个。此时 value 为-1,说明当前这个字符是 str2 不需要的,所以 match 不变。目前变量状况如下:
key value ‘a’ 0 ‘b’ 1 ‘c’ 1 ‘d’ -1 match=2,left=0,right=1,minLen=INT_MAX
3)right=2,str[2]=‘a’。在 map 中,把 key 为’a’的 value 减 1,变为(‘a’,-1)。减之后 value为-1,说明减之前 str1 根本就不欠 str2 当前的字符,还是多归还的,故 match 不变。
key value ‘a’ -1 ‘b’ 1 ‘c’ 1 ‘d’ -1 match=2,left=0,right=2,minLen=INT_MAX
4)right=3,str[3]=‘b’。(‘b’,1)变为(‘b’,0),减之后 value 为 0,说明当前字符’b’归还有效,match 值减 1。
key value ‘a’ -1 ‘b’ 0 ‘c’ 1 ‘d’ -1 match=1,left=0,right=3,minLen=INT_MAX
5)right=4,str[4]=‘b’。(‘b’,0)变为(‘b’,-1),减之后 value 为-1,说明当前字符’b’归还无效,match 值不变。
key value ‘a’ -1 ‘b’ -1 ‘c’ 1 ‘d’ -1 match=1,left=0,right=4,minLen=INT_MAX
6)right=5,str[5]=‘c’。(‘c’,1)变为(‘c’,0),减之后 value 为 0,说明当前字符’c’归还有效,match 值减 1。
key value ‘a’ -1 ‘b’ -1 ‘c’ 0 ‘d’ -1 match=0,left=0,right=5,minLen=INT_MAX
此时 match 第一次变成了 0,说明遍历到目前为止,str1 把需要归还的字符都还完了,此时被框住的子串也就是 str1[0…5],肯定是包含 str2 所有字符的。但是当前被框住的子串是在必须以位置 5 结尾的情况下最短的吗?不一定,因为有些字符归还得很多余,所以步骤 6)还要继续如下过程。
left 开始往右移动,left=0,str1[0]=‘a’,key 为’a’的记录为(‘a’,-1),当前 value=-1,说明 str1 即便拿回这个字符,也不会欠 str2。所以拿回来,令记录变为(‘a’,0),left++。left=1,str1[1]=‘d’,key 为’d’的记录为(‘d’,-1),当前 value=-1,说明 str1 即便拿回’d’,也不会欠 str2。所以拿回来,令记录变为(‘d’,0),left++。left=2,str1[2]=‘a’,key 为’a’的记录为(‘a’,0),当前 value=0,说明 str1 如果拿回这个位置的字符,就要亏欠 str2 了,所以此时 left 停止向右移动。str1[2…5]就是在必须以位置 5 结尾的情况下的最小窗口子串。minLen 更新为 4。
步骤 6)(即 right=5)这一步揭示了整个解法最关键的逻辑,先通过 right 向右扩,让所有的字符被“有效”地还完,都还完时,被框住的子串肯定是符合要求的,但还要经过 left 向右缩的过程来看被框住的子串能不能变得更短。至此,关于位置 5 结尾的情况下的最短窗口子串已经找到。同时从 left 位置开始的最短窗口子串也是 str1[left…right]。所以,之后如果更小的窗口子串也一定不会从 left 的位置开始,而是从 left 之后的位置开始。str1[2]=‘a’,令记录(‘a’,0)变为(‘a’,1),match++,然后 left++。表示现在的 str1[3…5]又开始欠 str2 字符了,right 继续往右扩。目前变量的状况如下:
key value ‘a’ 1 ‘b’ -1 ‘c’ 0 ‘d’ 0 match=1,left=3,right=5,minLen=4
7)right=6,str[6]=‘a’。(‘a’,1)变为(‘a’,0),减之后 value 为 0,说明当前字符’a’归还有效,match 值减 1。match 又一次等于 0,进入 left 向右缩的过程。left=3,str1[3]=‘b’,key 为’b’的记录为(‘b’,-1),当前 value=-1,说明 str1 即便拿回这个位置的字符,也不会欠 str2,所以拿回,记录变为(‘b’,0),left++。left=4,str1[4]=‘b’,key 为’b’的记录为(‘b’,0),当前 value=0,说明如果拿回当前字符’b’,就要亏欠 str2。所以此时的 str1[4…6]就是在必须以位置 6 结尾的情况下的最小窗口子串,令 minLen 更新为 3。同步骤 6)的逻辑一样,left=4,str1[4]=‘b’,令(‘b’,0)变为(‘b’,1),match++,left++。表示现在的 str1[5…6]又开始欠 str2 字符,right 继续往右扩。
key value ‘a’ 0 ‘b’ 1 ‘c’ 0 ‘d’ 0 match=1,left=5,right=6,minLen=3
8)right=7,遍历结束。
4.如果 minLen 此时依然等于 INT_MAX,说明从始至终都没有符合条件的窗口出现过,当然 minLen 也从未被设置过,则返回 0,否则返回 minLen 的值。left 和 right 始终向右移动,right 移动到右边界过程停止
【代码】
#include 回文最少分割数
【题目】
给定一个字符串 str,返回把 str 全部切成回文子串的最小分割数。
例如:
str=“ABA”。不需要切割,str 本身就是回文串,所以返回 0。
str=“ACDCDCDAD”。最少需要切 2 次变成 3 个回文子串,比如"A"、“CDCDC"和"DAD”,所以返回 2。
【解答】
-
动态规划+预处理数组
定义动态规划数组 dp,假设 str 长度为 len,dp[i]的含义是子串 str[i…len-1]至少需要切割几次,才能把 str[i…len-1]全部切成回文子串。那么,dp[0]就是最后的结果。
从右往左依次计算 dp[i]的值,i 初始为 len-1,具体计算过程如下:
1.假设 j 位置处在 i 与 len-1 位置之间(i≤j
2.根据步骤 1 的方式,让 j 在 i 到 len-1 位置上枚举,那么所有可能情况中的最小值就是dp[i]的值,即 dp[i] = min { dp[j+1]+1 (i≤j
3.如何方便快速地判断 str[i…j]是否是回文串呢?具体过程如下。
1)定义一个二维数组 vector
p,如果 p[i] [j]值为 true,说明字符串 str[i…j]是回文串,否则不是。在计算 dp 数组的过程中,希望能够同步、快速地计算出矩阵 p。 2)p[i] [j]如果为 true,一定是以下三种情况:
- str[i…j]由 1 个字符组成。
- str[i…j]由 2 个字符组成且 2 个字符相等。
- str[i+1…j-1]是回文串,即 p[i+1] [j-1]为 true,且 str[i]==str[j],即 str[i…j]上首尾两个字符相等。
3)在计算 dp 数组的过程中,位置 i 是从右向左(从二维数组角度看为从下向上)依次计算的。而对每一个 i 来说,又依次从 i 位置向右枚举所有的位置 j(i≤j
4.最终返回 dp[0]的值,过程结束。
【代码】
#include 字符串匹配问题
【题目】
给定字符串 str,其中绝对不含有字符’ . ‘和’ * ‘。再给定字符串 exp,其中可以含有’ . ‘或’ * ‘,’ * ‘字符不能是 exp 的首字符,并且任意两个’ * ‘字符不相邻。exp 中的’ . ‘代表任何一个字符,exp 中的’ * ‘表示’ * '的前一个字符可以有 0 个或者多个。请写一个函数,判断 str 是否能被 exp 匹配。
例如:
str=“abc”,exp=“abc”,返回 true。
str=“abc”,exp=“a.c”,exp 中单个’ . '可以代表任意字符,所以返回 true。
str=“abcd”,exp=“.*”。exp 中’ * ‘的前一个字符是’ . ‘,所以可表示任意数量的’ . '字符,当 exp是"…"时与"abcd"匹配,返回 true。
str=“”,exp="…“。exp 中’ * ‘的前一个字符是’ . ‘,可表示任意数量的’ . '字符,但是”."之前还有一个’ . ‘字符,该字符不受’ * '的影响,所以 str 起码有一个字符才能被 exp 匹配。所以返回 false。
【解答】
-
法一:暴力递归
首先解决 str 和 exp 有效性的问题。根据描述,str 中不能含有’ . ‘和’ * ‘,exp 中’ * ‘字符不能是首字符,并且任意两个’ * '字符不相邻。
下面解释一下递归过程,假设 str 长度为 slen,exp 长度为 elen,process 函数的意义是:从 str 的 si 位置开始,一直到 str 结束位置的子串(即 str[si…slen]),是否能被从 exp 的 ei 位置开始一直到 exp 结束位置的子串(即exp[ei…elen])匹配,所以 process(str,exp,0,0)就是最终返回的结果。
那么在递归过程中如何判断 str[si…slen]是否能被 exp[ei…elen]匹配呢?
假设当前判断到 str 的 si 位置和 exp 的 ei 位置,即 process(str,exp,si,ei)。
1.如果 ei 为 exp 的结束位置(ei=elen),si 也是 str 的结束位置(si=slen),返回 true,因为“可以匹配”。如果 si 不是 str 的结束位置,返回 false,这是显而易见的。
2.如果 ei 位置的下一个字符(exp[ei+1])不为’ * '。那么就必须关注 str[si]字符能否和 exp[ei]字符匹配。如果 str[si]与 exp[ei]能匹配(exp[ei] = str[si] 或 exp[ei] = ‘.’),还要关注 str 后续的部分能否被 exp 后续的部分匹配,即 process(str,exp,si+1,ei+1)的返回值。如果 str[si]与 exp[ei]不能匹配,当前字符都不匹配,当然不用计算后续的,直接返回 false。
3.如果当前 ei 位置的下一个字符(exp[ei+1])为’ * '字符。
1)如果 str[si]与 exp[ei]不能匹配,那么只能让 exp[ei…ei+1]这个部分为"“,也就是 exp[ei+1]=’ * '字符的前一个字符 exp[ei]的数量为 0 才行,然后考查 process(str,exp,si,ei+2)的返回值。举个例子,str[si…slen]为"bXXX”,“XXX"代指字符’b’之后的字符串。exp[ei…elen]为"aYYY","YYY"代指字符’ * '之后的字符串。当前无法匹配(‘a’!=‘b’),所以让"a"为”“,然后考查 str[si…slen](即"bXXX”)能否被 exp[ei+2…elen](即"YYY")匹配。
2)如果 str[si]与 exp[ei]能匹配,这种情况下举例说明。
str[si…slen]为"aaaaaXXX",“XXX"指不再连续出现’a’字符的后续字符串。exp[ei…elen])为"a*YYY”,"YYY"指字符’ * '之后的后续字符串。
如果令"a"和"a*"匹配,且有"aaaaXXX"和"YYY"匹配,可以返回 true。
如果令"aa"和"a*"匹配,且有"aaaXXX"和"YYY"匹配,可以返回 true。
如果令"aaa"和"a*"匹配,且有"aaXXX"和"YYY"匹配,可以返回 true。
如果令"aaaa"和"a*"匹配,且有"aXXX"和"YYY"匹配,可以返回 true。
如果令"aaaaa"和"a*"匹配,且有"XXX"和"YYY"匹配,可以返回 true。
也就是说,exp[ei…ei+1](即"a*")的部分如果能匹配 str 后续很多位置的时候,只要有一个返回 true,就可以直接返回 true。
整个递归过程结束。
-
法二:动态规划
递归函数process(str,exp,si,ei)在每次调用的时候,有两个参数是始终不变的(str 和 exp),所以代表 process 函数状态的就是 si 和 ei 值的组合。所以,如果把递归函数 p 在所有不同参数(si 和 ei)的情况下的所有返回值看作一个范围,这个范围就是(slen+1) * (elen+1)的一个二维数组,并且 p(si,ei)在整个递归过程中依赖的总是 p(si+1,ei+1)或者 p(si+k(k>=0),ei+2),假设二维数组 dp[i] [j]代表 p(i,j)的返回值,dp[i] [j]就只是依赖 dp[i+1] [j+1]或者 dp[i+k(k>=0)] [j+2]的值。进一步可以看出,想要求 dp[i] [j]的值,只需要(i,j)位置右方或右下方的某些值。所以只要从二维数组的右下角开始,从右到左,再从下到上计算出二维数组 dp 中每个位置的值就可以,dp[0] [0]就是最终结果。p(i,j)的递归过程如何,dp[i] [j]的值就怎样去计算。
先从右到左计算 dp[slen] […],也就是二维数组 dp 中的最后一行。dp[slen] [elen]值的含义是 str 已经结束,剩下的字符串为"“,exp 也已经结束,剩下的字符串为”“,所以此时 exp 可以匹配 str,dp[slen] [elen]=true。对于 dp[slen] [0…elen-1]的部分,dp[slen] [i]的含义是 str 已经结束,剩下的字符串为”“,exp 却没有结束,剩下的字符串为 exp[i…elen-1],什么情况下 exp[i…elen-1]可以匹配”"?只能是不停地重复出现"X*"这种方式。
也就是说,在从右向左计算 dp[slen] [0…elen-1]的过程中,看 exp 是不是从右往左重复出现"X*",如果是重复出现,那么如果 exp[i]=‘X’,exp[i+1]=’ * ‘,令dp[slen] [i]=true,如果 exp[i]=’ * ',exp[i+1]=‘X’,令 dp[slen] [i]=false。如果不是重复出现,最后一行后面的部分(即 dp[slen] [0…i])全都是 false。这样就搞定了 dp 最后一行的值。
再看看 dp 除右下角的值之外,最后一列其他位置的值,即 dp[0…slen-1] [elen]。这表示如果 exp 已经结束,而 str 还没结束。显然,exp 为"",匹配不了任何非空字符串,所以dp[0…slen-1] [elen]都为 false。
接着看 dp 倒数第二列的值,即 dp[0…slen-1] [elen-1]。这表示如果 exp 还剩一个字符(即exp[elen-1]),而 str 还剩 1 个字符或多个字符。很明显,str 还剩多个字符的情况下,exp 匹配不了。str 还剩 1 个字符的情况下(即 str[slen-1]),如果和 exp[elen-1]相等,则可以匹配,或者exp[elen-1]=’ . '的情况下可以匹配。
因为 dp[i] [j]只依赖 dp[i+1] [j+1]或者 dp[i+k] [j+2] (k≥0)的值,所以在单独计算完最后一行、最后一列与倒数第二列之后,剩下的位置在从右到左,再从下到上计算 dp 值的时候,所有依赖的值都被计算出来,直接拿过来用即可。
【代码】
- 法一
#include - 法二
#include 字典树(前缀树)的实现
【题目】
字典树又称为前缀树或 Trie 树,是处理字符串常见的数据结构。假设组成所有单词的字符仅是’a’~‘z’,请实现字典树结构,并包含以下四个主要功能。
- void insert(string word):添加 word,可重复添加。
- void delete(string word):删除 word,如果 word 添加过多次,仅删除一个。
- bool search(string word):查询 word 是否在字典树中。
- int prefixNumber(string pre):返回以字符串 pre 为前缀的单词数量。
【解答】
-
字典树(前缀树)
字典树的介绍。字典树是一种树形结构,优点是利用字符串的公共前缀来节约存储空间,比如加入"abc"、“abcd”、“abd”、“b”、“bcd”、“efg”、"hik"之后,字典树如下图所示。
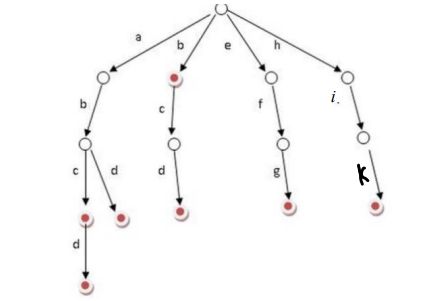
字典树的基本性质如下:
- 根节点没有字符路径。除根节点外,每一个节点都被一个字符路径找到。
- 从根节点出发到任何一个节点,如果将沿途经过的字符连接起来,一定为某个加入过的字符串的前缀。
- 每个节点向下所有的字符路径上的字符都不同。
在字典树上搜索添加过的单词的步骤如下:
1.从根节点开始搜索。
2.取得要查找单词的第一个字母,并根据该字母选择对应的字符路径向下继续搜索。
3.字符路径指向的第二层节点上,根据第二个字母选择对应的字符路径向下继续搜索。
4.一直向下搜索,如果单词搜索完后,找到的最后一个节点是一个终止节点,比如上图中的实心节点,说明字典树中含有这个单词,如果找到的最后一个节点不是一个终止节点,说明单词不是字典树中添加过的单词。如果单词没搜索完,但是已经没有后续的节点了,也说明单词不是字典树中添加过的单词。
在字典树上添加一个单词的步骤同理。
TrieNode 类中,path 表示有多少个单词共用这个节点,end 表示有多少个单词以这个节点结尾,map 是一个哈希表结构,key 代表该节点的一条字符路径,value 表示字符路径指向的节点。介绍完 TrieNode 后,下面详细介绍本题的 Trie 树类如何实现。
- void insert(string word):假设单词 word 的长度为 N,从左到右遍历 word 中的每个字符,并依次从头节点开始根据每一个 word[i],找到下一个节点。如果找的过程中节点不存在,就建立新节点,记为 a,并令 a.path=1。如果节点存在,记为 b,令 b.path++。通过最后一个字符(word[N-1])找到最后一个节点时记为 e,令 e.path++,e.end++。
- bool search(string word):从左到右遍历 word 中的每个字符,并依次从头节点开始根据每一个 word[i],找到下一个节点。如果找的过程中节点不存在,说明这个单词的整个部分没有添加进 Trie 树,否则找的过程中节点不可能不存在,直接返回 false。如果能通过 word[N-1]找到最后一个节点,记为 e,如果 e.end!=0,说明有单词通过word[N-1]的字符路径,并以节点 e 结尾,返回 true。如果 e.end==0,返回 false。
- void delete(string word):先调用 search(word),看 word 是否在 Trie 树中,若在,则执行后面的过程,若不在,则直接返回。从左到右遍历 word 中的每个字符,并依次从头节点开始根据每一个 word[i]找到下一个节点。在找的过程中,把遍历过每一个节点的 path 值减 1。如果发现下一个节点的 path 值减完之后已经为 0,直接从当前节点的 map 中删除后续的所有路径,并返回即可。如果遍历到最后一个节点,记为 e,令e.path–,e.end–。
- int prefixNumber(string pre):和查找操作同理,根据 pre 不断找到节点,假设最后的节点记为 e,返回 e.path 的值即可。
【代码】
#include 子数组的最大异或和
【题目】
数组异或和的定义:把数组中所有的数异或起来得到的值。给定一个整型数组 arr,其中可能有正、有负、有零,求其中子数组的最大异或和。
例如:
arr = {3},数组只有 1 个数,所以只有一个子数组,就是这个数组本身,最大异或和为 3。
arr = {3, -28, -29, 2},子数组有很多,但是{-28, -29}这个子数组的异或和为 7,是所有子数组中最大的。
【解答】
-
法一:预处理数组
异或运算有如下性质。
1)满足交换律和结合律,即只要是同一批数字,不管异或顺序如何,得到的结果都一样。
2)如果 a^b=c,那么有 a=c^b 和 b=c^a。
3)0 和任何数字 N 异或的结果为 N,任何数字 N 和自己异或的结果为 0。
假设 arr[i…j](i≤j)这个子数组的异或和用 xor[i…j]来表示。也就是说,xor[0…j] = xor[0…i-1] ^ xor[i…j],则可以推出 xor[i…j] = xor[0…j] ^ xor[0…i-1]。
解法过程如下:
1)生成长度和 arr 一样的数组,记为 eor,eor[i]的含义为 arr[0…i]这个子数组的异或和,只遍历 arr 一遍就可以生成 eor 数组。
2)在以 j 位置结尾的情况下,看下面一系列的子数组异或和哪个最大,最大的那个就是必须以 j 结尾的所有子数组中最大的异或和。
xor[0…j] = eor[j] ^ 0
xor[1…j] = eor[j] ^ eor[0]
…
xor[i…j] = eor[j] ^ eor[i-1]
…
xor[j…j] = eor[j] ^ eor[j-1]
3)尝试每一个位置都作为结尾位置,并求出以这个位置结尾情况下最大的异或和,全局最大的那个就是答案。
-
法二:前缀树
我们要的是 maxValue(以 j 结尾时的 maxValue),即 maxValue = (xor[0…j],xor[1…j],…,xor[j…j]中最大的一项)。也就是说,maxValue = eor[j] ^(从 0,eor[0],eor[1],…,eor[j-1]中挑一个出来)。上述方法其实并不知道挑哪个,也不知道怎么挑,所以只能都试一遍。
这里可以利用前缀树这个结构,将挑选的过程加速。当求以 j 位置结尾的情况下最大的子数组异或和,需要 0,eor[0],eor[1],…,eor[j-1],eor[j]的全体,假设这些值都是二进制数,并且 0,eor[0],eor[1],…,eor[j-1]都加入到了一棵前缀树里。举个例子,arr = {11, 1, 15, 10, 13, 4},现在要求必须以 5 作为结尾情况下的子数组最大异或和。
0 = 0000
eor[0] = arr[0…0]的异或和 = 11 = 1011
eor[1] = arr[0…1]的异或和 = 11 ^ 1 = 1010
eor[2] = arr[0…2]的异或和 = 11 ^ 1 ^ 15 = 0101
eor[3] = arr[0…3]的异或和 = 11 ^ 1 ^ 15 ^ 10 = 1111
eor[4] = arr[0…4]的异或和 = 11 ^ 1 ^ 15 ^ 10 ^ 13 = 0010
eor[5] = arr[0…5]的异或和 = 11 ^ 1 ^ 15 ^ 10 ^ 13 ^ 4 = 0110假设一棵前缀树内放入了 0、eor[0]、eor[1]、eor[2]、eor[3]、eor[4],形成的树如下图所示。
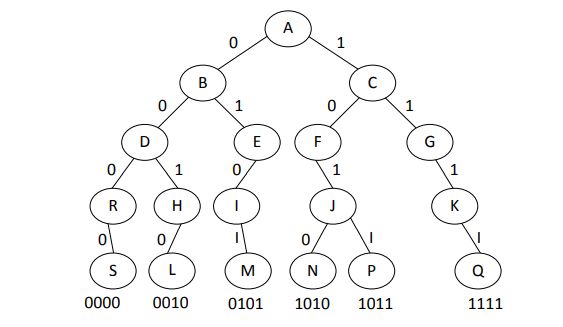
eor[5] ^ (和谁结合?),得到的最大值记为 X,X 就是必须以 5 结尾的情况下,子数组最大异或和。
eor[5]为 0110,如果能够选择,让高位先变 1,得到的结果就是最大的。比如,eor[5]从高位到低位的数字是 0、1、1、0,如果能够依次遇到 1、0、0、1 就好了,这样异或之后就能得到最大值 1111,如果不能完美地遇到 1、0、0、1,也希望先满足高位异或之后变成 1 这个需求。现在来看前缀树,从 A 点开始,有走向 1 的路到达 C 点,从 C 点开始有走向 0 的路到达 F 点,这说明 eor[5]从高位到低位的前两个数字 0、1,是可以满足这两个数字能依次遇到 1 和 0 的,那就先满足。而 eor[5]从高位到低位的第三个数字是 1,我们希望能走 0 的路,可是从 F 往下没有 0 的路,只能走向 1 的路到达 G;eor[5]从高位到低位的第四个数字是 0,我们希望能走 1 的路,从 G 往下有 1 的路,所以继续满足,最后到达 P 点。沿途走过的路依次为 1、0、1、1,那么这条路径就是所有可能性中的最优路径,最优路径得到之后是 1011,也就是 eor[0]的值,0110 ^ 1011 = 1101。
eor[5] ^ (挑选出了 eor[0]) => 得到值 1101,必须以 5 结尾的情况下,子数组最大异或和为 1101。
因为前缀树就是从前到后依次把样本每一位的信息存到树中,所以,如果把策略定成先满足高位异或之后变成 1 这个需求,前缀树可以很好地完成挑选这个过程,而不用去尝试每一个样本。这就是最优解的核心。
现在把长度只有 4 位的二进制数的例子推广到 32 位,并且最高位是符号位的情况。假设当前数组的结束位置是 j,eor[j]就是一个普通的整数,选择最优的异或路径过程如下:
1)对于最高位符号位的数字,不管 eor[j]是正数还是负数,我们都希望异或之后是正数,因为我们要的是最大值,所以 eor[j]的最高位如果是 0,希望能走 0 的路,因为这样异或之后符号位是 0,为正数;eor[j]的最高位如果是 1,希望走 1 的路,因为这样异或之后符号位是 0,为正数。如果不能选择,只能被迫走唯一的路。
2)走过最高位之后,从左到右(也就是从高到低)依次考虑 K 的每一位数字,因为总是应该先满足高位的需求。eor[j]的当前位数字如果是 0,希望能走 1 的路;K 的最高位如果是 1,希望走 0 的路。如果不能选择,只能被迫走唯一的路。
3)当 32 步都走完时,eor[j]该和谁异或也就知道了,异或后就是最大值,也是以 j 作为结尾的情况下子数组的最大异或和。
【代码】
- 法一
#include - 法二
#include