numpy随机生成01矩阵_机器学习:Python常用库——Numpy库


从前面的学习中我们知道,机器学习是以大量数据为基础的。
由此就引出一个问题:那么多的数据我们要如何处理呢?

别担心,嘻嘻,Python开发人员早有准备。
为了拓宽数据科学方面的应用,Numpy库应运而生。Numpy是Python用来进行矩阵运算、高维数组运算的数学计算库。

接下来,我就简单介绍一下Numpy的相关使用。
02导入Numpy库
为了书写方便,一般用别名np代替Numpy库(如果安装的是anaconda,Numpy库是自带的)。
import numpy as np常用函数
导入Numpy库之后,可以用Numpy生成数组。使用array()函数可以生成一个数组,与列表的区别是没有逗号:
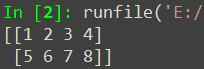
a = np.array([[1,2,3,4],[5,6,7,8]])print(a)上方的代码将生成一个二维数组,结果如图:
如果想改变数组的维度,获取4行2列数组,可以通过reshape()方法实现:
b = a.reshape((4,-1))print(b)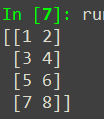
reshape()中的参数(4,-1)表示将数组转换为4*X的新数组,X等于数组a中元素个数的1/4。参数-1是一种“懒人”方法,表示由Python通过行参数4自动计算出列数。
此外,默认是按照行优先改变数据维度,也可以设置参数order="F",按照列优先改变数据维度:
c = a.reshape((4,2), order="F")print(c)
虽然数组的维度没有改变,但是元素对应的位置已经不同了。
想要提取数组中的某些元素,可以使用切片的方式来提取。如提取第2行中的5和7:
d = c[1,:]print(d)获取结果如图:

当然,也可以使用切片的方法修改数组中相应位置的数值,比如将数组c中第二列的中间两个数变为0,可以这样操作:
c[1:3,1] = 0print(c)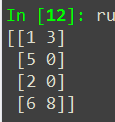
可以看出,逗号左边表示行号,右边表示列号,由此就能任意截选出我们需要的数据。
数组不仅可以是二维的,也可以是多维的。下面生成一个三维数组e:
e = np.array([c,c*2])print(e)
数组e是一个2*2*4的数组,也就是说由2个2*4的矩阵构成。
Numpy中的linspace()函数可以在指定的两个数之间生成固定数量的等间距(步长)数组,如:
f = np.linspace(start=1,stop=12,num=5)print(f)![]()
上方代码生成一个从1到12的5个等间距的数组。
如果想以指定的步长来生成一个向量,可以使用arange()方法,如从1开始,步长为3,生成小于等于12的向量:
g = np.arange(1,12,3)print(g)结果:[1 4 7 10]
使用
ones()函数可以生成全1数组,如生成一个2*3的全1数组:
h = np.ones((2,3))print(h)使用zeros()函数可以生成全0数组,如生成一个2*3的全0数组:
i = np.zeros((2,3))print(i)若想生成单位数组(对角线为1,其余全是0),可以使用eye()函数,如生成一个3*3的单位数组:
j = np.eye(3)print(j)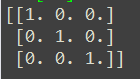
当然,也可以指定对角线的元素取值:
k = np.diag(np.arange(1,13,4))print(k)
使用diag()函数可以得到一个数组的对角线元素,也可以获取对角线的值:
l =np.diag(np.arange(1,26,3).reshape((3,3)))print(l)结果:[ 1 13 25 ]
Numpy中的Random模块是用来生成随机数的有力工具,通过seek()方法能指定随机数种子,保证生成的随机数是可重复的。如要生成一个可重复的3*3随机数组,可以用如下方法:
np.random.seed(2)m = np.random.randn(3, 3)print(m)
当然,一些常用的统计函数也能实现,如均值用mean()方法:
n = np.arange(10)print(n.mean())
标准差可以使用std()方法:
n = np.arange(10)print(n.std())![]()
数组排序可以使用sort()方法,默认是每行自动排序:
p = np.sort([[2,5,3],[10,6,8]])print(p)
数组的百分位数可以用percentile()函数:
q = np.arange(10)print(np.percentile(q, 50))
中位数用median()函数:
q = np.arange(10)print(np.median(q))
当个数为偶数时,中位数是中间两个数字之和除以2。
Numpy的计算方法还有很多,大家可以去网上查阅,这里只说几个常用的。
04Numpy主要以数组为操作对象,在生成和调整数组方面优势非常明显。但直接观察数组却不太方便,没有序号、排列不齐等问题并不利于我们寻找数据规律,所以我们需要继续学习。
下一次我们将介绍Pandas库,让数据的处理和操作变得更加简单快捷。
你确定不关注我一波?!


