Docker 容器监控
目录
cAdvisor
安装cAdvisor
使用Prometheus监控cAdvisor
cAdvisor暴露的Prometheus指标
容器指标
1. 文档:
2. 指标
硬件指标
1. 文档:
2. 指标:
Node Exporter
安装Node Exporter
1. 启动容器,默认端口为9100
2. 访问http端点,查看指标
3. --collector. 启用指标,--no-collector. 禁用指标,--collector.disable-defaults 禁用所有默认启用 的指标。例如:
指标
默认禁用指标
1. 文档:
2. 禁用指标的原因:
3. 指标
Prometheus
安装
1. 配置文件
2. 启动容器
3. 访问端点:http://192.168.1.197:9090
4. 指标类型
5. 5分钟CPU使用率表达式
6. 机器平均负载,node_load1 1分钟平均负载,node_load5 5分钟平均负载,node_load15 15分钟 平均负载
7. 内存使用率
8. 磁盘空间使用率
规则配置
规则检查
记录规则
报警规则
配置文件中指定规则文件
报警管理器
grafana
1. 源码地址
GitHub - grafana/grafana: The open and composable observability and data visualization platform. Visualize metrics, logs, and traces from multiple sources like Prometheus, Loki, Elasticsearch, InfluxDB, Postgres and many more.
2. 官网
3. 安装使用,默认用户名:admin 默认密码:admin
4. 几个现有的grafana 模板
5. 去官网挑选模板
cAdvisor
源码:https://github.com/google/cadvisor
node exporter
源码:https://github.com/prometheus/node_exporter
prometheus:
官方文档:https://prometheus.io/ PromQL
文档:https://prometheus.io/docs/prometheus/latest/querying/basics/
源码:https://github.com/prometheus/prometheus
报警管理器文档:https://prometheus.io/docs/alerting/latest/overview/
报警管理器源码:https://github.com/prometheus/alertmanager
中文文档:https://www.prometheus.wang/quickstart/why-monitor.html
cAdvisor
cAdvisor让容器用户了解容器的资源使用情况和性能特征。用于收集、聚合、处理和导出有关正在运行的容器的信息。它为每个容器保存资源隔离参数、历史资源使用情况、完整历史资源使用直方图和网络统计信息。简而言之:对容器进行实时监控和性能数据采集,包括CPU、内存、网络、文件系统等资源的使用情况
安装cAdvisor
1. 下载二进制文件:https://github.com/google/cadvisor/releases/download/v0.46.0/cadvisorv0.46.0-linux-amd64
2. 编写Dockerfile构建容器
FROM ubuntu:latest
LABEL cadvisor 0.46.0
COPY ./cadvisor-v0.46.0-linux-amd64 /usr/bin/cadvisor
RUN chmod +x /usr/bin/cadvisor
ENTRYPOINT ["/usr/bin/cadvisor"]
docker build -t cadvisor:0.46.0 .
3. 运行容器
docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:ro \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8080:8080 \
--detach=true \
--name=cadvisor \
--userns=host \
--privileged \
--device=/dev/kmsg \
cadvisor:0.46.04. web访问监控图标
http://localhost:8080

使用Prometheus监控cAdvisor
cAdvisor将容器和硬件统计数据公开为Prometheus开箱即用的指标。默认情况下,这些指标在http端点的/metrics路径下。例如:http://192.168.1.197:8080/metrics。可以通过设置
-prometheus_endpoint和-disable_metrics或-enable_metrics命令行标志来自定义此端点
1. -disable_metrics:
要禁用的指标的逗号分隔列表。选项包括: accelerator,advtcp,app,cpu,cpuLoad,cpu_topology,cpuset,disk,diskIO,hugetlb,memory,memo ry_numa,network,oom_event,percpu,perf_event,process,referenced_memory,resctrl,sched,tc p,udp。默认值: advtcp,cpu_topology,cpuset,hugetlb,memory_numa,process,referenced_memory,resctrl,sche d,tcp,udp。
2. -enable_metrics:
要启用的指标的逗号分隔列表,如果设置则覆盖-disable_metrics选项。选项包括: accelerator,advtcp,app,cpu,cpuLoad,cpu_topology,cpuset,disk,diskIO,hugetlb,memory,memo ry_numa,network,oom_event,percpu,perf_event,process,referenced_memory,resctrl,sched,tc p,udp。
3. -prometheus_endpoint:
暴露普罗米修斯指标的端点(默认为“/metrics”)
4. 示例:
docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:ro \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8080:8080 \
--detach=true \
--name=cadvisor \
--userns=host \
--privileged \
--device=/dev/kmsg \
cadvisor:0.46.0 -disable_metrics cpu,cpuLoad
cAdvisor暴露的Prometheus指标
容器指标
1. 文档:
https://github.com/google/cadvisor/blob/master/docs/storage/prometheus.md#prometheus -container-metrics
2. 指标


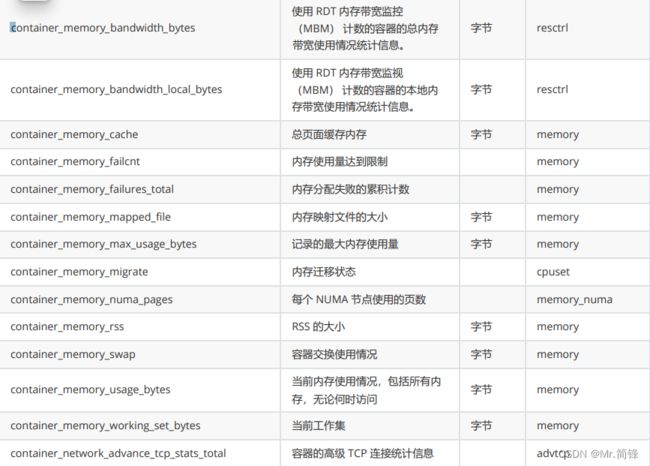
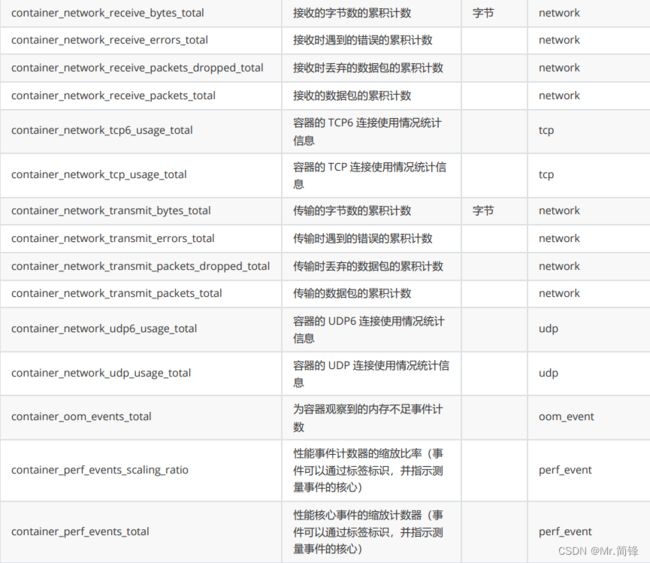

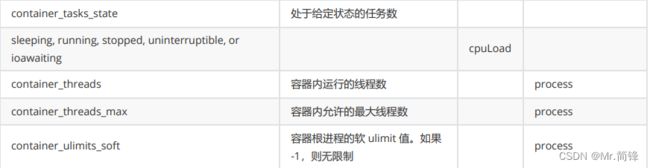
硬件指标
1. 文档:
https://github.com/google/cadvisor/blob/master/docs/storage/prometheus.md#prometheus -hardware-metrics
2. 指标:

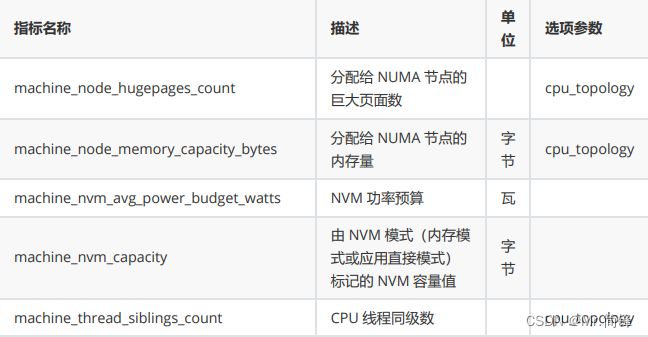
Node Exporter
Node Exporter 是prometheus官方提供的agent,项目被托管在prometheus的账号之下。用于收集主机的硬件和操作系统指标。
安装Node Exporter
1. 启动容器,默认端口为9100
# 安装Node Exporter 来收集硬件信息
docker run -d \
--net="host" \
--pid="host" \
--userns="host" \
-v "/:/host:ro,rslave" \
--name node_exporter \
quay.io/prometheus/node-exporter:latest \
--path.rootfs=/host
2. 访问http端点,查看指标
http://192.168.1.197:9100/metrics
3. --collector. 启用指标,--no-collector. 禁用指标,--collector.disable-defaults 禁用所有默认启用 的指标。例如:
docker run -d \
--net="host" \
--pid="host" \
--userns="host" \
-v "/:/host:ro,rslave" \
--name node_exporter \
quay.io/prometheus/node-exporter:latest \
--path.rootfs=/host \
--collector.disable-defaults \
--collector.arp --collector.bcache
指标
默认启用指标
1. 文档:
https://github.com/prometheus/node_exporter#enabled-by-default
2. 指标
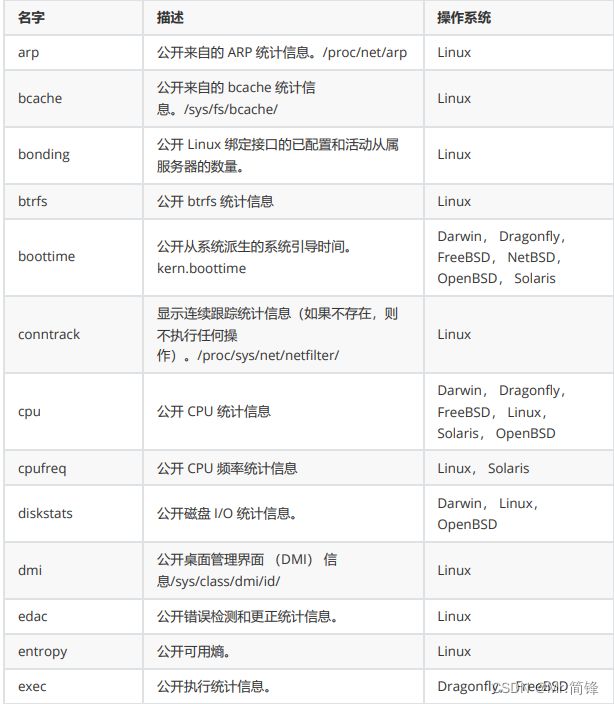


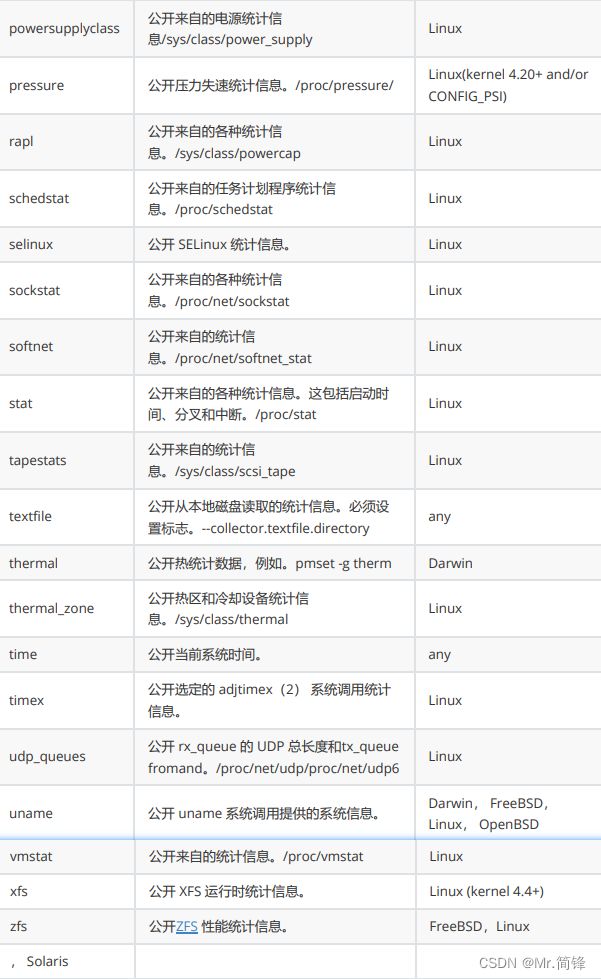
默认禁用指标
1. 文档:
https://github.com/prometheus/node_exporter#disabled-by-default
2. 禁用指标的原因:
1.高基数,
2.运行时长超过Prometheus scrap_interval或scrap_timeout设置的 时长,
3.对主机资源消耗巨大。因此,启用默认禁用指标需慎重,按需启用。
3. 指标
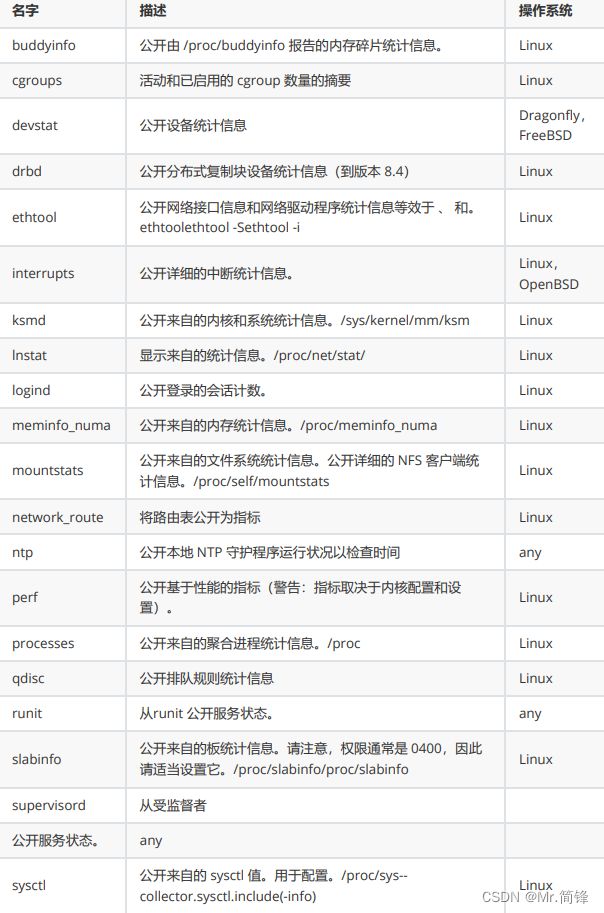

Prometheus
一个开源的监控和报警系统,通过定时收集采集端的数据,经过计算存入到时序数据库。通过PromQL 对时序数据库中的指标进行计算,从而分析出系统的状态。通过定时评估指定的基于PromQL的表达式 从而实现警告的触发。
安装
1. 配置文件
global:
# 每20s获取一次数据指标
scrape_interval: 20s
# 获取数据超时时长 10s
scrape_timeout: 10s
# 规则评估评率,即计算指标是否有触发规则的计算频率
evaluation_interval: 20s
# 规则文件,从所有匹配的文件中读取规则和警报
rule_files:
- "alertRule.yml"
- "recordRule.yml"
# 采集配置列表
scrape_configs:
- job_name: 'cadvisor'
static_configs:
- targets:
- 192.168.239.149:8080
- job_name: 'node'
static_configs:
- targets:
- 192.168.239.149:9100
- 192.168.239.142:9100
- 192.168.239.143:9100
- job_name: 'prometheus'
static_configs:
- targets:
- 192.168.239.149:9090
# 报警管理
alerting:
alertmanagers:
- static_configs:
- targets: ['192.168.239.149:9093']检查配置文件语法:
docker run --rm --entrypoint promtool -v /opt/prometheus:/etc/prometheus prom/prometheus check config /etc/prometheus/prometheus.yml
2. 启动容器
docker run -itd --name prometheus -p 9090:9090 \
-v /opt/prometheus:/etc/prometheus \
prom/prometheus --config.file=/etc/prometheus/prometheus.yml3. 访问端点:http://192.168.1.197:9090
4. 指标类型
Counter:计数器,只增不减,用于描述某个指标的累计状态。比如cpu总使用时长: node_cpu_seconds_total
Gauge:可增可减的计量器,用于描述某个指标的当前状态,比如空闲内存空间: node_memory_MemFree_bytes
5. 5分钟CPU使用率表达式
1 - 5分钟内增量空闲CPU/5分钟内增量总CPU ,按instance分组。由于 node_cpu_seconds_total指标是一个counter类型,所以该指标是一直累计CPU使用量,因此需要 以增量来获取CPU的量。表达式如下:
100- sum(increase(node_cpu_seconds_total{mode="idle"}[5m])) by (instance)/sum(increase(node_cpu_seconds_total[5m])) by (instance) * 100
6. 机器平均负载,node_load1 1分钟平均负载,node_load5 5分钟平均负载,node_load15 15分钟 平均负载
node_load1
node_load5
node_load15
7. 内存使用率
node_memory_MemTotal_bytes 总内存,node_memory_MemFree_bytes 空闲内存,node_memory_Buffers_bytes 缓冲缓存,node_memory_Cached_bytes 页面缓存。
公式:总内存 -(空闲内存 + 缓冲缓存 + 页面缓存))/ 总内存 * 100
(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes+node_memory_Cached_bytes ))/node_memory_MemTotal_bytes * 100
8. 磁盘空间使用率
node_filesystem_avail_bytes 可用字节数 ,node_filesystem_size_bytes 总字 节数
node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"} * 100
规则配置
规则检查
promtool check rules /path/to/example.rules.yml
记录规则
roups:
- name: RecordCpu
rules:
- record: Cpu15mRate
expr: 100- sum(increase(node_cpu_seconds_total{mode="idle"}[15m])) by
(instance)/sum(increase(node_cpu_seconds_total[15m])) by (instance) * 100
labels:
CpuRate: 15
报警规则
groups:
# 组名
- name: node_health
# 规则
rules:
# 报警名称
- alert: InstanceDown
# 基于PromQL的条件表达式
expr: up == 0
# 评估等待时间,表示,触发条件表达式后,等待一段时间发送报警信息
for: 1m
# 自定义label 标签
labels:
NodeHealth: false
# 附加信息,比如详细的描述报警情况
annotations:
# 摘要
summary: "Instance {{ $labels.instance }} down"
# 详情
description: " {{ $labels.instance }} of job {{ $labels.job }} has been
down for more than 1 minutes "
- name: node_resource
rules:
- alert: Cpu5mRate
expr: 100- sum(increase(node_cpu_seconds_total{mode="idle"}[5m])) by
(instance)/sum(increase(node_cpu_seconds_total[5m])) by (instance) * 100 > 2
labels:
CpuRate: hight
annotations:
# 摘要
summary: "Instance {{ $labels.instance }} 5分钟CPU使用率过高"
# 详情
description: " {{ $labels.instance }} of job {{ $labels.job }} 5分钟CPU使用
率过高 "
- alert: NodeLoad15
expr: node_load15 > 0.8
labels:
NodeLoad15: hight
annotations:
# 摘要
summary: "Instance {{ $labels.instance }} 15分钟平均负载过高请留意"
# 详情
description: " {{ $labels.instance }} of job {{ $labels.job }} 15分钟平均负载
过高 "
- alert: MemRate
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes +
node_memory_Buffers_bytes+node_memory_Cached_bytes ))/node_memory_MemTotal_bytes
* 100 > 20
labels:
NodeMemRate: hight
annotations:
# 摘要
summary: "机器内存使用率过高"
# 详情
description: "机器内存使用率超过20%,请留意"
- alert: DiskRate
expr: node_filesystem_avail_bytes{mountpoint="/"} /
node_filesystem_size_bytes{mountpoint="/"} * 100 > 80
labels:
DiskRate: hight
annotations:
# 摘要
summary: "机器磁盘使用率过高"
# 详情
description: "机器磁盘使用率超过80%,请留意"
配置文件中指定规则文件
rule_files:
- "alertRule.yml"
- "recordRule.yml"
报警管理器
报警管理器负责接收prometheus产生的报警,对报警消息进行管理。
例如:
去重:对同时触发的多个相同的警报去重
分组:同一个组的所有警报信息将被合并为一个警报通知,避免一次性接收大量的警告通知 路由:可根据情况配置路由,通知不同角色的运维人员
抑制:当某一个警告发出后,可以停止重复发送由此警告引发的其他警告
静默:被静默的标签将不会进行警告通知
1. 启动报警管理器
docker run --name alertmanager -d -p 9093:9093 quay.io/prometheus/alertmanager
2. 添加配置到prometheus 配置文件
# 报警管理
alerting:
alertmanagers:
- static_configs:
- targets: ['192.168.239.149:9093']
3. 访问http://192.168.1.197:9093可查看报警信息
grafana
一个开源的监控系统Web UI ,支持多种数据源。支持自定义看板,以及采用官方现有数据看板。
1. 源码地址
GitHub - grafana/grafana: The open and composable observability and data visualization platform. Visualize metrics, logs, and traces from multiple sources like Prometheus, Loki, Elasticsearch, InfluxDB, Postgres and many more.
2. 官网
Grafana Cloud | Observability platform overview
3. 安装使用,默认用户名:admin 默认密码:admin
docker run -d -p 3000:3000 --name=grafana -v /var/lib/grafana grafana/grafana-enterpris
4. 几个现有的grafana 模板
1860 、9276、193、11600
5. 去官网挑选模板