Docker容器监控可视化cAdivisor+InfluxDB+Grafana
问题
在日常的Docker使用过程中, 要想了解容器当前的运行状况 , 通过docker stats命令就可以很方便的看到当前宿主机上所有容器的CPU,内存以及网络流量等数据 ,
但是,
docker stats统计显示的目标结果只能是当前宿主机的全部容器的数据,且数据资料是实时的,没有地方存储、没有健康指标过线预警等功能 .
解决
SA的监控系统是物理机的监控,在一个物理机跑多个容器的情况下,我们是没法从一个监控图表里面区分各个容器的资源占用情况的。为了更好的监控容器运行情况,更重要的是为了后续的容器动态调度算法需要的大量运行时数据的搜集 , 因此我们需要搭建一套完整的容器监控 , 这里技术选型采用 CAdvisor + InfluxDB + Grafana
容器监控
CAdvisor监控收集+InfluxDB存储数据+Grafana展示图表 三者之间 关系 如下图
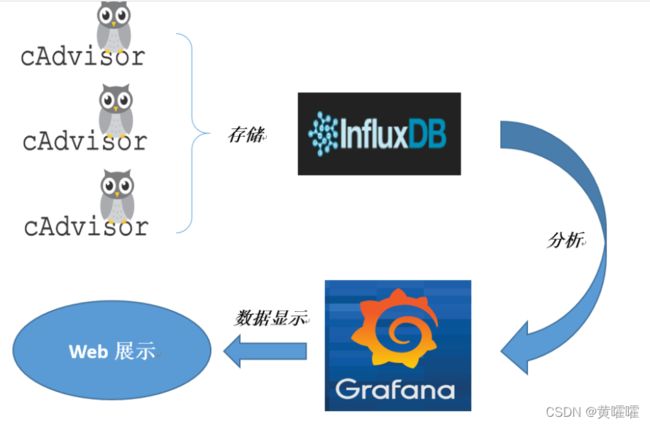
为什么选择这三个组合来作为Docker的容器监控呢 ?
首先你要想得到Docker的运行情况, 就需要使用Docker stats 来查看 , 但是这个东西展示出来的结果是整个Docker所有容器的实时综合运行情况, 且是命令行模式 , 那么这时候就需要cAdvisor 了 , 然而CAdcisor只能存储两分钟数据, 所以这时候需要将数据存储起来 , 就用到了InfluxDB , 然后要想将InfluxDB存储的这些监控历史数据都展示出来的话 又需要一个图形展示工具, 这时候句用到了Grafana.
CAdvisor
CAdvisor是一个容器资源监控工具 ,Cadvisor部署方便,使用简单,是Docker容器监控的原生态工具 , 包括容器的内存, cpu,网络IO,磁盘等监控, 同事提供了一个WEB页面用于查看容器的实时运行状态 . CAdvisor默认存储两分钟的数据 , 而且只是针对单物理机.不过CAdvisor提供了很多数据集成的接口 , 支持InfluxDB , Redis , Kafka , Elasticsearch等集成,可以加上对应配置将监控数据发送至这些数据库存储起来 .
CAdvisor功能主要有两点:
- 展示Host和容器两个层次的监控数据
- 展示历史变化数据(两分钟时效)
InflucDB
CAdvisor默认只在本机保存最近2分钟的数据,为了持久化存储数据和统一收集展示监控数据,需要将数据存储到InfluxDB中。InfluxDB是一个时序数据库,专门用于存储时序相关数据,很适合存储CAdvisor的数据。而且,CAdvisor本身已经提供了InfluxDB的集成方法,在启动容器时指定配置即可。
InfluxDB是一个当下比较流行的时序数据库,InfluxDB使用 Go 语言编写,无需外部依赖,安装配置非常方便,适合构建大型分布式系统的监控系统。
主要功能:
- 基于时间序列,支持与时间有关的相关函数(如最大,最小,求和等)
- 可度量性:你可以实时对大量数据进行计算
- 基于事件:它支持任意的事件数据
Grafana
通过CAdvisor搜集容器的监控数据,存储到InfluxDB中,接下来就剩数据可视化的问题了。毕竟,一个可视化的图表可以很方便快速的看到容器的一些问题。图表展示我选择的是Grafana。
Grafana是一个开源的数据监控分析可视化平台,支持多种数据源配置(支持的数据源包括InfluxDB,MySQL,Elasticsearch,OpenTSDB,Graphite等)和丰富的插件及模板功能,支持图表权限控制和报警。
主要功能
- 灵活丰富的图形化选项
- 可以混合多种风格
- 支持白天和夜间模式
- 多个数据源
容器监控搭建
由于整套容器检测需要分别搭建三个Docker容器 , 挨个来比较麻烦, 所以这里使用Docker-compose容器编排, 来进行整体搭建 , Ps:前提服务器环境安装了Docker-compose
准备docker-compose.yml
首先在任意目录创建一个文件夹 , 作为docker-compose.yml 的存放工作目录
## 创建文件夹 cig
mkdir cig 编写docker-compose.yml文件内容
version: '3.1'
volumes:
grafana_data: {}
services:
influxdb:
image: tutum/influxdb:0.9
restart: always
environment:
- PRE_CREATE_DB=cadvisor
ports:
- "8083:8083"
- "8086:8086"
volumes:
- ./data/influxdb:/data
cadvisor:
image: google/cadvisor
links:
- influxdb:influxsrv
command: -storage_driver=influxdb -storage_driver_db=cadvisor -storage_driver_host=influxsrv:8086
restart: always
ports:
- "8080:8080"
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
grafana:
user: "104"
image: grafana/grafana
user: "104"
restart: always
links:
- influxdb:influxsrv
ports:
- "3000:3000"
volumes:
- grafana_data:/var/lib/grafana
environment:
- HTTP_USER=admin
- HTTP_PASS=admin
- INFLUXDB_HOST=influxsrv
- INFLUXDB_PORT=8086
- INFLUXDB_NAME=cadvisor
- INFLUXDB_USER=root
- INFLUXDB_PASS=root
在新创建的目录cig下启动docker-compose 文件
docker-compose up执行以上命令后可以看到开始分别下载这三个容器
创建成功查看三个容器是否都启动
docker ps 
测试启动结果
-
访问 验证cAdvisor收集服务,http://ip:8080/ , cadvisor也有基础的图形展现功能,这里主要用它来作数据采集
-
访问验证 influxdb存储服务,http://ip:8083/ influxDB自己本身也具备可视化图形界面
-
访问验证 grafana展现服务,http://ip:3000 ip+3000端口的方式访问,默认帐户密码(admin/admin)
配置Grafana
配置数据源
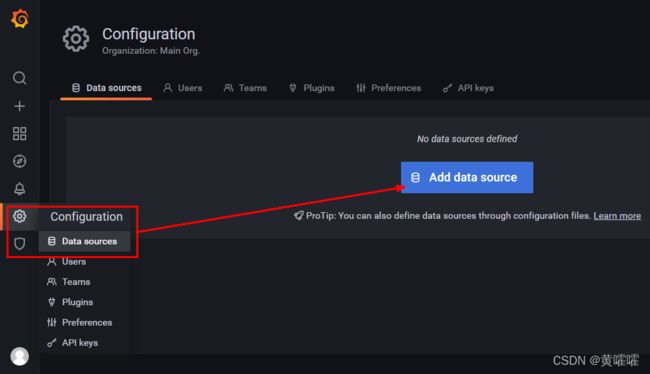
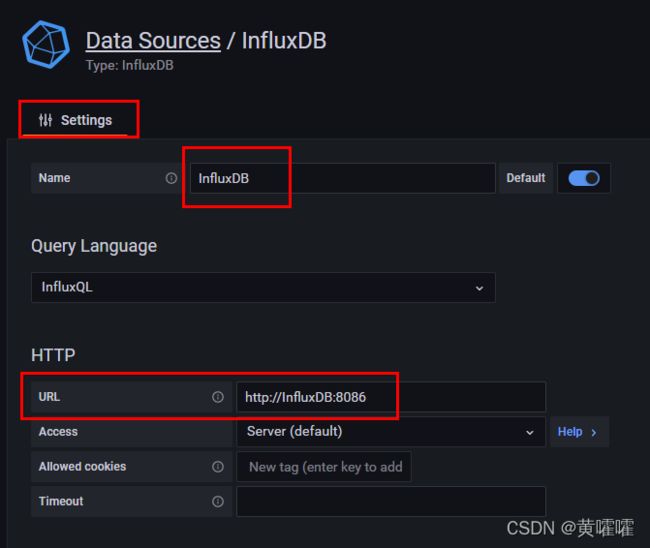
选择InfluxDB数据源
Name不要写死IP , 使用名称即可 , 因为前面的docker-compose 容器编排文件中有配置名称这块 , 且IP有可能随着Docker 的每一次重启而变动
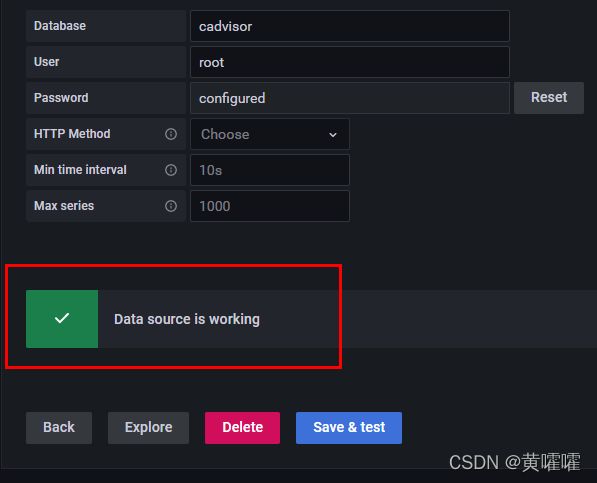
Database 使用cadvisor 同样是因为前面我们在docker-compose文件中有给influxDB初始化了一个数据库, cAdvisor也是将数据写入的该库 , 默认账户密码 root , root 
配置面板

在右侧可以选择各式各样的图形 , 柱状图 , 虚线图等
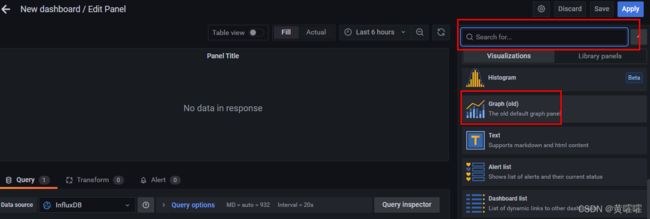
刚创建好的图形里面是没有数据的 , 这时候需要手动配置下数据来源
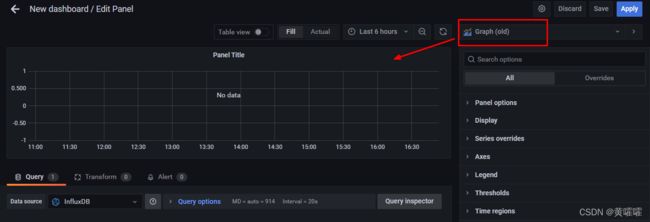
Query一栏里面的配置类似于SQl的选项, default是默认查询那个字段, 后面是筛选条件 , 其他的都不用管 ALIAS 是给这项起个别名, 如果需要一张图展示多个数据项, 可以继续添加查询语句 , B 、C之类的 ,
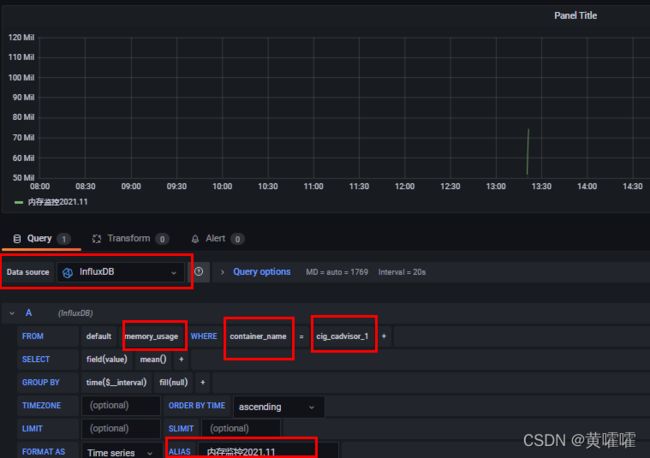
需要注意的一点就是在配置字节类数据(比如网卡接收流量
rx_bytes和 内存使用量memory_usage)的时候单位要选data(IEC)这个类别。
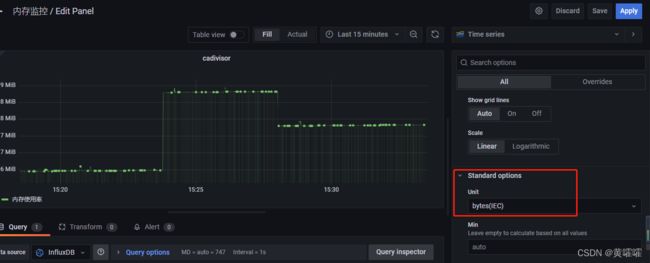
配置完成之后进行保存
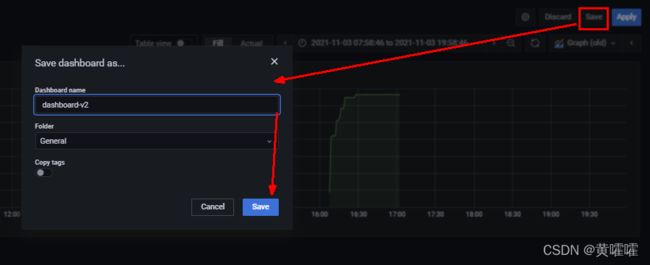
cAdvisor监控指标说明
| 分类 | 字段 | 描述 |
|---|---|---|
| cpu | cpu_usage_total | 总cpu使用率 |
| cpu_usage_system | 系统cpu使用率 | |
| cpu_usage_user | 用户cpu使用率 | |
| cpu_usage_per_cpu | 每个cpu的cpu使用率 | |
| load_average | 可运行线程数 * 1000 的平均值 , Smoothed average of number of runnable threads x 1000 | |
| memory(内存) | memory_usage | 内存使用率 |
| memory_working_set | 内存工作集(工作集下面有解释) | |
| network(网络) | rx_bytes | 累计接受字节数 |
| rx_errors | 累计接受错误次数 | |
| tx_bytes | 累计传输字节数 | |
| tx_errors | 累计传输错误次数 | |
| filesystem(文件系统) | fs_device | 文件系统设备 |
| fs_limit | 文件系统限制 | |
| fs_usage | 文件系统使用率 |
额外知识---名词解释
先进行一下名词解释,其实这个地方容易搞混的一个原因也是不同的工具的描述不一样,导致有些混乱,因此这里先把这些概念统一下,然后再进行解释(WS:Working Set的简称,none:表示无对应的显示选项)。
| Win7任务管理器中名称 | Process Explorer中名称 | VMMap中的名称 |
| 工作设置(内存) | Working Set | Total WS |
| 内存(专用工作集) | WS Private | Private WS |
| 提交大小 | Private Bytes | Private(or Private Bytes) |
| 内存(共享工作集)* | WS Shareable | Shareable WS |
| none | WS Shared | Shared WS |
| none | Virtrual Size | Size |
| none | none | Committed |
*Win10上面有共享工作集的展示
工作设置(内存)/Working Set/Total WS: 专用(私有)工作集(当前进程独占)中的物理内存数量与进程正在使用且可以和其他进程共享的物理内存数量的总和,因此可以这么理解,该值就是该进程所占用的总的物理内存,但是这个值是由两部分组成,即"专用工作集"和"共享工作集"(Win10的任务管理器里面可以看到共享工作集)。在深入解析Windows操作系统里面是这样描述的:物理上驻留在内存中的那一部分子集称为工作集(Working Set)。
峰值工作设置(内存): 进程的工作设置(内存)的最值,可以这么理解,因为工作设置(内存)是波动的,这个项专门记录最大的那个值。
内存(专用工作集)/WS Private/ Private WS: 工作集的子集,它专门描述某个进程正在使用且无法与其他进程共享的物理内存值。这个值对于一个进程来说也是最重要的,它代表了一个进程到底独占了多少物理内存。
内存(共享工作集)/ WS Shareable/ Shareable WS: 进程和可以和别的进程共享的物理内存值(注意:是可以共享的,不一定共享了)。比较常见的,譬如,加载系统的一些DLL所占用的物理内存,文件共享内存(文件映射),命名共享内存等等。
WS Shared/ Shared WS: WS Shareable的子集,这部分是表示已经和别的进程共享的物理内存。
提交大小/ Private Bytes/ Private: 给当前进程使用而保留的私有虚拟内存的数量,从名字里面的Private可以看出它是专有的,但是和上面的WS Private的区别在于,WS Private是纯物理内存,而Private Bytes实际上是虚拟内存的概念,是包含WS Private的,另外一部分是在换页文件(被从物理内存里面换出去了)里面,有些内存,虽然你提交,但是如果一直没有使用,也是在页面文件(换页文件:PageFile)里面。另外,多说一句,如果要查内存泄漏,可以关注这个值。
Virtrual Size/Size: 当前进程使用的所有的虚拟内存空间,包含共享,非共享,物理,页面,甚至为程序保留但还未分配的内存。
Committed: Virtual Size减去为程序保留的内存(未分配)。怎么理解为程序保留的但未分配的内存?就是告诉系统我要一块内存,但暂时还用不上,不过分配的地址得给我,系统就给程序一个不用的地址,但不分配内存,等程序真的要使用时(读写),就从页面或物理内存中分配出来映射到那个地址上。
保留(预定)的内存: 将虚拟内存空间中线性地址0xXXXXXXXX-0xYYYYYYYY标记为预定状态,但是并没有分配实际的内存。这样的好处是我先预定一部分线性地址,以免后面进程空间中没有这么大的地址范围可用(一般来讲只有服务器上面这样用得多)。这样预定后,0xXXXXXXXX-0xYYYYYYYY这块地址就被占用,地址空间也是资源,虽然还没有分配任何内存。
提交的内存: 系统从物理内存或者换页内存分配给进程的那一部分。这部分内存在虚拟内存的线性地址中是连续的,不过在物理内存或者换页内存中,不一定是连续的。提交但未使用的内存一般都在换页内存里面,只有去使用的时候,才会换到物理内存里面,这点要注意。
换页内存: 也属于已经提交的内存,不过因为不常用,可能被系统置换到磁盘上面以节省物理内存,后面如果要使用会发生换页错误(缺页中断),再从磁盘上面置换到物理内存。
缺页中断: 当程序要访问某个地址,系统发现这个地址不在物理内存里,就会产生中断,然后去读取页面文件,把页面文件中与内存相关的数据拷贝到物理内存,然后标记一下这个地址已经在物理内存中了,然后继续让程序运行。
虚拟内存、物理内存和换页内存: (整个概念还是有一些复杂,这里只简单描述一下)虚拟内存一般是指整个进程用到的(虚拟)地址空间,之所以是虚拟的,因为中间被系统内存管理器抽象了一层,说到这里就牵涉到一个进程的虚拟内存空间的问题,win32下面一般应用层的虚拟地址空间是2G,然后从虚拟内存地址到物理内存有一个映射关系,这个映射是由内存管理器来完成的,对应用程序透明。而虚拟内存里面一般分成保留内存(压根就还没分配的,只是占了地址空间的坑),物理内存(正在使用)和换页内存(从物理内存换出去的,或者分配后一直未使用),另外物理内存和换页内存都属于已经提交的内存。
分页池: 由内核或驱动程序代表进程分配的可分页内核内存的数量。可分页内存是可以写入其他存储媒介(例如硬盘)的内存。
非分页缓冲池: 由内核或驱动程序代表进程分配的不可分页的内核内存的数量。不可分页的内存是不能写入其他存储媒介的内存。内核在处理低优先级的中断时,仍可以发生(处理)高优先级的中断,反过来则不行。缺页过程也是一个中断过程(缺页中断),那么就遇到了一个问题,即缺页中断和其他中断的优先级的问题。如果在高于缺页中断的中断优先级上再发生缺页中断,内核就会崩溃。所以在DISPATCH_LEVEL级别以上,绝对不能使用分页内存,一旦使用分页内存,就有发生缺页中断的可能,如果发生就会导致内核崩溃(蓝屏)。
简单总结下:
1、工作设置(内存),又叫工作集,即在物理内存中的数据的集合且等于专用工作集与共享工作集的和,Working Set = WS Private + WS Sharable。
2、把所有的"工作集"相加后的值会大于任务管理器中提示的物理内存的使用值,因为工作集包含了共享工作集,这部分数据会重复计算。但是如果你只把专用工作集全部加起来又会发现小于任务管理器中提示的物理内存的使用值,因为你完全没有计算共享工作集。
3、通俗的讲工作设置(内存)是程序占用的物理内存(包含与其他程序共享的一部分),内存专用工作集是程序独占的物理内存,提交大小(Private Bytes)是程序独占的内存(包含物理内存和换页内存)。
4、Committed = VM Private Committed + VM Shareable Committed(VM:虚拟内存)
5、Committed = Working Set + Page File Committed
6、Private Bytes = WS Private + Page File Private