kafka 消息队列
kafka 消息队列
kafka 架构原理
大数据时代来临,如果你还不知道Kafka那就真的out了!据统计,有三分之一的世界财富500强企业正在使用Kafka,包括所有TOP10旅游公司,7家TOP10银行,8家TOP10保险公司,9家TOP10电信公司等等。LinkedIn、Microsoft和Netflix每天都用Kafka处理万亿级的信息。本文就让我们一起来大白话kafka的架构原理。
kafka官网:http://kafka.apache.org/
01 kafka简介
Kafka最初由Linkedin公司开发,是一个分布式的、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常用于web/nginx日志、访问日志、消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
02 kafka的特性
-
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒;
-
可扩展性:kafka集群支持热扩展;
-
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止丢失;
-
容错性:允许集群中的节点失败(若分区副本数量为n,则允许n-1个节点失败);
-
高并发:单机可支持数千个客户端同时读写;
03 kafka的应用场景
-
日志收集:一个公司可以用Kafka收集各种服务的log,通过kafka以统一接口开放给各种消费端,例如hadoop、Hbase、Solr等。
-
消息系统:解耦生产者和消费者、缓存消息等。
-
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索记录、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
-
运营指标:Kafka也经常用来记录运营监控数据。
-
流式处理
04 kafka架构(重头戏!)
下面是一个kafka的架构图,

整体来看,kafka架构中包含四大组件:生产者、消费者、kafka集群、zookeeper集群。对照上面的结构图,我们先来搞清楚几个很重要的术语,(看图!对照图理解~)
1、broker
kafka 集群包含一个或多个服务器,每个服务器节点称为一个broker。
2、topic
每条发布到kafka集群的消息都有一个类别,这个类别称为topic,其实就是将消息按照topic来分类,topic就是逻辑上的分类,同一个topic的数据既可以在同一个broker上也可以在不同的broker结点上。
3、partition
分区,每个topic被物理划分为一个或多个分区,每个分区在物理上对应一个文件夹,该文件夹里面存储了这个分区的所有消息和索引文件。在创建topic时可指定parition数量,生产者将消息发送到topic时,消息会根据 分区策略 追加到分区文件的末尾,属于顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)。
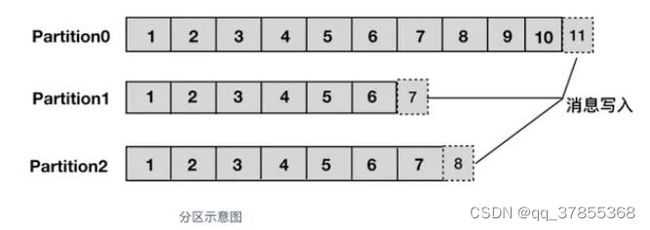
上面提到了分区策略,所谓分区策略就是决定生产者将消息发送到哪个分区的算法。Kafka 为我们提供了默认的分区策略,同时它也支持自定义分区策略。kafka允许为每条消息设置一个key,一旦消息被定义了 Key,那么就可以保证同一个 Key 的所有消息都进入到相同的分区,这种策略属于自定义策略的一种,被称作"按消息key保存策略",或Key-ordering 策略。
同一主题的多个分区可以部署在多个机器上,以此来实现 kafka 的伸缩性。同一partition中的数据是有序的,但topic下的多个partition之间在消费数据时不能保证有序性,在需要严格保证消息顺序消费的场景下,可以将partition数设为1,但这种做法的缺点是降低了吞吐,一般来说,只需要保证每个分区的有序性,再对消息设置key来保证相同key的消息落入同一分区,就可以满足绝大多数的应用。
4、offset
partition中的每条消息都被标记了一个序号,这个序号表示消息在partition中的偏移量,称为offset,每一条消息在partition都有唯一的offset,消息者通过指定offset来指定要消费的消息。
正常情况下,消费者在消费完一条消息后会递增offset,准备去消费下一条消息,但也可以将offset设成一个较小的值,重新消费一些消费过的消息,可见offset是由consumer控制的,consumer想消费哪一条消息就消费哪一条消息,所以kafka broker是无状态的,它不需要标记哪些消息被消费过。
5、producer
生产者,生产者发送消息到指定的topic下,消息再根据分配规则append到某个partition的末尾。
6、consumer
消费者,消费者从topic中消费数据。
7、consumer group
消费者组,每个consumer属于一个特定的consumer group,可为每个consumer指定consumer group,若不指定则属于默认的group。
同一topic的一条消息只能被同一个consumer group内的一个consumer消费,但多个consumer group可同时消费这一消息。这也是kafka用来实现一个topic消息的广播和单播的手段,如果需要实现广播,一个consumer group内只放一个消费者即可,要实现单播,将所有的消费者放到同一个consumer group即可。
用consumer group还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
8、leader
每个partition有多个副本,其中有且仅有一个作为leader,leader会负责所有的客户端读写操作。
9、follower
follower不对外提供服务,只与leader保持数据同步,如果leader失效,则选举一个follower来充当新的leader。当follower与leader挂掉、卡住或者同步太慢,leader会把这个follower从ISR列表中删除,重新创建一个follower。
10、rebalance
同一个consumer group下的多个消费者互相协调消费工作,我们这样想,一个topic分为多个分区,一个consumer group里面的所有消费者合作,一起去消费所订阅的某个topic下的所有分区(每个消费者消费部分分区),kafka会将该topic下的所有分区均匀的分配给consumer group下的每个消费者,如下图,

rebalance表示"重平衡",consumer group内某个消费者挂掉后,其他消费者自动重新分配订阅主题分区的过程,是 Kafka 消费者端实现高可用的重要手段。如下图Consumer Group A中的C2挂掉,C1会接收P1和P2,以达到重新平衡。同样的,当有新消费者加入consumer group,也会触发重平衡操作。
05 对kafka架构的几点解释
- 一个典型的kafka集群中包含若干producer,若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干consumer group,以及一个zookeeper集群。kafka通过zookeeper协调管理kafka集群,选举分区leader,以及在consumer group发生变化时进行rebalance。
- kafka的topic被划分为一个或多个分区,多个分区可以分布在一个或多个broker节点上,同时为了故障容错,每个分区都会复制多个副本,分别位于不同的broker节点,这些分区副本中(不管是leader还是follower都称为分区副本),一个分区副本会作为leader,其余的分区副本作为follower。其中leader负责所有的客户端读写操作,follower不对外提供服务,仅仅从leader上同步数据,当leader出现故障时,其中的一个follower会顶替成为leader,继续对外提供服务。
- 对于传统的MQ而言,已经被消费的消息会从队列中删除,但在Kafka中被消费的消息也不会立马删除,在kafka的server.propertise配置文件中定义了数据的保存时间,当文件到设定的保存时间时才会删除,
# 数据的保存时间(单位:小时,默认为7天)
log.retention.hours=168
因为Kafka读取消息的时间复杂度为O(1),与文件大小无关,所以这里删除过期文件与提高Kafka性能并没有关系,所以选择怎样的删除策略应该考虑磁盘以及具体的需求。
- 点对点模式 VS 发布订阅模式
传统的消息系统中,有两种主要的消息传递模式:点对点模式、发布订阅模式。
①点对点模式
生产者发送消息到queue中,queue支持存在多个消费者,但是对一个消息而言,只可以被一个消费者消费,并且在点对点模式中,已经消费过的消息会从queue中删除不再存储。
②发布订阅模式
生产者将消息发布到topic中,topic可以被多个消费者订阅,且发布到topic的消息会被所有订阅者消费。而kafka就是一种发布订阅模式。
- 消费端 pull 和 push
① push方式:由消息中间件主动地将消息推送给消费者;
优点:优点是不需要消费者额外开启线程监控中间件,节省开销。
缺点:无法适应消费速率不相同的消费者。因为消息的发送速率是broker决定的,而消
费者的处理速度又不尽相同,所以容易造成部分消费者空闲,部分消费者堆积,造成缓
冲区溢出。
② pull方式:由消费者主动向消息中间件拉取消息;
优点:消费端可以按处理能力进行拉取;
缺点:消费端需要另开线程监控中间件,有性能开销;
对于Kafka而言,pull模式更合适。pull模式可简化broker的设计,Consumer可自主控制消费消息的速率,同时Consumer可以自己控制消费方式,既可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
06 开启zookeeper

07 开启 kafka
如果服务挂了,就删掉 kafka-logs 的缓存,重新启动

08 开生产者producer 发送消息
- 使用kafka-topics.bat来创建一个主题。–zookeeper (表示在哪个服务器创建),–replication-factor(表示创建多少个副本),–partitions 1(表示创建一个分区),创建主题名称 test
kafka-topics.bat --create --zookeeper localhost:9092 --replication-factor 1 --partitions 1 --topic test
- 查看
kafka-topics.bat --list ——zookeeper localhost:2181
- 删除
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A3thYPDq-1663024484450)(C:\Users\lyz123\AppData\Roaming\Typora\typora-user-images\image-20220912200532032.png)]
09 开生产者producer 发送消息
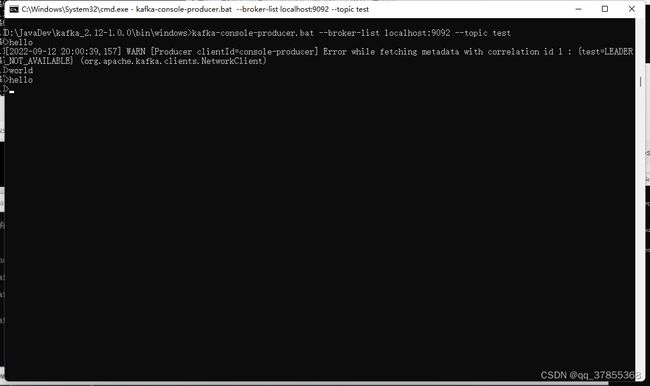
- 调用工具kafka-console-producer.bat
生产者发送信息,–broker-1ist(服务器列表),–topic test(往test这个主题发送消息)
kafka-console-producer.bat --broker-1ist 1ocalhost:9092 --topic test
10 开生产者consumer发送消息
bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning

11 简单代码实现

通过@KafkaKistener 注解来实现的,就是一个kafka的监听器,topics 是复数,监听一个或多个主题。一但监听到有消息,就会调用handleMessage 来处理这个 tipic(主题),会把消息包装成一个ConsumerRecord 传进来,通过record对象来处理。
- 引入依赖
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
<version>2.9.0version>
dependency>
- yaml配置
# KafkaProperties
spring.kafka.bootstrap-servers=localhost:9092
spring.kafka.consumer.group-id=community-consumer-group //kafka的包consumer.properties配置
spring.kafka.consumer.enable-auto-commit=true //是否自动提交消费者的偏移量
spring.kafka.consumer.auto-commit-interval=3000 //自动提交的频率,三千毫秒,3秒
- 代码实现
总之,生产者发消息,是我们主动去调用的,
@RunWith(SpringRunner.class)
@SpringBootTest
@ContextConfiguration(classes = CommunityApplication.class)
public class KafkaTests {
@Autowired
private KafkaProducer kafkaProducer;
@Test
public void testKafka() { //*****阻塞方法,就是等一会才发消息给你,而不是立即发私信
kafkaProducer.sendMessage("test", "你好");
kafkaProducer.sendMessage("test", "在吗");
try {
Thread.sleep(1000 * 10); //时间一过,consumer会自动收到这个消息,调用她修饰的方法
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
@Component
class KafkaProducer { //******生产者
@Autowired
private KafkaTemplate kafkaTemplate; //生产者被spring 整合了
public void sendMessage(String topic, String content) {
kafkaTemplate.send(topic, content);
}
}
@Component //一旦服务启动了,spring就会去监听 topic ,有一个线程会阻塞,一直会尝试读取消息,但是 阻塞的状态,如果没有消息,没有主题她就会阻塞在这里。一旦有了topic(主题),她就会交给她所修饰的这个方法去读取。
class KafkaConsumer { //******消费者
@KafkaListener(topics = {"test"}) //监听的 topic
public void handleMessage(ConsumerRecord record) { //在调取这个方法的时候会对这个消息进行封装,通过record对象,就能读到原始的消息。
System.out.println(record.value());
}
}
12 项目实战

public class Event {
private String topic;
private int userId;
private int entityType;
private int entityId;
private int entityUserId;
private Map<String, Object> data = new HashMap<>();
public String getTopic() {
return topic;
}
public Event setTopic(String topic) {
this.topic = topic;
return this;
}
public int getUserId() {
return userId;
}
public Event setUserId(int userId) {
this.userId = userId;
return this;
}
public int getEntityType() {
return entityType;
}
public Event setEntityType(int entityType) {
this.entityType = entityType;
return this;
}
public int getEntityId() {
return entityId;
}
public Event setEntityId(int entityId) {
this.entityId = entityId;
return this;
}
public int getEntityUserId() {
return entityUserId;
}
public Event setEntityUserId(int entityUserId) {
this.entityUserId = entityUserId;
return this;
}
public Map<String, Object> getData() {
return data;
}
public Event setData(String key, Object value) {
this.data.put(key, value);
return this;
}
}
@Component
public class EventProducer {
@Autowired
private KafkaTemplate kafkaTemplate;
// 处理事件
public void fireEvent(Event event) {
// 将事件发布到指定的主题
kafkaTemplate.send(event.getTopic(), JSONObject.toJSONString(event));
}
}