k8s-部署metrics-server + Prometheus
此为Sunny 王苗苗同学的学习笔记,持续学习,持续分享,持续进步,向着大神之路前进~
Prometheus是一个开源的系统监控和警报工具包,2012年成立后,拥有非常活跃的开发和用户社区,2016年加入CNCF云原生计算基金会,成为继kubernetes后的第二个托管项目。由此可见它的受欢迎程度及重要度。
具体的介绍可看:点这里去官网
中文的介绍:prometheus入门与实践点这里
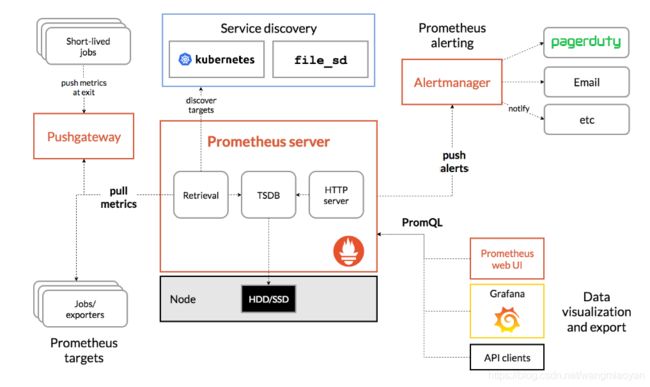
Prometheus Server
Prometheus Server是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储以及查询。
Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标,并从这些监控目标中获取数据。
其次Prometheus Server需要对采集到的监控数据进行存储,PrometheusServer本身就是一个时序数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。
最后PrometheusServer对外提供了自定义的PromQL语言,实现对数据的查询以及分析。
Prometheus Server内置的Express Browser UI,通过这个UI可以直接通过PromQL实现数据的查询以及可视化。
Prometheus Server的联邦集群能力可以使其从其他的Prometheus Server实例中获取数据,因此在大规模监控的情况下,可以通过联邦集群以及功能分区的方式对Prometheus Server进行扩展。
Exporters
Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。
一般来说可以将Exporter分为2类:
(1)直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
(2)间接采集:间接采集,原有监控目标并不直接支持Prometheus,因此我们需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如: Mysql Exporter,JMX Exporter,Consul Exporter等。
AlertManager
在Prometheus Server中支持基于PromQL创建告警规则,如果满足PromQL定义的规则,则会产生一条告警,而告警的后续处理流程则由AlertManager进行管理。
在AlertManager中我们可以与邮件,Slack等等内置的通知方式进行集成,也可以通过Webhook自定义告警处理方式。
AlertManager即Prometheus体系中的告警处理中心。
PushGateway
由于Prometheus数据采集基于Pull模型进行设计,因此在网络环境的配置上必须要让Prometheus Server能够直接与Exporter进行通信。
当这种网络需求无法直接满足时,就可以利用PushGateway来进行中转。
可以通过PushGateway将内部网络的监控数据主动Push到Gateway当中。而Prometheus Server则可以采用同样Pull的方式从PushGateway中获取到监控数据。
部署metrics-server
metrics-server 通过kubelet(cAdvisor)获取监控数据,主要作用是为kube-scheduler,HPA等k8s核心组件,以及kubectl top命令和Dashboard等UI组件提供数据来源。
在新一代的K8S指标监控体系当中主要由核心指标流水线和监控指标流水线组成:
- 核心指标流水线:是指由kubelet、、metrics-server以及由API server提供的api组成;CPU的累积使用率、内存实时使用率,Pod资源占用率以及容器磁盘占用率等等。
- 监控指标流水线:用于从系统收集各种指标数据并提供给终端用户、存储系统以及HPA。它们包含核心指标以及许多非核心指标;由于非核心指标本身不能被K8S解析,此时就需要依赖于用户选择第三方解决方案。
Metrics Server 通过 Kubernetes 聚合 器( kube- aggregator) 注册 到 主 API Server 之上, 而后 基于 kubelet 的 Summary API 收集 每个 节 点上 的 指标 数据, 并将 它们 存储 于 内存 中 然后 以 指标 API 格式 提供,如下图:
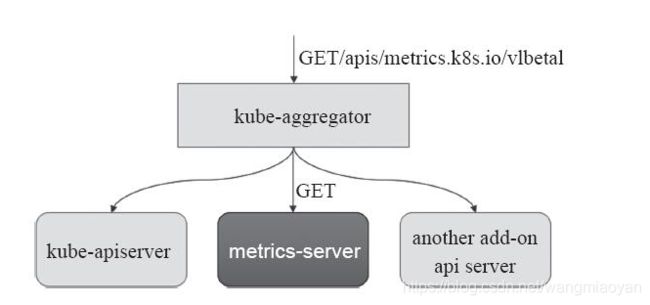
Metrics Server基于 内存 存储, 重 启 后 数据 将 全部 丢失, 而且 它 仅能 留存 最近 收集 到 的 指标 数据, 因此, 如果 用户 期望 访问 历史 数据, 就不 得不 借助于 第三方 的 监控 系统( 如 Prometheus 等)。
下载官方yaml链接
#从官方YAML文件中下载以下文件
[root@k8s-master metrics]# ll
total 24
-rw-r--r-- 1 root root 398 Mar 22 02:52 auth-delegator.yaml
-rw-r--r-- 1 root root 419 Mar 22 02:52 auth-reader.yaml
-rw-r--r-- 1 root root 393 Mar 22 02:53 metrics-apiservice.yaml
-rw-r--r-- 1 root root 2905 Mar 22 03:46 metrics-server-deployment.yaml
-rw-r--r-- 1 root root 336 Mar 22 02:53 metrics-server-service.yaml
-rw-r--r-- 1 root root 817 Mar 22 03:53 resource-reader.yaml
#修改下面这个文件的部分内容
[root@k8s-master metrics]# vim metrics-server-deployment.yaml
#在metrics-server这个容器字段里面修改command为如下:
spec:
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
containers:
- name: metrics-server
image: gcr.azk8s.cn/google-containers/metrics-server-amd64:v0.3.6
command:
- /metrics-server
- --metric-resolution=30s
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP
#再修改metrics-server-nanny容器中的cpu和内存值,如下:
command:
- /pod_nanny
- --config-dir=/etc/config
- --cpu=100m
- --extra-cpu=0.5m
- --memory=100Mi
- --extra-memory=50Mi
- --threshold=5
- --deployment=metrics-server-v0.3.6
- --container=metrics-server
- --poll-period=300000
- --estimator=exponential
- --minClusterSize=10
#由于启动容器还需要权限获取数据,需要在resource-reader.yaml文件中增加nodes/stats
[root@k8s-master metrics]# vim resource-reader.yaml
....
rules:
- apiGroups:
- ""
resources:
- pods
- nodes
- nodes/stats
- namespaces
#部署开始
[root@k8s-master metrics]# kubectl apply -f .
[root@k8s-master metrics]# kubectl api-versions |grep metrics
metrics.k8s.io/v1beta1
#检查资源指标API的可用性
[root@k8s-master metrics]# kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes"
{"kind":"NodeMetricsList","apiVersion":"metrics.k8s.io/v1beta1","metadata":{"selfLink":"/apis/metrics.k8s.io/v1beta1/nodes"},"items":[{"metadata":{"name":"node2","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/node2","creationTimestamp":"2020-09-17T06:42:59Z"},"timestamp":"2020-09-17T06:42:26Z","window":"30s","usage":{"cpu":"848497113n","memory":"8104056Ki"}},{"metadata":{"name":"node3","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/node3","creationTimestamp":"2020-09-17T06:42:59Z"},"timestamp":"2020-09-17T06:42:29Z","window":"30s","usage":{"cpu":"150466856n","memory":"8258904Ki"}},{"metadata":{"name":"node4","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/node4","creationTimestamp":"2020-09-17T06:42:59Z"},"timestamp":"2020-09-17T06:42:29Z","window":"30s","usage":{"cpu":"546942066n","memory":"9709860Ki"}},{"metadata":{"name":"master","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/master","creationTimestamp":"2020-09-17T06:42:59Z"},"timestamp":"2020-09-17T06:42:23Z","window":"30s","usage":{"cpu":"165915399n","memory":"3319660Ki"}},{"metadata":{"name":"master2","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/master2","creationTimestamp":"2020-09-17T06:42:59Z"},"timestamp":"2020-09-17T06:42:23Z","window":"30s","usage":{"cpu":"180315370n","memory":"900140Ki"}},{"metadata":{"name":"master3","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/master3","creationTimestamp":"2020-09-17T06:42:59Z"},"timestamp":"2020-09-17T06:42:27Z","window":"30s","usage":{"cpu":"229123328n","memory":"2658164Ki"}},{"metadata":{"name":"node1","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/node1","creationTimestamp":"2020-09-17T06:42:59Z"},"timestamp":"2020-09-17T06:42:30Z","window":"30s","usage":{"cpu":"189360924n","memory":"6588684Ki"}}]}
#确保Pod对象运行正常
[root@k8s-master metrics]# kubectl get pods -n kube-system |grep metrics
metrics-server-v0.3.6-756f9998f6-l7f6t 2/2 Running 0 152m
以上如果内容没有做修改的话,会出现容器跑不起来一直处于CrashLoopBackOff状态,或者出现权限拒绝的问题。可以通过kubectl logs进行查看相关的日志。下面使用kubectl top命令进行查看资源信息:
[root@k8s-master metrics]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master 142m 3% 3288Mi 20%
master2 165m 4% 967Mi 6%
master3 194m 4% 2681Mi 16%
node1 176m 4% 6413Mi 40%
node2 845m 21% 7832Mi 49%
node3 122m 3% 7972Mi 50%
node4 503m 12% 8795Mi 55%
部署prometheus
参考项目链接https://github.com/iKubernetes/k8s-prom.git
主要包括收集指标的组件node_exporter(节点指标)和kube-state-metrics(K8S资源指标)
核心组件prometheus server以及适配器**k8s-prometheus-adapter【**因为prometheus收集到的指标是符合prometheus的接口风格的,但是这些指标无法直接被K8S读取,所以需要适配器转化一下,将prometheus收集到的资源转变为K8S也能读懂,此处多出一个用户自定义API,custom.metrics】
1、创建名称空间
[root@k8s-master ~]# git clone https://github.com/iKubernetes/k8s-prom.git && cd k8s-prom
[root@k8s-master k8s-prom]# kubectl apply -f namespace.yaml
namespace/prom created
2、部署node_exporter
监控代理程序,收集主机的指标数据,如平均负载、CPU、内存、磁盘、网络等多个维度的指标数据。
[root@k8s-master k8s-prom]# kubectl apply -f node_exporter/
daemonset.apps/prometheus-node-exporter created
service/prometheus-node-exporter created
[root@k8s-master k8s-prom]# kubectl get pods -n prom
NAME READY STATUS RESTARTS AGE
prometheus-node-exporter-2vr8m 1/1 Running 4 9d
prometheus-node-exporter-6mfl5 1/1 Running 1 9d
prometheus-node-exporter-gbp25 1/1 Running 1 9d
prometheus-node-exporter-kknfg 1/1 Running 1 9d
prometheus-node-exporter-l9tv6 1/1 Running 1 9d
prometheus-node-exporter-q7cqh 1/1 Running 1 9d
3、部署prometheus-server
Prometheus组件中的核心部分,负责实现对监控数据的获取,存储以及查询
[root@k8s-master k8s-prom]# kubectl apply -f prometheus/
configmap/prometheus-config created
deployment.apps/prometheus-server created
clusterrole.rbac.authorization.k8s.io/prometheus created
serviceaccount/prometheus created
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
service/prometheus created
4、部署kube-sate-metrics
收集K8S资源指标,轮询Kubernetes API,并将Kubernetes的结构化信息转换为metrics
[root@k8s-master k8s-prom]# kubectl apply -f kube-state-metrics/
deployment.apps/kube-state-metrics created
serviceaccount/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
service/kube-state-metrics created
5、制作证书
[root@k8s-master k8s-prom]# cd /etc/kubernetes/pki/
[root@k8s-master pki]# (umask 077; openssl genrsa -out serving.key 2048)
Generating RSA private key, 2048 bit long modulus
......................+++
....+++
e is 65537 (0x10001)
[root@k8s-master pki]# openssl req -new -key serving.key -out serving.csr -subj "/CN=serving"
[root@k8s-master pki]# openssl x509 -req -in serving.csr -CA ./ca.crt -CAkey ./ca.key -CAcreateserial -out serving.crt -days 3650
Signature ok
subject=/CN=serving
Getting CA Private Key
[root@k8s-master pki]# kubectl create secret generic cm-adapter-serving-certs --from-file=serving.crt=./serving.crt --from-file=serving.key -n prom
secret/cm-adapter-serving-certs created
[root@k8s-master pki]# kubectl get secret -n prom
NAME TYPE DATA AGE
cm-adapter-serving-certs Opaque 2 9d
6、部署k8s-prometheus-adapter
用户自定义metrics API,用于将prometheus收集到的指标转化为K8S可读懂指标
这里自带的custom-metrics-apiserver-deployment.yaml和custom-metrics-config-map.yaml有点问题,需要下载k8s-prometheus-adapter项目中的这2个文件
[root@k8s-master k8s-prometheus-adapter]# wget https://raw.githubusercontent.com/DirectXMan12/k8s-prometheus-adapter/master/deploy/manifests/custom-metrics-apiserver-deployment.yaml
[root@k8s-master k8s-prometheus-adapter]# vim k8s-prometheus-adapter/custom-metrics-apiserver-deployment.yaml #修改名称空间为prom
[root@k8s-master k8s-prometheus-adapter]# wget https://raw.githubusercontent.com/DirectXMan12/k8s-prometheus-adapter/master/deploy/manifests/custom-metrics-config-map.yaml #也需要修改名称空间为prom
[root@k8s-master k8s-prom]# kubectl apply -f k8s-prometheus-adapter/
clusterrolebinding.rbac.authorization.k8s.io/custom-metrics:system:auth-delegator created
rolebinding.rbac.authorization.k8s.io/custom-metrics-auth-reader created
deployment.apps/custom-metrics-apiserver created
clusterrolebinding.rbac.authorization.k8s.io/custom-metrics-resource-reader created
serviceaccount/custom-metrics-apiserver created
service/custom-metrics-apiserver created
apiservice.apiregistration.k8s.io/v1beta1.custom.metrics.k8s.io created
clusterrole.rbac.authorization.k8s.io/custom-metrics-server-resources created
clusterrole.rbac.authorization.k8s.io/custom-metrics-resource-reader created
clusterrolebinding.rbac.authorization.k8s.io/hpa-controller-custom-metrics created
configmap/adapter-config created
[root@k8s-master k8s-prom]# kubectl api-versions |grep custom
custom.metrics.k8s.io/v1beta1
访问172.31.17.51:30090,查看prometheus的UI界面

可以看到上面图表不太好看,我们可以部署grafana,可视化指标
7、部署grafana
apiVersion: apps/v1
kind: Deployment
metadata:
name: monitoring-grafana
namespace: prom
spec:
replicas: 1
selector:
matchLabels:
task: monitoring
k8s-app: grafana
template:
metadata:
labels:
task: monitoring
k8s-app: grafana
spec:
containers:
- name: grafana
image: tianyong/heapster-grafana-amd64:v5.0.4
ports:
- containerPort: 3000
protocol: TCP
volumeMounts:
- mountPath: /etc/ssl/certs
name: ca-certificates
readOnly: true
- mountPath: /var
name: grafana-storage
env:
#- name: INFLUXDB_HOST
# value: monitoring-influxdb
- name: GF_SERVER_HTTP_PORT
value: "3000"
# The following env variables are required to make Grafana accessible via
# the kubernetes api-server proxy. On production clusters, we recommend
# removing these env variables, setup auth for grafana, and expose the grafana
# service using a LoadBalancer or a public IP.
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
# If you're only using the API Server proxy, set this value instead:
# value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
value: /
volumes:
- name: ca-certificates
hostPath:
path: /etc/ssl/certs
- name: grafana-storage
emptyDir: {}
# nfs:
# path: /home/ttebdadmin/nfs/data/grafana
# server: vol
---
apiVersion: v1
kind: Service
metadata:
labels:
# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)
# If you are NOT using this as an addon, you should comment out this line.
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: monitoring-grafana
name: monitoring-grafana
namespace: prom
spec:
# In a production setup, we recommend accessing Grafana through an external Loadbalancer
# or through a public IP.
# type: LoadBalancer
# You could also use NodePort to expose the service at a randomly-generated port
# type: NodePort
ports:
- port: 80
targetPort: 3000
nodePort: 31191
type: NodePort
selector:
k8s-app: grafana
[root@k8s-master k8s-prom]# kubectl apply -f grafana.yaml
deployment.apps/monitoring-grafana created
service/monitoring-grafana created
[root@k8s-master k8s-prom]# kubectl get all -n prom
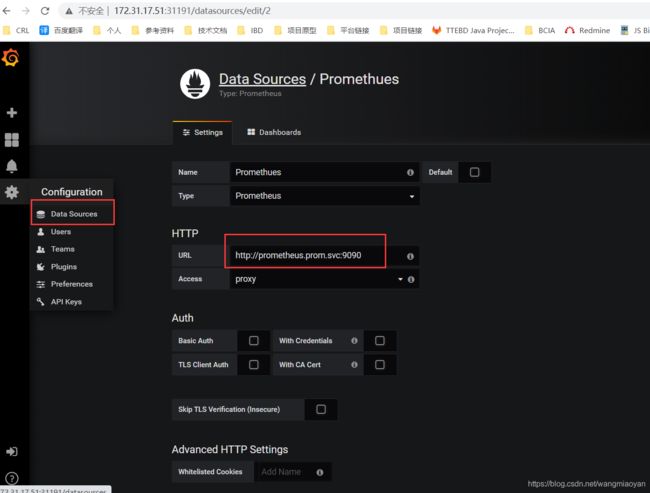
访问grafana界面 172.31.17.51:31191
先添加数据源 http://prometheus.prom.svc:9090
去到grafana下载kubernetes模板,地址:https://grafana.com/grafana/dashboards?search=kubernetes
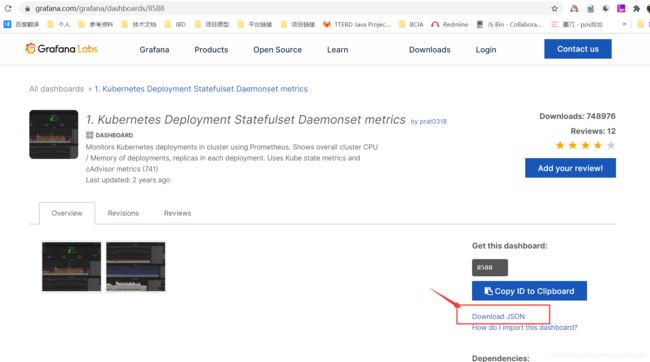
8、给grafana添加json模板
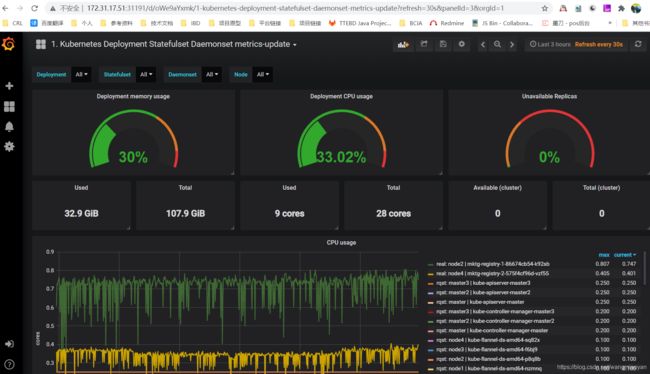
注意: Kubernetes 1.16 以后不再使用 pod_name 和 container_name 标签,解决办法是下载 grafana dashboard 的 json 文件,将里面的 pod_name 和 container_name 全部替换为 pod 和 container ,再在你的 grafana 里面导入这个 json 文件就好了。
参考资料:
Kubernetes学习之路(二十三)之资源指标和集群监控
Kubernetes学习之路(二十四)之Prometheus监控
Prometheus组件介绍
解决 Grafana 只能显示 pod_name 和 container_name 而没有具体的名字问题