【论文速递】CVPR2022 - MeMOT: 带有记忆得到多目标跟踪
【论文速递】CVPR2022 - MeMOT: 带有记忆得到多目标跟踪
【论文原文】:MeMOT: Multi-Object Tracking with Memory
论文地址:https://arxiv.org/abs/2203.16761
博主关键词: 多目标跟踪,transformer,memory
推荐相关论文:
【论文速递】ECCV2022 - ByteTrack:通过关联每个检测盒来进行多对象跟踪
- https://blog.csdn.net/Never_moresf/article/details/128719534
【论文速递】CVPR2022 - 全局跟踪Transformers
-https://blog.csdn.net/Never_moresf/article/details/128704693
摘要:
我们提出了一种在线跟踪算法,该算法在一个通用框架下执行目标检测和数据关联,能够在长时间跨度后连接对象。这是通过保留一个大的时空内存来存储被跟踪对象的 identity embeddings,并根据需要自适应地引用和聚合内存中的有用信息。我们的模型被称为MeMOT,由三个主要模块组成,它们都是基于transformer的:1)假设生成(Hypothesis Generation),在当前视频帧中产生目标proposals;2)记忆编码(Memory Encoding),从内存中提取每个被跟踪对象的核心信息;3)内存解码(Memory Decoding),同时解决多目标跟踪的目标检测和数据关联任务。在广泛采用的MOT benchmark数据集上进行评估时,MeMOT展示了非常有竞争力的性能。
关键词 多目标跟踪,transformer,memory
简介:
在线多目标跟踪(MOT)[3,13,57,70]的目标是定位一组目标(例如,行人),同时跟踪它们随时间变化的轨迹,使同一个的目标在整个输入视频流中具有相同的id。早期的方法大多通过两个独立的阶段来解决这个问题:1)目标检测阶段: 在单独帧[14,17,28,42,72]中检测目标实例;2)数据关联阶段,通过对跟踪目标的状态变化建模,解决跟踪目标与检测结果之间的匹配问题,将检测到的目标实例跨时间[5,70]关联。尽管最近的研究[34,69]表明,将这两个阶段结合起来可能是有益的,但这种结合通常会导致关联模块在建模对象随时间变化时的过度简化。
在本文中,我们提出了一种基于transformer的跟踪模型,称为MeMOT,该模型在在线的公共框架下执行目标检测和关联。MeMOT的关键设计是建立一个大型时空存储器,存储被跟踪目标的过去观测数据。通过引用相关信息,在每一时间步中对memory进行主动编码,以使得目标的状态更准确地逼近关联任务。从时空存储器中提取的跟踪对象的丰富表示使我们能够在一个统一的解码模块中解决目标检测和关联任务。它直接输出已被跟踪并在最新帧中重新出现的目标,以及第一次看到的新目标实例。MeMOT的思想如图1所示。
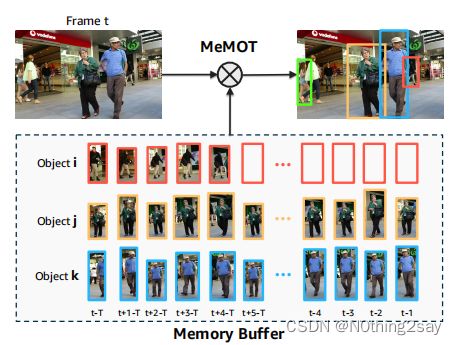
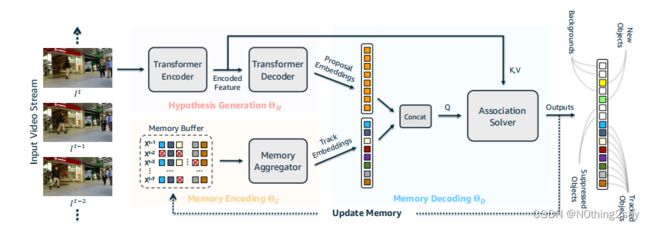
在每个时间步长中,MeMOT运行以下三个主要组件:1)假设生成模块,该模块从输入图像特征图中生成proposals,作为一组嵌入向量;2))记忆编码模块,该模块将与每个被跟踪对象对应的时空记忆编码为称为跟踪嵌入的向量;3)内存解码,输入proposal和跟踪嵌入,同时解决多目标跟踪的目标检测和数据关联任务。假设生成模块由一个基于transformer的编解码器网络[6,73]实现。它生成一组嵌入向量,称为proposal embedding,每个向量表示一个假设的目标实例。记忆编码模块首先将每个目标的时空记忆分为短期记忆和长期记忆,并通过交叉注意模块[50]将它们聚合成一个嵌入向量。然后,两个向量通过自注意机制相互作用,在此时间步生成被跟踪目标的轨迹嵌入。proposal和轨道嵌入,与原始图像特征一起,然后送到内存解码模块。对于每个轨迹嵌入,它生成在这一帧中被跟踪对象的位置和可见性。对于每个proposal嵌入,它预测这个假设的对象实例是描绘一个新对象、一个跟踪对象,还是仅仅是一个背景区域。MeMOT模型的示意图如图2所示。整个模型可以在带有对象包围框和身份标注的视频数据集上进行端到端训练。在推理过程中,我们在每个时间步的一次模型推理中获得跟踪输出,无需任何额外的优化[9,41]或后处理[3,48,70]。
我们评估了MeMOT在MOT Challenge[10,35] benchmark上的行人跟踪结果。实验结果表明,MeMOT在所有使用网络内关联算法中达到了最先进的性能,并且与使用网络后关联过程的算法相比具有竞争力。具体来说,MeMOT在目标检测和数据关联方面都优于其他基于transformer的方法。广泛的消融研究进一步验证了MeMOT的设计和有效性。
【社区访问】
 【论文速递 | 精选】
【论文速递 | 精选】
 阅读原文访问社区
阅读原文访问社区
https://bbs.csdn.net/forums/paper